SVM深入理解&人脸特征提取
文章目录
- 第一章 SVM
-
-
- 一、SVM算法
-
- 1. 基于线性核函数
- 2. 基于多项式核
- 3. 基于高斯核
- 三、重做例子代码
- 参考文献
-
- 第二章 人脸特征提取
-
-
- 一、打开摄像头,实时采集人脸并保存、绘制68个特征点
- 二、人脸虚拟P上一付墨镜
- 参考文献
-
第一章 SVM
一、SVM算法
1.支持向量机(Support Vector Machine,常简称为SVM)是一种监督式学习的方法,可广泛地应用于统计分类以及回归分析。
2.它是将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面,分隔超平面使两个平行超平面的距离最大化。假定平行超平面间的距离或差距越大,分类器的总误差越小。
二、基于SVM处理月亮数据集分类
代码准备
import numpy as np
from matplotlib.colors import ListedColormap
def plot_decision_boundary(model,axis):
x0,x1=np.meshgrid(
np.linspace(axis[0],axis[1],int((axis[1]-axis[0])*100)).reshape(-1,1),
np.linspace(axis[2],axis[3],int((axis[3]-axis[2])*100)).reshape(-1,1))
x_new=np.c_[x0.ravel(),x1.ravel()]
y_predict=model.predict(x_new)
zz=y_predict.reshape(x0.shape)
custom_cmap=ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0,x1,zz,cmap=custom_cmap)
生成测试数据
from sklearn import datasets
data_x,data_y = datasets.make_moons(n_samples=100, shuffle=True, noise=0.1, random_state=None)
数据预处理
from sklearn.preprocessing import StandardScaler
scaler=StandardScaler()
data_x = scaler.fit_transform(data_x)
可视化样本集
import matplotlib.pyplot as plt
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1])
plt.scatter(data_x[data_y==1,0],data_x[data_y==1,1])
plt.show()
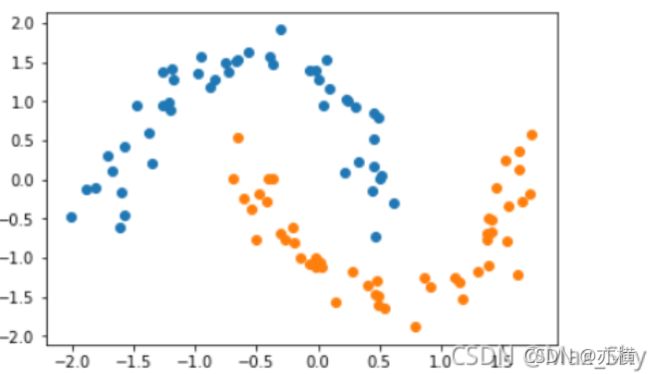
1. 基于线性核函数
from sklearn.svm import LinearSVC
liner_svc=LinearSVC(C=1e9,max_iter=100000)
liner_svc.fit(data_x,data_y)
plot_decision_boundary(liner_svc,axis=[-3,3,-3,3])
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1],color='red')
plt.scatter(data_x[data_y==1,0],data_x[data_y==1,1],color='blue')
plt.show()
print('参数权重')
print(liner_svc.coef_)
print('模型截距')
print(liner_svc.intercept_)

2. 基于多项式核
from sklearn.preprocessing import PolynomialFeatures
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,c=10):
'''
:param d:阶数
:param C:正则化常数
:return:一个Pipeline实例
'''
return Pipeline([
("poly_features", PolynomialFeatures(degree=degree)),
("scaler", StandardScaler()),
("svm_clf", LinearSVC(C=10, loss="hinge", random_state=42,max_iter=10000))
])
poly_svc=PolynomialSVC(degree=3)
poly_svc.fit(data_x,data_y)
plot_decision_boundary(poly_svc,axis=[-3,3,-3,3])
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1],color='red')
plt.scatter(data_x[data_y==1,0],data_x[data_y==1,1],color='blue')
plt.show()
print('参数权重')
print(poly_svc.named_steps['svm_clf'].coef_)
print('模型截距')
print(poly_svc.named_steps['svm_clf'].intercept_)
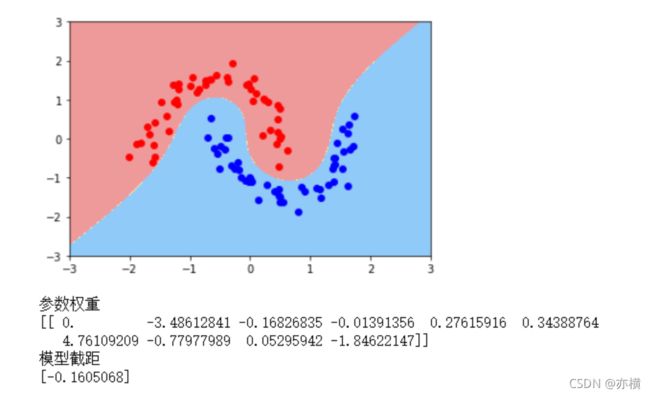
3. 基于高斯核
from sklearn.svm import SVC
def RBFKernelSVC(gamma=1.0):
return Pipeline([
('std_scaler',StandardScaler()),
('svc',SVC(kernel='rbf',gamma=gamma))
])
svc=RBFKernelSVC(gamma=4)
svc.fit(data_x,data_y)
plot_decision_boundary(svc,axis=[-3,3,-3,3])
plt.scatter(data_x[data_y==0,0],data_x[data_y==0,1],color='red')
plt.scatter(data_x[data_y==1,0],data_x[data_y==1,1],color='blue')
plt.show()

三、重做例子代码
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris=datasets.load_iris()
X=iris.data
y=iris.target
X=X[y< 2,:2]#只取y<2的类别,也就是0 1 并且只取前两个特征
y=y[y< 2]# 只取y<2的类别
# 分别画出类别0和1的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
# 标准化
standardScaler=StandardScaler()
standardScaler.fit(X)#计算训练数据的均值和方差
X_standard=standardScaler.transform(X)#再用scaler中的均值和方差来转换X,使X标准化
svc=LinearSVC(C=1e9)#线性SVM分类器
svc.fit(X_standard,y)#训练svm

import matplotlib.pyplot as plt
import numpy as np
import sklearn
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris=datasets.load_iris()
X=iris.data
y=iris.target
X=X[y<2,:2]#只取y<2的类别,也就是0 1 并且只取前两个特征
y=y[y<2]# 只取y<2的类别
# 分别画出类别0和1的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
standardScaler=StandardScaler()
standardScaler.fit(X)#计算训练数据的均值和方差
X_standard=standardScaler.transform(X)#再用scaler中的均值和方差来转换X,使X标准化
svc2=LinearSVC(C=0.01)#分类器
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3])# x,y轴都在-3到3之间
#绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()

svc2=LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3])# x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()

# 接下来我们看下如何处理非线性的数据。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
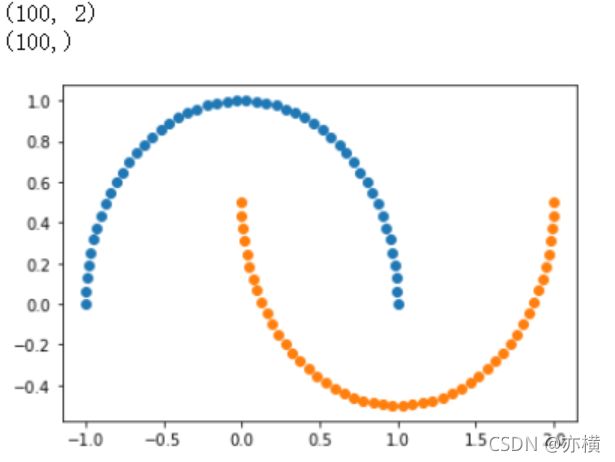
X, y = datasets.make_moons() #使用生成的数据
print(X.shape) # (100,2)
print(y.shape) # (100,)
# 接下来绘制下生成的数据
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
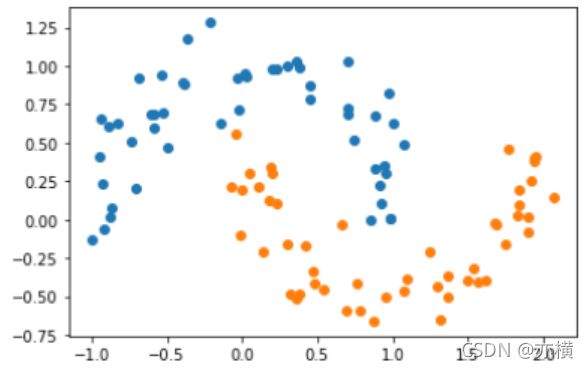
X, y = datasets.make_moons(noise=0.15,random_state=777)
#随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()

from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([ ("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()

from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly"))# poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
import numpy as np
import matplotlib.pyplot as plt
x = np.arange(-4,5,1)
#生成测试数据
y = np.array((x >= -2 ) & (x 2),dtype='int')
plt.scatter(x[y==0],[0]*len(x[y==0]))
# x取y=0的点, y取0,有多少个x,就有多少个y
plt.scatter(x[y==1],[0]*len(x[y==1]))
plt.show()
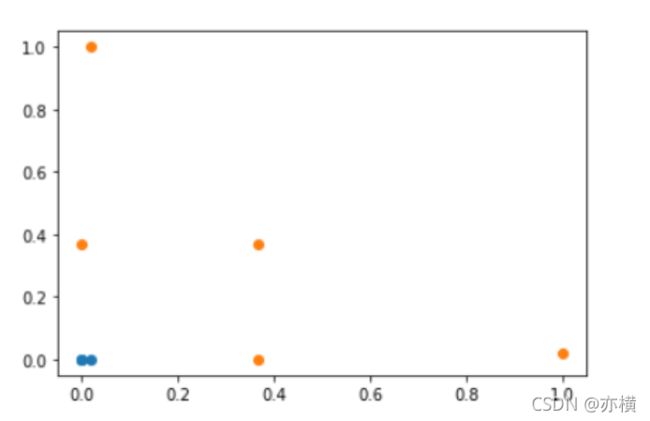
# 高斯核函数
def gaussian(x,l):
gamma = 1.0
return np.exp(-gamma * (x -l)**2)
l1,l2 = -1,1
X_new = np.empty((len(x),2))#len(x) ,2
for i,data in enumerate(x):
X_new[i,0] = gaussian(data,l1)
X_new[i,1] = gaussian(data,l2)
plt.scatter(X_new[y==0,0],X_new[y==0,1])
plt.scatter(X_new[y==1,0],X_new[y==1,1])
plt.show()

import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X,y = datasets.make_moons(noise=0.15,random_state=777)
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
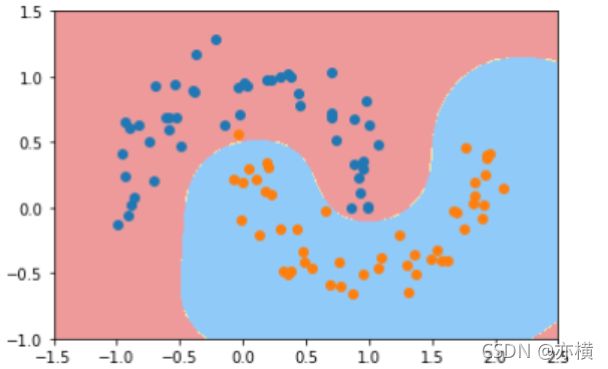
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=1.0):
return Pipeline([ ('std_scaler',StandardScaler()), ('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=100):
return Pipeline([ ('std_scaler',StandardScaler()), ('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()

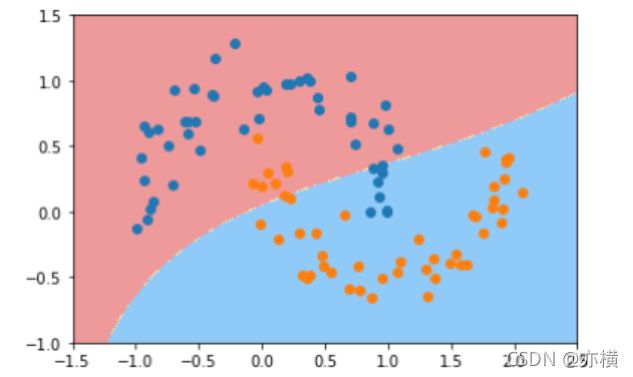
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
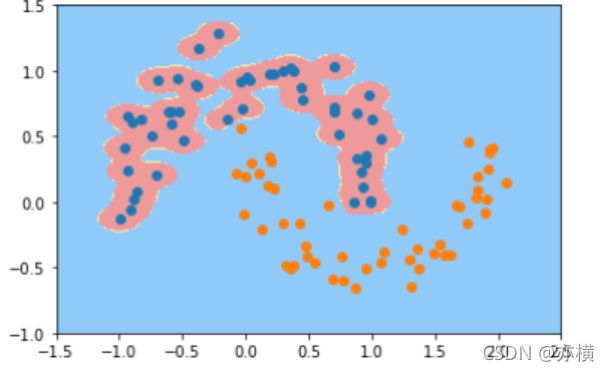
def RBFKernelSVC(gamma=10):
return Pipeline([ ('std_scaler',StandardScaler()), ('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.pipeline import Pipeline
def RBFKernelSVC(gamma=0.1):
return Pipeline([ ('std_scaler',StandardScaler()), ('svc',SVC(kernel='rbf',gamma=gamma)) ])
svc = RBFKernelSVC()
svc.fit(X,y)
plot_decision_boundary(svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
boston = datasets.load_boston()
X = boston.data
y = boston.target
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,random_state=777)
# 把数据集拆分成训练数据和测试数据
from sklearn.svm import LinearSVR
from sklearn.svm import SVR
from sklearn.preprocessing import StandardScaler
def StandardLinearSVR(epsilon=0.1):
return Pipeline([ ('std_scaler',StandardScaler()), ('linearSVR',LinearSVR(epsilon=epsilon)) ])
svr = StandardLinearSVR()
svr.fit(X_train,y_train)
svr.score(X_test,y_test)

参考文献
https://blog.csdn.net/YangMax1/article/details/121066454?spm=1001.2014.3001.5501
https://blog.csdn.net/weixin_56102526/article/details/121071127
https://blog.csdn.net/weixin_56102526/article/details/121110135?spm=1001.2014.3001.5501
第二章 人脸特征提取
一、打开摄像头,实时采集人脸并保存、绘制68个特征点
# -*- coding: utf-8 -*-
"""
Created on Wed Oct 27 03:15:10 2021
@author: GT72VR
"""
import numpy as np
import cv2
import dlib
import os
import sys
import random
# 存储位置
output_dir = 'D:/dlib'
size = 64
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 改变图片的亮度与对比度
def relight(img, light=1, bias=0):
w = img.shape[1]
h = img.shape[0]
# image = []
for i in range(0, w):
for j in range(0, h):
for c in range(3):
tmp = int(img[j, i, c] * light + bias)
if tmp > 255:
tmp = 255
elif tmp < 0:
tmp = 0
img[j, i, c] = tmp
return img
# 使用dlib自带的frontal_face_detector作为我们的特征提取器
detector = dlib.get_frontal_face_detector()
# 打开摄像头 参数为输入流,可以为摄像头或视频文件
camera = cv2.VideoCapture(0)
# camera = cv2.VideoCapture('C:/Users/CUNGU/Videos/Captures/wang.mp4')
ok = True
detector = dlib.get_frontal_face_detector()
predictor = dlib.shape_predictor('D:\BaiduNetdiskDownload\shape_predictor_68_face_landmarks.dat')
while ok:
# 读取摄像头中的图像,ok为是否读取成功的判断参数
ok, img = camera.read()
# 转换成灰度图像
img_gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
rects = detector(img_gray, 0)
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, rects[i]).parts()])
for idx, point in enumerate(landmarks):
# 68点的坐标
pos = (point[0, 0], point[0, 1])
print(idx, pos)
# 利用cv2.circle给每个特征点画一个圈,共68个
cv2.circle(img, pos, 2, color=(0, 255, 0))
# 利用cv2.putText输出1-68
font = cv2.FONT_HERSHEY_SIMPLEX
cv2.putText(img, str(idx + 1), pos, font, 0.2, (0, 0, 255), 1, cv2.LINE_AA)
cv2.imshow('video', img)
k = cv2.waitKey(1)
if k == 27: # press 'ESC' to quit
break
camera.release()
cv2.destroyAllWindows()

二、人脸虚拟P上一付墨镜
画墨镜函数:
def painting_sunglasses(img,detector,predictor):
#给人脸带上墨镜
rects = detector(img_gray, 0)
for i in range(len(rects)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img,rects[i]).parts()])
right_eye_x=0
right_eye_y=0
left_eye_x=0
left_eye_y=0
for i in range(36,42):#右眼范围
#将坐标相加
right_eye_x+=landmarks[i][0,0]
right_eye_y+=landmarks[i][0,1]
#取眼睛的中点坐标
pos_right=(int(right_eye_x/6),int(right_eye_y/6))
"""
利用circle函数画圆
函数原型
cv2.circle(img, center, radius, color[, thickness[, lineType[, shift]]])
img:输入的图片data
center:圆心位置
radius:圆的半径
color:圆的颜色
thickness:圆形轮廓的粗细(如果为正)。负厚度表示要绘制实心圆。
lineType: 圆边界的类型。
shift:中心坐标和半径值中的小数位数。
"""
cv2.circle(img=img, center=pos_right, radius=30, color=(0,0,0),thickness=-1)
for i in range(42,48):#左眼范围
#将坐标相加
left_eye_x+=landmarks[i][0,0]
left_eye_y+=landmarks[i][0,1]
#取眼睛的中点坐标
pos_left=(int(left_eye_x/6),int(left_eye_y/6))
cv2.circle(img=img, center=pos_left, radius=30, color=(0,0,0),thickness=-1)
运行:
camera = cv2.VideoCapture(0)#打开摄像头
ok=True
# 打开摄像头 参数为输入流,可以为摄像头或视频文件
while ok:
ok,img = camera.read()
# 转换成灰度图像
img_gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
#display_feature_point(img,detector,predictor)
painting_sunglasses(img,detector,predictor)#调用画墨镜函数
cv2.imshow('video', img)
k = cv2.waitKey(1)
if k == 27: # press 'ESC' to quit
break
camera.release()
cv2.destroyAllWindows()

参考文献
https://blog.csdn.net/wanerXR/article/details/121294090?spm=1001.2014.3001.5501