机器学习(十一)——集成学习
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务。根据个体学习器的生成方式,目前集成学习的方法大致分为两类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法;另一类就是个体学习器之间不存在强依赖关系、可同时生成的并行化方法。前者的代表是Boosting,后者的代表室Bagging和随机森林。
集成学习中的几个概念
1、个体学习器:集成学习的一般结构都是先产生一组个体学习器(individual learner),在用某种策略将他们结合起来,个体学习器通常由一个现有的学习算法从训练数据中产生。
2、基学习器:如果集成中只包含同种类型的个体学习器,例如决策树集成中全都是决策树,这样的集成是‘同质’(homogeneous)的,同质集成中的个体学习器又称‘基学习器’,相应的学习算法又称基学习算法。
3、组件学习器:集成也可以是包含不同类型的个体学习器,例如决策树和神经网络,这样的集成是‘异质’(heterogenous)的,异质集成中的个体学习器称为组件学习器或者直接称为个体学习器。
Hard Voting

import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()
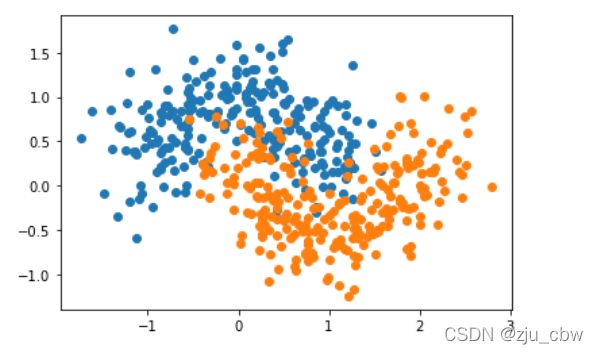
使用逻辑回归、决策树、svm三种算法集成,
from sklearn.linear_model import LogisticRegression
log_reg = LogisticRegression()
log_reg.fit(x_train, y_train)
log_reg.score(x_test, y_test)
# 0.864
from sklearn.svm import SVC
svc = SVC()
svc.fit(x_train, y_train)
svc.score(x_test, y_test)
# 0.888
from sklearn.tree import DecisionTreeClassifier
dt_clf = DecisionTreeClassifier()
dt_clf.fit(x_train, y_train)
dt_clf.score(x_test, y_test)
# 0.856
y_predict1 = log_reg.predict(x_test)
y_predict2 = svc.predict(x_test)
y_predict3 = dt_clf.predict(x_test)
# 如果三个分类器中有两个预测为1,则最终结果就为1
y_predict = np.array((y_predict1 + y_predict2 + y_predict3) >= 2, dtype='int')
from sklearn.metrics import accuracy_score
accuracy_score(y_test, y_predict)
# 0.896
根据集成输出结果0.896比三种算法都高。
接下来使用sklearn中封装的votingclassifier类实现投票
from sklearn.ensemble import VotingClassifier
voting_clf = VotingClassifier(estimators=[
('log_reg', LogisticRegression()),
('svm_clf', SVC()),
('dt_clf', DecisionTreeClassifier()),
], voting='hard')
voting_clf.fit(x_train, y_train)
voting_clf.score(x_test, y_test)
# 0.896
所谓的hard集成就是简单地根据预测为1的数量,其实就是少数服从多数。在很多情况下,少数服从多数并不是最合理的,然后更急合理的投票,应该是有权值的。由此引出soft 集成。
Soft Voting

集成学习中的soft voting要求集合的每一个模型都能估计概率。
(1)逻辑回归,本身就是基于概率模型的。
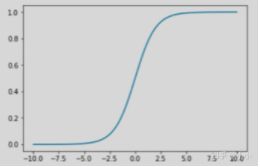
(2)KNN,k个近邻中数量最多的那个类的数量除以k就是概率。也可以考虑权值。
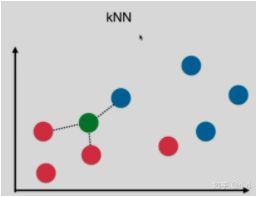
(3)决策树。叶子节点中那个类数量最大就是那个类,概率就是数量最大的那个类除以所有叶子节点的类。
(4)SVC。SVC本身是没有考虑概率的,它是寻找一个margin的最大值。但是也是可以计算过,不过需要消耗大量的计算资源。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
# plt.scatter(x[y==0, 0], x[y==0, 1])
# plt.scatter(x[y==1, 0], x[y==1, 1])
# plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import VotingClassifier
voting_clf2 = VotingClassifier(estimators=[
('log_reg', LogisticRegression()),
('svm_clf', SVC(probability=True)),
('dt_clf', DecisionTreeClassifier(random_state=666)),
], voting='soft')
voting_clf2.fit(x_train, y_train)
voting_clf2.score(x_test, y_test)
# 0.912
根据输出结果显然比Hrad Voting效果要好很多,但是仍然有个问题就是虽然有很多机器学习算法,但是从投票的角度看,仍然不够多。因此需要创建更多的子模型,集成更多的子模型的意见。而且子模型之间不能一致,必须要有差异性。
Bagging和Pasting
那么问题:如何创建差异性?每个子模型只能看数据样本的一部分。
例如:一共有500个样本数据,每个子模型只看100个样本数据。每个子模型不需太高的准确率。这是为什么?首先样本量减少模型的准确率降低是正常,通过集成能够提高。假如每个子模型只有51%的准确率,至少要比随机猜一个50%要高一点。提高的过程如下:

这就是集成学习的威力。但是在实际的使用过程很难保证500个子模型的准确率都高于平均水平,甚至有些子模型可能预测错误的概率比预测正确的概率还要高,但是这样并不影响总体准确率的提升。
由此,如何创建差异性?每个子模型只能看数据样本的一部分,就涉及取样。
取样:放回取样(Bagging)和不放回取样(Pasting)。在统计学,放回取样:bootstrap。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,)
bagging_clf.fit(x_train, y_train)
bagging_clf.score(x_test, y_test)
# 0.904
bagging_clf2 = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=5000,
max_samples=100,
bootstrap=True,)
bagging_clf2.fit(x_train, y_train)
bagging_clf2.score(x_test, y_test)
# 0.912
dt_clf = DecisionTreeClassifier()
dt_clf.fit(x_train, y_train)
dt_clf.score(x_test, y_test)
# 0.824
根据对比,当不适用集成学习只是用DecisionTree时,准确率只有0.824,使用500个子模型,每次有放回抽样100个样本,准确率为0.904,使用5000个样本,每次有放回抽样100个样本,准确率为0.912。
更多关于Bagging的讨论
- OOB(Out-of-Bag)
放回取样会有一定的概率导致一部分样本很有可能没有被取到,严格地进行数据计算平均大约有37%的样本是取不到的,这部分样本就成为Out-of-Bag。因此为了解决这个问题,就不需要将数据集划分为训练集和测试集了,就使用这部分没有被取到的样本做测试或验证。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=42)
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import BaggingClassifier
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=500,
max_samples=100,
bootstrap=True,
oob_score=True)
# 此时使用的数据集就是全部数据。oob_score=True的意思就使用剩下未取到的数据作为测试集。
bagging_clf.fit(x, y)
bagging_clf.oob_score_
# 0.918
- Bagging的思路极易并行化处理
%%time
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=5000,
max_samples=100,
bootstrap=True,
oob_score=True)
bagging_clf.fit(x, y)
# Wall time: 4.13 s
在sklearn中对于并行处理传入的参数:n_jobs,-1表示使用全部的核。
%%time
bagging_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=5000,
max_samples=100,
bootstrap=True,
oob_score=True,
n_jobs=-1)
bagging_clf.fit(x, y)
# Wall time: 2.38 s
- 使得子模型具有差异化。之前对于子模型的差异化是使用有放回的随机取样使得训练子模型的数据集有差异,
当然还有一种办法就是针对特征进行随机采样,Random Subspaces。
此外,还可以既针对样本,又针对特征进行随机采样。Random Patches。
- 在特征空间随机采样bootstrap_features
random_subspaces_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=5000,
max_samples=500,
bootstrap=True,
oob_score=True,
n_jobs=-1,
max_features=1,
bootstrap_features=True,)
# 在这里max_samples=500,表明所有的数据都用,并不对样本进行采样。
# max_features表示使用的特征数,因为生成的数据只有2维,因此在此就取1
# bootstrap_features表示使用随机特征抽取。
random_subspaces_clf.fit(x, y)
random_subspaces_clf.oob_score_
# 0.83
- 既针对样本,又针对特征进行随机采样
random_patches_clf = BaggingClassifier(DecisionTreeClassifier(),
n_estimators=5000,
max_samples=100,
bootstrap=True,
oob_score=True,
n_jobs=-1,
max_features=1,
bootstrap_features=True,)
# max_samples=100, bootstrap=True,表示针对样本进行随机抽样
# max_features=1,bootstrap_features=True表示针对样本特征进行随机抽样
random_patches_clf.fit(x, y)
random_patches_clf.oob_score_
# 0.858
随机森林
随机森林(Random Forest,简称RF)是Bagging的一个扩展变体,RF在以决策树为基学习器构建Bagging集成的基础是,进一步在决策树的训练过程中引入随机属性选择。
决策树在节点划分上,在随机的特征子集上寻找最优的划分特征。具体来说在传统决策树在选择划分属性时是当前结点的属性结合(假设有d个属性)中随机选择一个最优属性;而在RF中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含k个属性的子集,然后再从这个子集中选择一个属性用于划分。一般情况下,推荐 log2d。随机森林中基学习器的多样性不仅来自样本扰动,还来自属性扰动。这就使得最终集成的泛华性能可通过个体学习器之间差异度的增加而进一步提升。
在sklearn中已经封装了随机森林这个类:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=666)
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()
from sklearn.ensemble import RandomForestClassifier
rf_clf = RandomForestClassifier(n_estimators=500,
random_state=666,
oob_score=True,
n_jobs=-1,)
rf_clf.fit(x, y)
rf_clf.oob_score_
# 0.892
rf_clf2 = RandomForestClassifier(n_estimators=500,
random_state=666,
oob_score=True,
n_jobs=-1,
max_leaf_nodes=16)
rf_clf2.fit(x, y)
rf_clf2.oob_score_
# 0.906
Extra-Trees
极端随机树(Extremely randomized trees),决策树在节点划分上,使用随用随机的特征和随机的阈值。提供额外的随机性,抑制了过拟合,但是也一定程度地增大了bias。从偏差-方差分解的角度看,更加关注于降低方差。由于这种随机性使得能够更加快速地训练。
from sklearn.ensemble import ExtraTreesClassifier
et_clf = ExtraTreesClassifier(n_estimators=500, bootstrap=True, oob_score=True,
random_state=666)
et_clf.fit(x, y)
et_clf.oob_score_
# 0.892
ET与RF的区别:
1、RF应用了Bagging进行随机抽样,而ET的每棵决策树应用的是相同的样本。
2、RF在一个随机子集内基于信息熵和基尼指数寻找最优属性,而ET完全随机寻找一个特征值进行划分。
其实,集成学习除了可以解决分类问题,对于回归问题也是可以的。
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import ExtraTreesRegressor
Boosting
集成多个模型,每个模型都在尝试增强整体效果。具体来说:就是先从初始训练集训练出一个基学习器,再根据基学习器的表现对训练样本分布进行调整,使得先前学习器做的训练样本在后续受到更多的关注,然后基于调整后的样本分布来训练下一个学习器,如此重读进行,直至学习器数目达到预先指定的值。
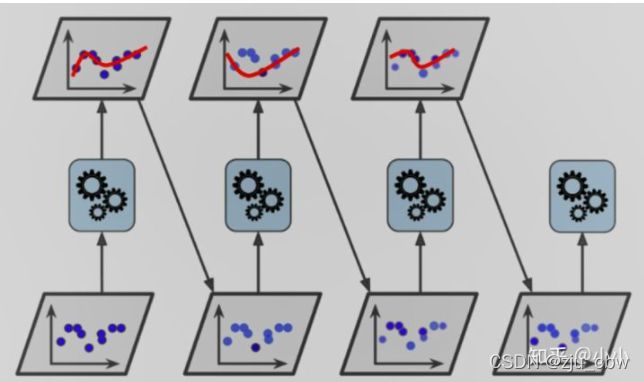
根据上面这张图来看,经过第一个学习器的学习后给预测错误样本呈现为更深的蓝色的点,训练正确的为浅色的蓝色的点,赋予错误的训练样本以更高的权重,对于经过调整的训练样本再次训练一个学习器,同理一直迭代下去。
Boosting族算法最著名的代表室AdaBoost[Freund and Schapire, 1997], AdaBoos算法有多种推导方式,比较容易的理解是基于加性模型,即学习器的线性组合。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
x, y =datasets.make_moons(n_samples=500, noise=0.3, random_state=666)
plt.scatter(x[y==0, 0], x[y==0, 1])
plt.scatter(x[y==1, 0], x[y==1, 1])
plt.show()
from sklearn.model_selection import train_test_split
# 这里由于不在采用随机抽样,因此需要分割数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=42)
from sklearn.ensemble import AdaBoostClassifier
from sklearn.tree import DecisionTreeClassifier
# 这里根据决策树的调参方式进行调参。
ada_clf = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(max_depth=2),
n_estimators=500,)
ada_clf.fit(x_train, y_train)
ada_clf.score(x_test, y_test)
# 0.848
Boosting算法要求基学习器能够对特定的数据分布进行学习,这可通过“重赋权法”实施,即在训练的过程的每一轮中,根据样本的分布为每个训练样本赋予一个权重,对无法接受带权样本的基学习算法可通过重采样对基学习器进行训练。
从偏差-方差分解的角度看,Boosting主要关注降低偏差。
Gradient Boosting Decision Tree
(1)GBDT为什么这么优秀?一是效果确实挺不错。二是即可以用于分类也可以用于回归。三是可以筛选特征。
(2)什么是GBDT?GBDT 是通过采用加法模型(即基函数的线性组合),以及不断减小训练过程产生的残差来达到将数据分类或者回归的算法。
(3)GBDT的训练过程?
训练一个模型m1,产生错误e1,针对e1训练第二个模型m2,产生错误e2,针对e2训练第三个模型m3,产生错误e3…,最终的预测结果是m1+m2+m3+…。
(4)在sklearn中梯度提升回归树有四种可选的损失函数,分别为’ls:平方损失’,‘lad:绝对损失’,‘huber:huber损失’,‘quantile:分位数损失’;
而在sklearn中梯度提升分类树有两种可选的损失函数,一种是‘exponential:指数损失’,一种是‘deviance:对数损失’。
接下来,使用sklearn简单实现梯度提升分类树。
from sklearn.ensemble import GradientBoostingClassifier
gb_clf = GradientBoostingClassifier(max_depth=2, n_estimators=30)
gb_clf.fit(x_train, y_train)
gb_clf.score(x_test, y_test)
# 0.904
结合策略
学习器结合可能会从三个方面带来好处:1、单个学习器可能因误选而导致泛化性能不佳;2、学习算法往往会陷入局部最小,而多次运行之后进行结合,可降低陷入局部最小的风险,3、结合多个学习器可以扩大假设的样本空间,提高模型的泛化能力。
- 平均法
- 简单平均法
- 加权平均法
- 投票法
- 绝对多数投票法,即若某标记得票超过半数,则预测为该标记,否则拒绝。
- 相对多数投票法,即预测为得票最多的标记,若同时有多个标记获得最高票,则随机从中选一个。
- 加权投票法
- 学习法(Stacking:Blending)
Stacking是学习法的典型代表。把个体学习器称为初级学习器,用于结合的学习器称为次级学习器。其实逻辑回归之所以能解决分类问题,我的个人理解就是初级学习器为线性回归,次级学习器为是一个分类器。但略微存在不同,原因如下:
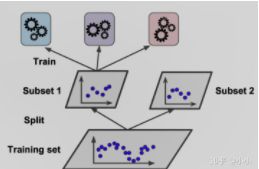
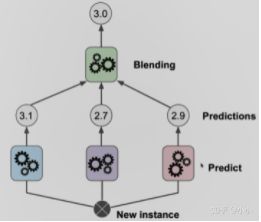
Stacking的策略是把训练样本集分为两部分,一部分用来训练初级学习器,通过初级分类器预测的结果和另外一部分样本一起用来训练次级学习器。由此得到最终的的预测结果。
如果将其更加复杂化一些,将训练样本分为三部分,第一部分训练layer1的三个学习器,第二部分训练layer2的学习器,第三部分跟layer2的学习器的预测结果一起训练得到layer3的学习器,这样得到最终的学习结果。此时这样的网络跟人工神经网络就有点类似了。
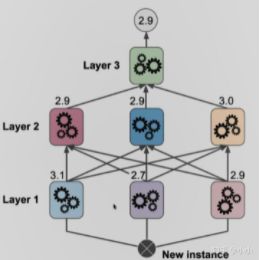
每个模型本身就有很多的超参数,需要有几层,又加上每一层使用的学习器的数量又是一个超参数,因此stacking就会复杂很多,也正是因为这种复杂性导致其容易产生过拟合。因此很不幸的是sklearn中并没有封装这样的函数,因为其灵活性和多样性导致其变化及其复杂,因此,往往比这种更加复杂的网络的时候就会使用神经网络,涉及深度学习的内容。