【百战GAN】如何使用GAN给黑白老照片上色?
大家好,欢迎来到专栏《百战GAN》,在这个专栏里,我们会进行GAN相关项目的核心思想讲解,代码的详解,模型的训练和测试等内容。
作者&编辑 | 言有三

本文资源与生成结果展示
本文篇幅:7000字
背景要求:会使用Python和Pytorch
附带资料:参考论文和项目
1 项目背景
自从GAN技术发展以来,许多新奇的应用都得到了落地,本次我们来介绍其中一个小应用,就是黑白图像上色。想必大家在网上经常看到一些给黑白图像上色的视频,可以修复早期的黑白影像,背后的技术就是GAN,下面的动图就是我们本次项目实战的案例图,对人像、照片、建筑图进行上色。
实现上述效果的算法不是唯一的,各有各的优缺点,本次我们来给大家剖析其中的一种核心技术!
2 原理简介
本次我们来实现基于Pix2Pix的黑白图片上色,Pix2Pix是一个通用的框架,可以适用于任何的图像翻译类任务,下面我们首先来介绍其原理。

它的生成器和判别器的输入都不是噪声,而是真实的图片。输入图x经过生成器G之后得到生成图片G(x),然后一边将G(x)和x一起作为判别器的输入,另一边将真实标注y和x一起作为判别器的输入,前者判别器输出为fake,后者为real。
G就是一个常见的编解码结构,D就是一个普通分类器,那这样的生成式框架有什么优势呢?
作者们认为,一般的编解码结构可以解决低频成分的生成,但是高频的细节不够理想,而GAN则擅长解决高频成分的生成。总的生成器损失函数为一个标准的条件GAN损失加上L1重建损失,分别定义如下:

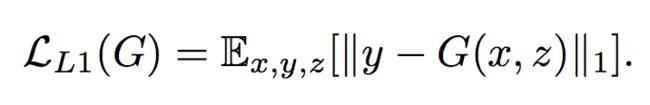
具体到网络结构,生成器使用了UNet结构,这是一个很通用的图像分割模型。
而判别器则使用了PatchGAN,因为GAN只用于生成高频信息,就不需要将整张图片输入到判别器中,而是对图像的每个大小为NxN的图像块(patch)做真假判别就可以了,这就是所谓的PatchGAN。论文对比了不同大小patch的结果,对于256x256的输入,patch大小在70x70的时候与整张图片作为判别器输入差别不明显,如下图就是不同patch大小的判别器下的生成结果。

具体实现我们看接下来的代码。
3 图像上色实战
本次我们进行了3种图像的上色任务实践,分别是人像图、植物图,建筑图。
人像上色任务采用了一个高清的人脸数据集Celeba-HQ,该数据集发布于2019年,包含30000张包括不同属性的高清人脸图,其中图像大小均为1024×1024。

植物上色任务采用了公开数据集Oxford 102 Flowers Dataset,该数据集发布于2008年,包含102 个类别,共计 102 种花,其中每个类别包含 40 到 258 张图像。

建筑上色任务数据集来自于爬虫从搜索引擎与摄影网站的爬取,最终获得了8564张图。

接下来我们对代码进行解读:
3.1 数据预处理
对于图像上色任务来说,在CIELab颜色空间比在RGB颜色空间会有更好的效果,因为CIELab颜色空间中的L通道只有灰度信息,而a和b通道只有颜色信息,实现了亮度与颜色的分离。
下图展示了CIELab颜色中的颜色分布,相比于其他彩色空间,有更加线性和均匀的分布特性。

因此,在数据读取模块中,需要将RGB图像转换到CIELab颜色空间,然后构建成对的数据。下面我们来查看数据读取类中的核心功能函数,包括初始化函数__init__与数据迭代器__getitem__。
## 数据类定义如下
class ColorizationDataset(BaseDataset):
def __init__(self, opt):
BaseDataset.__init__(self, opt)
self.dir = os.path.join(opt.dataroot, opt.phase)
self.AB_paths = sorted(make_dataset(self.dir, opt.max_dataset_size))
assert(opt.input_nc == 1 and opt.output_nc == 2 and opt.direction == 'AtoB')
self.transform = get_transform(self.opt, convert=False)
def __getitem__(self, index):
path = self.AB_paths[index]
im = Image.open(path).convert('RGB') ## 读取RGB图
im = self.transform(im) ## 进行预处理
im = np.array(im)
lab = color.rgb2lab(im).astype(np.float32) ## 将RGB图转换为CIELab图
lab_t = transforms.ToTensor()(lab)
L = lab_t[[0], ...] / 50.0 - 1.0 ## 将L通道(index=0)数值归一化到-1到1之间
AB = lab_t[[1, 2], ...] / 110.0 ## 将A,B通道(index=1,2)数值归一化到0到1之间
return {'A': L, 'B': AB, 'A_paths': path, 'B_paths': path}
在上面的__getitem__函数中,首先使用了PIL包读取图片,然后将其预处理后转换到CIELab空间中。读取后的L通道的数值范围是在0~100之间,通过处理后归一化到-1和1之间。读取后的A和B的通道的数值范围是在0~110之间,通过处理后归一化到0和1之间。
另外在__init__函数中进行了预处理,调用了get_transform函数,它主要包含了图像缩放,随机裁剪,随机翻转,减均值除以方差等操作,由于是比较通用的操作,这里不再对关键代码进行解读。
3.2 生成器网络
生成器使用的是U-Net结构,在该开源框架中也还可以选择残差结构,不过我们使用U-Net完成实验任务
## UNet生成器定义如下
class UnetGenerator(nn.Module):
def __init__(self, input_nc, output_nc, num_downs, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False):
super(UnetGenerator, self).__init__()
unet_block = UnetSkipConnectionBlock(ngf*8,ngf*8, input_nc=None, submodule=None, norm_layer=norm_layer, innermost=True) # add the innermost layer
for i in range(num_downs - 5):
unet_block=UnetSkipConnectionBlock(ngf*8,ngf*8,input_nc=None, submodule=unet_block, norm_layer=norm_layer, use_dropout=use_dropout)
## 逐步减小通道数,从ngf * 8到ngf
unet_block=UnetSkipConnectionBlock(ngf*4,ngf*8,input_nc=None, submodule=unet_block, norm_layer=norm_layer)
unet_block=UnetSkipConnectionBlock(ngf*2,ngf*4,input_nc=None, submodule=unet_block, norm_layer=norm_layer)
unet_block=UnetSkipConnectionBlock(ngf,ngf*2,input_nc=None, submodule=unet_block, norm_layer=norm_layer)
self.model=UnetSkipConnectionBlock(output_nc,ngf,input_nc=input_nc, submodule=unet_block, outermost=True, norm_layer=norm_layer) ## 最外层
def forward(self, input):
"""Standard forward"""
return self.model(input)
其中重要参数解释如下:input_nc 是输入通道,output_nc是输出通道,num_downs 是降采样次数,为2^num_downs,ngf是最后一层通道数,norm_layer是归一化层。
UnetSkipConnectionBlock是跳层连接的模块,它的定义如下:
class UnetSkipConnectionBlock(nn.Module):
def __init__(self, outer_nc, inner_nc, input_nc=None,
submodule=None,outermost=False,innermost=False, norm_layer=nn.BatchNorm2d, use_dropout=False):
super(UnetSkipConnectionBlock, self).__init__()
self.outermost = outermost
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
if input_nc is None:
input_nc = outer_nc
downconv = nn.Conv2d(input_nc, inner_nc, kernel_size=4,
stride=2, padding=1, bias=use_bias)
downrelu = nn.LeakyReLU(0.2, True)
downnorm = norm_layer(inner_nc)
uprelu = nn.ReLU(True)
upnorm = norm_layer(outer_nc)
if outermost:
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
kernel_size=4, stride=2,
padding=1)
down = [downconv]
up = [uprelu, upconv, nn.Tanh()]
model = down + [submodule] + up
elif innermost:
upconv = nn.ConvTranspose2d(inner_nc, outer_nc,
kernel_size=4, stride=2,
padding=1, bias=use_bias)
down = [downrelu, downconv]
up = [uprelu, upconv, upnorm]
model = down + up
else:
upconv = nn.ConvTranspose2d(inner_nc * 2, outer_nc,
kernel_size=4, stride=2,
padding=1, bias=use_bias)
down = [downrelu, downconv, downnorm]
up = [uprelu, upconv, upnorm]
##是否使用dropout
if use_dropout:
model = down + [submodule] + up + [nn.Dropout(0.5)]
else:
model = down + [submodule] + up
self.model = nn.Sequential(*model)
def forward(self, x):
if self.outermost:#最外层直接输出
return self.model(x)
else:#添加跳层
return torch.cat([x, self.model(x)], 1)
其中outer_nc是外层通道数,inner_nc是内层通道数,input_nc是输入通道数,submodule即前一个子模块,outermost判断是否是最外层,innermost判断是否是最内层,norm_layer即归一化层,user_dropout即是否使用dropout。
对于pix2pix模型,使用的归一化层默认为nn.BatchNorm2d,当batch=1时,它实际上与InstanceNorm等价。
3.3 判别器定义
接下来我们再看判别器的定义,判别器是一个分类模型,不过在前面我们说了,它的输入不是整张图片,而是图像块,因此判别器的输出不是单独的一个数,而是多个图像块的概率图,最终将其相加得到完整的概率,定义如下:
## PatchGAN的定义如下
class NLayerDiscriminator(nn.Module):
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial: ##判断归一化层类别,如果是BN则不需要bias
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4 ##卷积核大小
padw = 1 ##填充大小
## 第一个卷积层
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
nf_mult = 1
nf_mult_prev = 1
## 中间2个卷积层
for n in range(1, n_layers): ##逐渐增加通道宽度,每次扩充为原来两倍
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8)
## 第五个卷积层
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
## 输出单通道预测结果图
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)]
self.model = nn.Sequential(*sequence)
def forward(self, input):
return self.model(input)
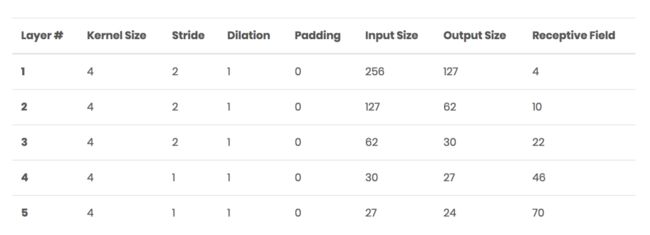
其中input_nc是输入图通道,ndf是最后一个卷积层通道,n_layers是判别器层数,norm_layer是归一化层类型。从代码可以看出,默认包括了5层卷积,其中卷积核大小都为4*4,前面3层的stride=2,后两个卷积层的stride=1,总的感受野为70*70,这也是前面所说的实际上是取70*70的块的原因,各层输入输出以及感受野统计情况如下:
3.4 损失函数定义
接下来我们再看损失函数的定义。
class GANLoss(nn.Module):
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
#gan_model,损失类型,支持原始损失,lsgan,wgangp
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)
#将标签转为与预测结果图同样大小
def get_target_tensor(self, prediction, target_is_real):
if target_is_real:
target_tensor = self.real_label
else:
target_tensor = self.fake_label
return target_tensor.expand_as(prediction)
##返回损失
def __call__(self, prediction, target_is_real):
if self.gan_mode in ['lsgan', 'vanilla']:
target_tensor = self.get_target_tensor(prediction, target_is_real)
loss = self.loss(prediction, target_tensor)
elif self.gan_mode == 'wgangp':
if target_is_real:
loss = -prediction.mean()
else:
loss = prediction.mean()
return loss
以上代码实现了对几种常见的GAN对抗损失的计算。
3.5 完整结构定义
定义好判别器和生成器之后,我们来看完整的pix2pix模型的定义,如下:
class Pix2PixModel(BaseModel):
##配置默认参数
def modify_commandline_options(parser, is_train=True):
##默认使用batchnorm,网络结构为unet_256,使用成对的(aligned)图片数据集
parser.set_defaults(norm='batch', netG='unet_256', dataset_mode='aligned')
if is_train:
parser.set_defaults(pool_size=0, gan_mode='vanilla')#使用经典GAN损失
parser.add_argument('--lambda_L1', type=float, default=100.0, help='weight for L1 loss')#L1损失权重为100
def __init__(self, opt):
BaseModel.__init__(self, opt)
self.loss_names = ['G_GAN', 'G_L1', 'D_real', 'D_fake'] ##损失
self.visual_names = ['real_A', 'fake_B', 'real_B'] ##中间结果图
if self.isTrain:
self.model_names = ['G', 'D']
else: # during test time, only load G
self.model_names = ['G']
#生成器和判别器定义
self.netG = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm,not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
# 判别器定义,输入RGB图和生成器图的拼接
if self.isTrain:
self.netD = networks.define_D(opt.input_nc + opt.output_nc, opt.ndf, opt.netD, opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain:
#损失函数定义,GAN标准损失和L1重建损失
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device)
self.criterionL1 = torch.nn.L1Loss()
# 优化器,使用Adam
self.optimizer_G = torch.optim.Adam(self.netG.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizer_D = torch.optim.Adam(self.netD.parameters(), lr=opt.lr, betas=(opt.beta1, 0.999))
self.optimizers.append(self.optimizer_G)
self.optimizers.append(self.optimizer_D)
def set_input(self, input):
## 输入预处理,根据不同方向进行A,B的设置
AtoB = self.opt.direction == 'AtoB'
self.real_A = input['A' if AtoB else 'B'].to(self.device)
self.real_B = input['B' if AtoB else 'A'].to(self.device)
self.image_paths = input['A_paths' if AtoB else 'B_paths']
# 生成器前向传播
def forward(self):
self.fake_B = self.netG(self.real_A) #G(A)
# 判别器损失
def backward_D(self):
#假样本损失
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
pred_fake = self.netD(fake_AB.detach())
self.loss_D_fake = self.criterionGAN(pred_fake, False)
#真样本损失
real_AB = torch.cat((self.real_A, self.real_B), 1)
pred_real = self.netD(real_AB)
self.loss_D_real = self.criterionGAN(pred_real, True)
#真样本和假样本损失平均
self.loss_D = (self.loss_D_fake + self.loss_D_real) * 0.5
self.loss_D.backward()
# 生成器损失
def backward_G(self):
# GAN损失
fake_AB = torch.cat((self.real_A, self.fake_B), 1)
pred_fake = self.netD(fake_AB)
self.loss_G_GAN = self.criterionGAN(pred_fake, True)
#重建损失
self.loss_G_L1 = self.criterionL1(self.fake_B, self.real_B) * self.opt.lambda_L1
#损失加权平均
self.loss_G = self.loss_G_GAN + self.loss_G_L1
self.loss_G.backward()
def optimize_parameters(self):
self.forward() # 计算G(A)
# 更新D
self.set_requires_grad(self.netD, True) #D
self.optimizer_D.zero_grad() #D梯度清零
self.backward_D() #计算 D梯度
self.optimizer_D.step() #更新D权重
# 更新G
self.set_requires_grad(self.netD, False) #优化G时无须迭代D
self.optimizer_G.zero_grad() # G梯度清零
self.backward_G() # 计算 G梯度
self.optimizer_G.step() #更新G权重
以上就完成了工程中核心代码的解读,接下来我们对模型进行训练和测试。
3.6 模型训练
模型训练就是完成模型定义,数据载入,可视化以及存储等工作,核心代码如下:
if __name__ == '__main__':
opt = TrainOptions().parse() #获取一些训练参数
dataset = create_dataset(opt) #创建数据集
dataset_size = len(dataset) #数据集大小
print('The number of training images = %d' % dataset_size)
model = create_model(opt) #创建模型
model.setup(opt) #模型初始化
visualizer = Visualizer(opt) #可视化函数
total_iters = 0 #迭代batch次数
for epoch in range(opt.epoch_count, opt.niter + opt.niter_decay + 1):
epoch_iter = 0 #当前epoch迭代batch数
for i, data in enumerate(dataset): #每一个epoch内层循环
visualizer.reset()
total_iters += opt.batch_size #总迭代batch数
epoch_iter += opt.batch_size
model.set_input(data) #输入数据
model.optimize_parameters() #迭代更新
if total_iters % opt.display_freq == 0: #visdom可视化
save_result = total_iters % opt.update_html_freq == 0
model.compute_visuals()
visualizer.display_current_results(model.get_current_visuals(), epoch, save_result)
if total_iters % opt.print_freq == 0: #存储损失等信息
losses = model.get_current_losses()
visualizer.print_current_losses(epoch, epoch_iter, losses, t_comp, t_data)
if opt.display_id > 0:
visualizer.plot_current_losses(epoch, float(epoch_iter) / dataset_size, losses)
if total_iters % opt.save_latest_freq == 0: #存储模型
print('saving the latest model (epoch %d, total_iters %d)' % (epoch, total_iters))
save_suffix = 'iter_%d' % total_iters if opt.save_by_iter else 'latest'
model.save_networks(save_suffix)
if epoch % opt.save_epoch_freq == 0: #每隔opt.save_epoch_freq各epoch存储模型
model.save_networks('latest')
model.save_networks(epoch)
model.update_learning_rate()#每一个epoch后更新学习率
其中的一些重要训练参数配置如下:
input_nc=1,表示生成器输入为1通道图像,即L通道。
output_nc=2,表示生成器输出为2通道图像,即AB通道。
ngf=64,表示生成器最后1个卷积层输出通道为64。
ndf=64,表示判别器最后1个卷积层输出通道为64。
n_layers_D=3,表示使用默认的PatchGAN,它相当于对70×70大小的图像块进行判别。
norm=batch,batch_size=1,表示使用批次标准化。
load_size=286,表示载入的图像尺寸。
crop_size=256,表示图像裁剪即训练尺寸。
3.7 模型测试
当然,实际用的时候,我们希望使用自己的图片来完成测试,完整的代码如下:
import os
from PIL import Image
import torchvision.transforms as transforms
import cv2
import numpy as np
import torch
from models.networks import define_G
model_path = "checkpoints/portraits_pix2pix/latest_net_G.pth"
# 配置相关参数
input_nc = 3
output_nc = 3
ngf = 64
netG = 'unet_256'
norm = 'batch'
modelG = define_G(input_nc, output_nc, ngf, netG, norm,True)
params = torch.load(model_path,map_location='cpu') #载入模型
modelG.load_state_dict(params)
if __name__ == '__main__':
imagedir = "myimages"
imagepaths = os.listdir(imagedir)
## 预处理函数
transform_list = []
transform_list.append(transforms.Resize((256,256),Image.BICUBIC))
transform_list += [transforms.ToTensor()]
transform_list += [transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]
transform = transforms.Compose(transform_list)
for imagepath in imagepaths:
img = Image.open(os.path.join(imagedir,imagepath))
img = img.convert('RGB')
img = transform(img)
img = np.array(img)
lab = color.rgb2lab(img).astype(np.float32)
lab_t = transforms.ToTensor()(lab)
L = lab_t[[0], ...] / 50.0 - 1.0
L = L.unsqueeze(0)
AB = modelG(L)
AB2 = AB * 110.0
L2 = (L + 1.0) * 50.0
Lab = torch.cat([L2, AB2], dim=1)
Lab = Lab[0].data.cpu().float().numpy()
Lab = np.transpose(Lab.astype(np.float64), (1, 2, 0))
rgb = (color.lab2rgb(Lab) * 255).astype(np.uint8)
在上述代码中,由于训练的时候使用的Batchsize=1,所以我们测试时并不使用存储的batchsize参数,即没有打开modelG.eval()选项,读者可以自行体验其中的差距。
将RGB图像读取后,首先转换到CIELab空间,然后将L通道输入生成器,获得上色结果。人像图,植物图,建筑图的结果分别如下图所示。



图中第一排RGB图像为输入生成器的L通道图,第二排则是真实的RGB图像,第三排则是模型上色的结果。其中输入图都不在训练集中,人脸图都是通过StyleGAN生成,植物图和建筑图的一部分来自于笔者拍摄,一部分随机取自于验证集。
从以上三幅图的结果可以看出,虽然上色的结果和原始RGB图像的颜色并不完全一致,但是3类图像都获得了比较真实的上色效果。人脸的肤色、建筑图的天空、植物的主体,都没有出现明显违反先验常识的颜色,说明模型的确学习到了目标的语义信息。
所有测试图,都获得了局部和全局平滑的上色风格,没有出现明显的不连续的暇疵,对于一些比较困难的测试图也获得了比较不错的效果。如植物图中的第2幅,主体和背景都是黄色,上色结果虽然没有和原图一致,但是主体的上色结构一致性非常好,而背景则有更丰富的颜色分布。建筑图的第6幅,输入RGB图像也是单色风格图,上色结果很好地保持了风格,没有出现不连续的颜色瑕疵,验证了该模型的鲁棒性。
本文参考资料如下:
[1] Isola P, Zhu J Y, Zhou T, et al. Image-to-image translation with conditional adversarial networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1125-1134.
本文视频讲解和代码,请大家移步
【项目实战课】基于Pytorch的Pix2Pix黑白图片上色实战


总结
本次我们使用有监督的Pix2Pix图像翻译框架完成了几类常见图像的上色任务,验证了模型在图像上色任务中的实际效果,还有一些实验可供感兴趣的读者进行拓展实践,比如比较RGB空间与LAB空间的效果,欢迎大家以后持续关注《百战GAN专栏》。
如何系统性地学习生成对抗网络GAN
欢迎大家关注有三AI-CV秋季划GAN小组,可以系统性学习GAN相关的内容,包括GAN的基础理论,《深度学习之图像生成GAN:理论与实践篇》,《深度学习之图像翻译GAN:理论与实践篇》以及各类GAN任务的实战。
介绍如下:【CV秋季划】生成对抗网络GAN有哪些研究和应用,如何循序渐进地学习好(2022年言有三一对一辅导)?

转载文章请后台联系
侵权必究



【CV夏季划】2022年正式入夏,从理论到实践,如何系统性进阶CV?(产学研一体的超硬核培养方式)
【CV秋季划】模型算法与落地很重要,如何循序渐进地学习好(2022年言有三一对一辅导)?
【CV秋季划】人脸算法那么多,如何循序渐进地学习好?
【CV秋季划】图像质量提升与编辑有哪些研究和应用,如何循序渐进地学习好?
【CV冬季划】终极进阶,超30个项目实战+3本书+3年知识星球