【层级多标签文本分类】基于预训练语言模型的BERT-CNN多层级专利分类研究
基于预训练语言模型的BERT-CNN多层级专利分类研究
1、背景
1、作者(第一作者和通讯作者)
陆晓蕾,倪斌
2、单位
厦门大学,中国科学院计算技术研究所厦门数据智能研究院
3、年份
2020
4、来源
中文信息学报
2、四个问题
1、要解决什么问题?
实现专利多层文本分类
2、用了什么方法解决?
提出了基于预训练语言模型的BERT-CNN多层级专利分类模型
3、效果如何?
该模型在准确率上达到了84.3%,大幅优于CNN、RNN等其他深度学习算法。
4、还存在什么问题?
文章没有解决多标签问题、未将模型扩展到更深层级的分类中。
论文笔记
0、引言
作者在引言部分介绍了近年来,工业界和学术界产生了大量专利申请。现行《国际专利分类法》包含 “部—类—亚 类—组”四个层级,其中“组”级共含有7万多种类别,人工太难分辨,所以提出用神经网络来分类。
注:专利分类作为文本分类中的一个垂直领域,标签有多层级、多标签的特点,不像做新闻分类、情感分类很多时候标签单一、且简单、都是自定义的。所以专利分类写论文更有“点”可写。
1、相关研究
此小节论述了文本分类的综述,从机器学习到神经网络到词向量、Elmo、GPT、Transformer、BERT。
最后提出BERT也是有缺点的。“虽然BERT提供了下游任务的简单接口,可以直接进行文本分类。然而,BERT作为预训练语言模型,关于其作为文档向量的研究和应用尚不多见。”
然后说fastText可以做文档向量,效果也不错,但是它使用的是word embedding,不能解决语义(多义词)问题。
最后的idea就是把BERT与fastText结合。
2、研究方法
2.1、BERT-CNN 模型结构
2.1.1、BERT层
BERT采用双向Transformer编码器,利用多头注意力机制融合了上下文信息。与早期通过训练语言模型的目标任务———“预测下一个词”不同的是,BERT设置了两种目标任务,分别获取单词与句子级别的表义方式:
①遮盖语言模型:随机遮盖15%的句子,让编码器预测这些词;
②上下句关系预测:通过预测两个随机句子能否组成上下句来学习句子间的关系。
本文选取BERT-Base作为预训练模型。BERT-Base拥有12个Transforme层,本文中的BERT-CNN采用BERT后四层的输出作为下游CNN模型的输入。
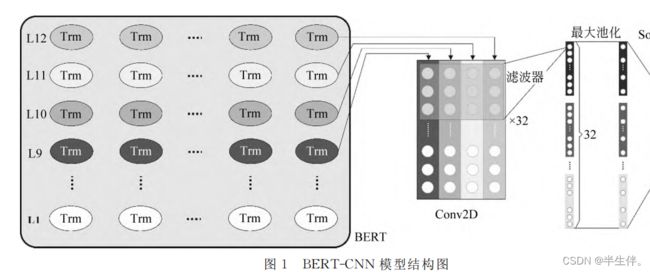
2.1.2、Conv2D层
本文取BERT最后四层作为CNN的输入矩阵I(768 x 4)。然后用32个滤波器F(3×4),步长为1,扫描输入矩阵I,目的是提取文本3-Gram特征,通过I⊗F 内积获得32个特征向量。为了降低计算的复杂度,CNN通常使用池化计算降低矩阵的维度。本文选取最大池化方式。
2.2、多层文本分类架构
多层文本分类其主要特点在于多层文本分类需要考虑的类别巨大,类别之间 往往存在各种依赖关系,并构成一个复杂的层次化的类别体系。
目前处理该类问题一般有两种策略
全局策略:全局策略在处理多层级任务时没有区分层级,使用单一的分类器,完全忽略类别间的层次结构,这在处理类别有限并且样本分布均衡的任务时简单有效。但是随着层级、类别的增加,数据分布的不均衡,其鲁棒性变低。
局部策略:局部策略利用分治的思想,构建一系列分类器,每个分类器只处理局部的类别。分类时,从分类体系的根节点出发,自顶向下确定样本的分类。(本文采用的局部策略)
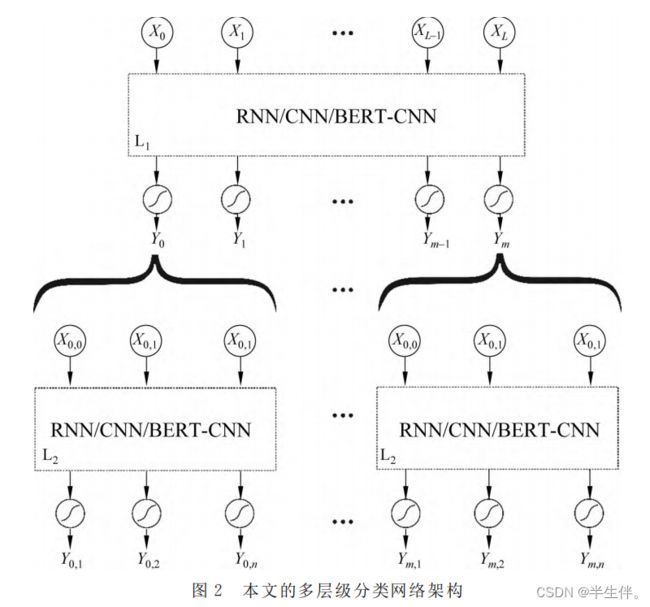
作者在本文中提供了一种处理标签有层级关系的文本分类办法。
首先对所有数据、一级标签进行分类;之后依次对所有归类为一级标签A的数据、一级标签A的子标签进行分类,对所有归类为一级标签B的数据、一级标签B的子标签进行分类,对所有归类为一级标签…的数据、一级标签…的子标签进行分类。
3、实验与结果
3.1、数据集
数据集采用国家信息中心提供的全国专利申请数据 。数据总量达到277万条记录。时间跨度为2017年全年(按照专利申请时间统计),地域覆盖全国。
3.3、结果分析与讨论
3.3.1、评估指标
本文模型使用正确率作为评估指标,最终联合模型的正确率 Acc(X)通过式(1)计算:
3.3.2、实验结果

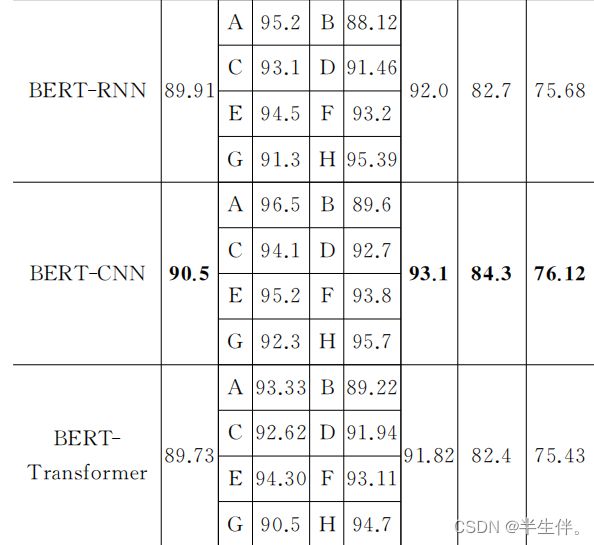
从实验结果可以看到在各个模型上,前者的准确率均高于后者。证实了作者所提出模型在文本分类的功能。
3.3.3、其他数据集
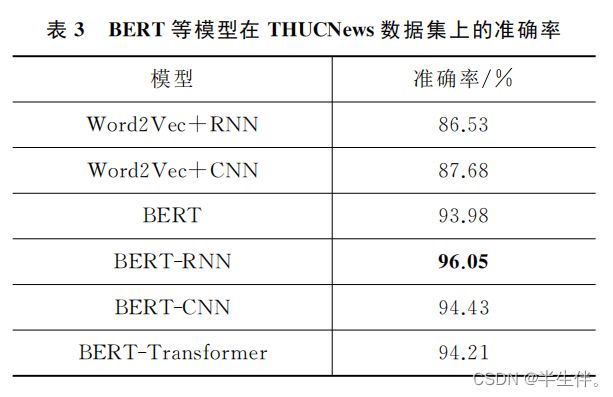
为了 进 一 步 证 实BERT-CNN/RNN/Transformer等模型的效果,本文选取清华大学自然语言处理实验室开源的新闻文本分类数据集进行平照实验。
3.3.4、讨论
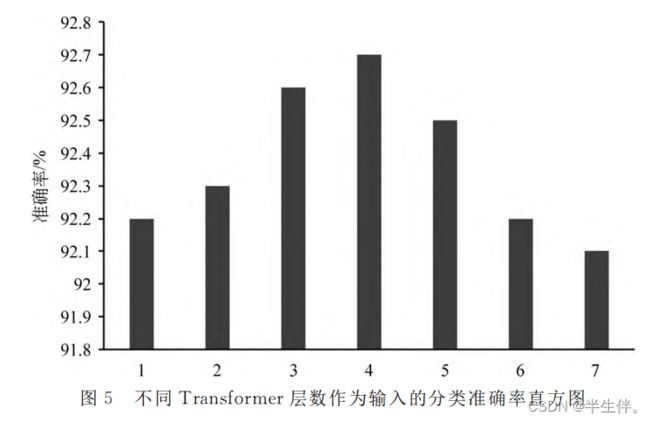
模型的准确率在Transformer层数N=4时达到最大。当N<4时Transformer的输出作为文档向量的代表性还不太强,准确率略有下降;当N>4 时,文档向量中表征词汇语法关系的成分增大,对分类结果意义不大,反而造成干扰,导致准确率下降。
本文参考:https://comdy.blog.csdn.net/article/details/122683419