语义分割系列论文-Fully Convolutional Networks for Semantic Segmentation(FCN)
目录
图像分类&语义分割
CNN&FCN
FCN改变了什么?
FCN结构
上采样
逐像素预测
FCN的缺点
总结
FCN论文地址:https://arxiv.org/abs/1411.4038
FCN开源代码:https://github.com/shelhamer/fcn.berkeleyvision.org
图像分类&语义分割
图像分类:图像级别,判断一幅图像中包含什么类别的物体。

语义分割:像素级别,判断一副图像中哪些像素属于哪个类别。
CNN&FCN
CNN已经在图像分类方面取得了巨大的成就,涌现出如VGG、Resnet等网络结构,并在ImageNet中取得了好成绩。CNN的强大之处在于它的多层结构能自动学习特征,并且可以学习到多个层次的特征:
较浅的卷层层感知域较小,学习到一些局部区域的特征;
较深的卷积层具有较大的感知域,能够学习到更加抽象一些的特征。
这些抽象特征对物体的大小、位置和方向等敏感性更低,从而有助于分类性能的提高。这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体。图像分类是图像级别的!
与分类不同的是,语义分割需要判断图像每个像素点的类别,进行精确分割。图像语义分割时像素级别的!但是由于CNN在进行convolution和Pooling过程中丢失了图像细节,即feature map size 逐渐变小,所以不能很好的指出物体的具体轮廓、指出每个像素具体属于哪个物体,无法做到精确的分割。
针对这个问题,Jonathan Long等人提出了Fully Convolutional Networks(FCN)用于图像语义分割。自从提出后,FCN已经成为语义分割的基本框架,后续算法其实都是在这个框架中改进而来。
FCN改变了什么?
一、不含全连接层(fc)的全卷积网络(fully conv),可适应任意尺寸的输入;
二、增大数据尺寸的反卷积层(deconv),能够输出精细的结果。
三、结合不同深度层结果的跳级结构(skip),同时确保鲁棒性和精确性。
对于一般的分类CNN网络,如VGG和Resnet,都会在网络的最后加入一些全连接层,经过softmax后就可以获得类别概率信息。但是这个概率信息是1维的,即只能标识整个图片的类别,不能标识每个像素点的类别,所以采用全连接的方式不适用于图像分割。

而FCN提出,可以把后面的几个全连接层都换成卷积层,这样就可以获得一张二维的feature map,后接softmax获得每个像素点分类信息,从而解决分割问题。
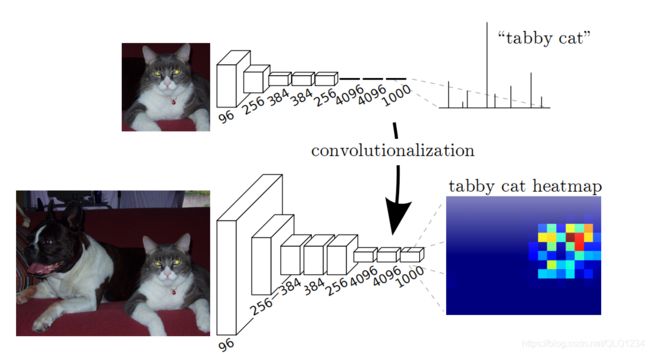
以下图为例进行说明:
在传统CNN结构中,前5层卷积层,第6层、第7层分别是一个长度为4096的一维向量,第8层是长度为1000的一维向量,分别对应1000个类别概率。
而FCN将最后一层全连接层换成卷积层,输出一张已经预测好的图。
FCN结构
FCN结构分析:
-
Image经过多个conv+一个max pooling变为pool1 feature,宽高变为1/2
-
pool1 feature再经过多个conv+一个max pooling变为pool2 feature,宽高变为1/4
-
pool2 feature再经过多个conv+一个max pooling变为pool3 feature,宽高变为1/8
-
......
-
直到pool5 feature,宽高变为1/32。
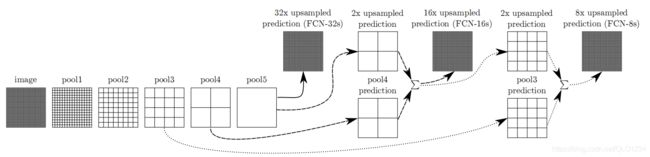
FCN各个结构对比::
-
FCN-32s:直接对pool5 feature进行32倍上采样获得32x upsampled feature,再对32x upsampled feature每个点做softmax prediction获得32x upsampled feature prediction(即分割图)。
-
FCN-16s:首先对pool5 feature进行2倍上采样获得2x upsampled feature,再把pool4 feature和2x upsampled feature逐点相加,然后对相加的feature进行16倍上采样,并softmax prediction,获得16x upsampled feature prediction。
-
FCN-8s:首先对pool5 feature进行2倍上采样获得2x upsampled feature,然后把pool4与2x upsampled feature逐点相加,相加后在进行2倍上采样,将结果与pool3进行逐点相加,即进行更多次特征融合。
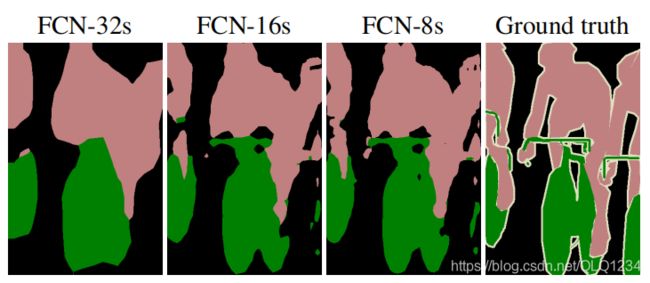
三种网络结构的分割效果对比:FCN-32s < FCN-16s < FCN-8s , 即使用多层feature融合有利于提高分割准确性。
上采样
上采样一般包括两种方式:
-
Resize,如双线性插值直接缩放,类似于图像缩放(这种方法在原文中提到)
-
Deconvolution,也叫Transposed Convolution。
Deconvolution(反卷积)解释:
对于一般卷积,输入蓝色4x4矩阵,卷积核大小3x3。当设置卷积参数pad=0,stride=1时,卷积输出绿色2x2矩阵。
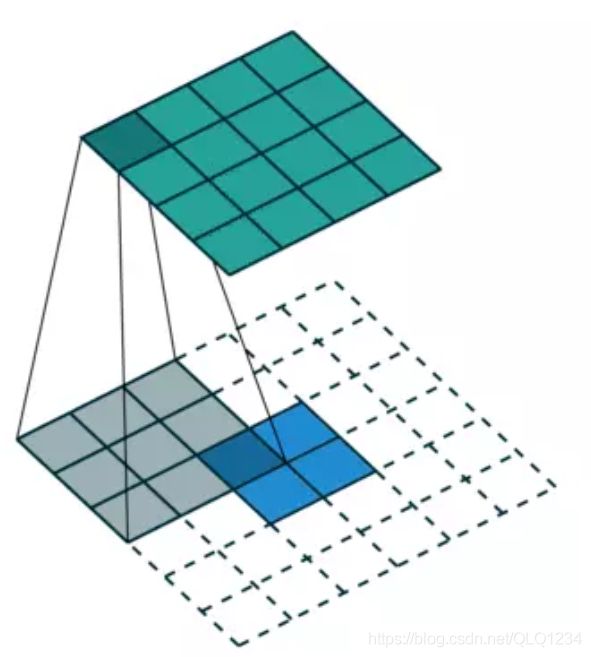
而对于Deconvolution(反卷积),相当于把普通卷积反过来,输入蓝色2*2矩阵,卷积核大小3*3。当设置反卷积参数pad=0,stride=1时输出绿色4*4矩阵。相当于倒过来。
传统的网络是subsampling的,对应的输出尺寸会降低;upsampling的意义在于将小尺寸的高维度feature map恢复回去,以便做pixelwise prediction,获得每个点的分类信息。
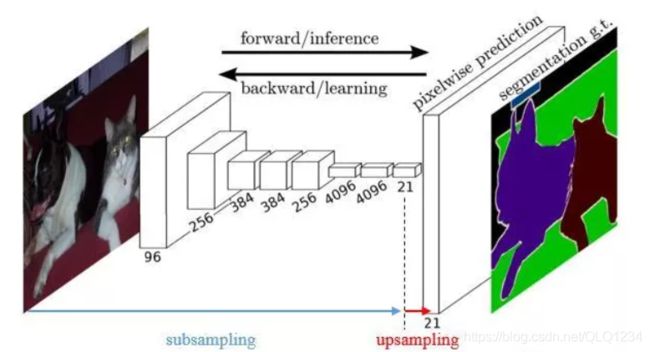
上采样的作用如上图所示,先对图像进行subsampling输出特征图。对特征图在进行upsampling(上采样)后恢复了较大的pixelwse feature map(其中最后一层21-dim是因为pascal数据集有20个类别+背景),相当于是enconder-Deconder.
逐像素预测
CNN中输入的图像大小是同意固定resize成 227x227 大小的图像,第一层pooling后为55x55,第二层pooling后图像大小为27x27,第五层pooling后的图像大小为13*13。而FCN输入的图像是H*W大小,第一层pooling后变为原图大小的1/4,第二层变为原图大小的1/8,第五层变为原图大小的1/16,第八层变为原图大小的1/32(勘误:其实真正代码当中第一层是1/2,以此类推)。
经过多次卷积和pooling以后,得到的图像越来越小,分辨率越来越低。其中图像到 H/32∗W/32 的时候图片是最小的一层时,所产生图叫做heatmap热图,热图就是我们最重要的高维特诊图,得到高维特征的heatmap之后就是最重要的一步也是最后的一步对原图像进行upsampling,把图像进行放大、放大、放大,到原图像的大小。
最后的输出是1000张heatmap经过upsampling变为原图大小的图片,为了对每个像素进行分类预测label成最后已经进行语义分割的图像,这里有一个小trick,就是最后通过逐个像素地求其在1000张图像该像素位置的最大数值描述(概率)作为该像素的分类。因此产生了一张已经分类好的图片。
FCN的缺点
-
是得到的结果还是不够精细。进行8倍上采样虽然比32倍的效果好了很多,但是上采样的结果还是比较模糊和平滑,对图像中的细节不敏感。
-
是对各个像素进行分类,没有充分考虑像素与像素之间的关系。忽略了在通常的基于像素分类的分割方法中使用的空间规整(spatial regularization)步骤,缺乏空间一致性。
总结
CNN图像语义分割也就基本上是这个套路:
-
下采样+上采样:Convlution + Deconvlution/Resize
-
多尺度特征融合:特征逐点相加/特征channel维度拼接
-
获得像素级别的segement map:对每一个像素点进行判断类别
参考:
博客1 :https://www.cnblogs.com/gujianhan/p/6030639.html
博客2 :https://blog.csdn.net/qq_36269513/article/details/80420363