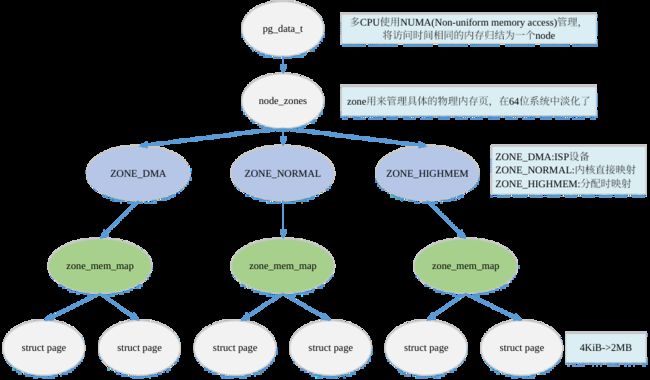
Linux物理内存管理:page、zone、node
基本概念
页:struct page ,如下图所示,x86架构下一般为4K为大小
分区:struct zone ,如下图所示,x86架构下分为三个区 ZONE_DMA,ZONE_NORMAL,ZONE_HIGHMEM
内存节点:struct node。对于一个简单的嵌入式系统只有一个node,对于大型服务器而言,有成千上万个CPU,这样肯定有成千上万个node,每个cpu都可以访问自己的内存,同时也可以通过总线访问其他内存。

x86架构内存分布
ZONE_DMA,一般由于内存碎片,有可能申请不到连续的一片物理内存,而DMA需要连续的物理内存,所以在X86下给DMA大概会留一块连续的16M的物理内存。
物理页:struct page
include/linux/mm_types.h
struct page 用来描述物理页
struct page {
/* First double word block */
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
union {
struct address_space *mapping; /* If low bit clear, points to
* inode address_space, or NULL.
* If page mapped as anonymous
* memory, low bit is set, and
* it points to anon_vma object:
* see PAGE_MAPPING_ANON below.
*/
void *s_mem; /* slab first object */
atomic_t compound_mapcount; /* first tail page */
/* page_deferred_list().next -- second tail page */
};
/* Second double word */
union {
pgoff_t index; /* Our offset within mapping. */
void *freelist; /* sl[aou]b first free object */
/* page_deferred_list().prev -- second tail page */
};
union {
#if defined(CONFIG_HAVE_CMPXCHG_DOUBLE) && \
defined(CONFIG_HAVE_ALIGNED_STRUCT_PAGE)
/* Used for cmpxchg_double in slub */
unsigned long counters;
#else
/*
* Keep _refcount separate from slub cmpxchg_double data.
* As the rest of the double word is protected by slab_lock
* but _refcount is not.
*/
unsigned counters;
#endif
struct {
union {
/*
* Count of ptes mapped in mms, to show when
* page is mapped & limit reverse map searches.
*
* Extra information about page type may be
* stored here for pages that are never mapped,
* in which case the value MUST BE <= -2.
* See page-flags.h for more details.
*/
atomic_t _mapcount;
unsigned int active; /* SLAB */
struct { /* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
int units; /* SLOB */
};
/*
* Usage count, *USE WRAPPER FUNCTION* when manual
* accounting. See page_ref.h
*/
atomic_t _refcount;
};
};
/*
* Third double word block
*
* WARNING: bit 0 of the first word encode PageTail(). That means
* the rest users of the storage space MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct list_head lru; /* Pageout list, eg. active_list
* protected by zone_lru_lock !
* Can be used as a generic list
* by the page owner.
*/
struct dev_pagemap *pgmap; /* ZONE_DEVICE pages are never on an
* lru or handled by a slab
* allocator, this points to the
* hosting device page map.
*/
struct { /* slub per cpu partial pages */
struct page *next; /* Next partial slab */
#ifdef CONFIG_64BIT
int pages; /* Nr of partial slabs left */
int pobjects; /* Approximate # of objects */
#else
short int pages;
short int pobjects;
#endif
};
struct rcu_head rcu_head; /* Used by SLAB
* when destroying via RCU
*/
/* Tail pages of compound page */
struct {
unsigned long compound_head; /* If bit zero is set */
/* First tail page only */
#ifdef CONFIG_64BIT
/*
* On 64 bit system we have enough space in struct page
* to encode compound_dtor and compound_order with
* unsigned int. It can help compiler generate better or
* smaller code on some archtectures.
*/
unsigned int compound_dtor;
unsigned int compound_order;
#else
unsigned short int compound_dtor;
unsigned short int compound_order;
#endif
};
#if defined(CONFIG_TRANSPARENT_HUGEPAGE) && USE_SPLIT_PMD_PTLOCKS
struct {
unsigned long __pad; /* do not overlay pmd_huge_pte
* with compound_head to avoid
* possible bit 0 collision.
*/
pgtable_t pmd_huge_pte; /* protected by page->ptl */
};
#endif
};
/* Remainder is not double word aligned */
union {
unsigned long private; /* Mapping-private opaque data:
* usually used for buffer_heads
* if PagePrivate set; used for
* swp_entry_t if PageSwapCache;
* indicates order in the buddy
* system if PG_buddy is set.
*/
#if USE_SPLIT_PTE_PTLOCKS
#if ALLOC_SPLIT_PTLOCKS
spinlock_t *ptl;
#else
spinlock_t ptl;
#endif
#endif
struct kmem_cache *slab_cache; /* SL[AU]B: Pointer to slab */
};
#ifdef CONFIG_MEMCG
struct mem_cgroup *mem_cgroup;
#endif
/*
* On machines where all RAM is mapped into kernel address space,
* we can simply calculate the virtual address. On machines with
* highmem some memory is mapped into kernel virtual memory
* dynamically, so we need a place to store that address.
* Note that this field could be 16 bits on x86 ... ;)
*
* Architectures with slow multiplication can define
* WANT_PAGE_VIRTUAL in asm/page.h
*/
#if defined(WANT_PAGE_VIRTUAL)
void *virtual; /* Kernel virtual address (NULL if
not kmapped, ie. highmem) */
#endif /* WANT_PAGE_VIRTUAL */
#ifdef CONFIG_KMEMCHECK
/*
* kmemcheck wants to track the status of each byte in a page; this
* is a pointer to such a status block. NULL if not tracked.
*/
void *shadow;
#endif
#ifdef LAST_CPUPID_NOT_IN_PAGE_FLAGS
int _last_cpupid;
#endif
}可以看到,struct page 这个结构体中是由很多union 结构体组成的,为什么要这样操作呢?
1.因为union 是共享内存空间的,定义出那个类型的内存,就使用那个类型的内存空间。而这个page实际上是可以表示很多类型的内存的,比如,page cache 表示我们的缓存,anonymous page 表示我们申请的普通的匿名页,还有一些小块内存 slab,slub等等,这样做就可以节省很多内存。
include/asm-generic/memory_model.h
#define __pfn_to_page(pfn) (mem_map + ((pfn) - ARCH_PFN_OFFSET))
#define __page_to_pfn(page) ((unsigned long)((page) - mem_map) + ARCH_PFN_OFFSET)
pfn : 代表物理页帧号
mem_map : 是一个全局指针,指向 struct page
内存区域:struct zone
定义:include/linux/mmzone.h
enum zone_type {
#ifdef CONFIG_ZONE_DMA
/*
* ZONE_DMA is used when there are devices that are not able
* to do DMA to all of addressable memory (ZONE_NORMAL). Then we
* carve out the portion of memory that is needed for these devices.
* The range is arch specific.
*
* Some examples
*
* Architecture Limit
* ---------------------------
* parisc, ia64, sparc <4G
* s390 <2G
* arm Various
* alpha Unlimited or 0-16MB.
*
* i386, x86_64 and multiple other arches
* <16M.
*/
ZONE_DMA,
#endif
#ifdef CONFIG_ZONE_DMA32
/*
* x86_64 needs two ZONE_DMAs because it supports devices that are
* only able to do DMA to the lower 16M but also 32 bit devices that
* can only do DMA areas below 4G.
*/
ZONE_DMA32,
#endif
/*
* Normal addressable memory is in ZONE_NORMAL. DMA operations can be
* performed on pages in ZONE_NORMAL if the DMA devices support
* transfers to all addressable memory.
*/
ZONE_NORMAL,
#ifdef CONFIG_HIGHMEM
/*
* A memory area that is only addressable by the kernel through
* mapping portions into its own address space. This is for example
* used by i386 to allow the kernel to address the memory beyond
* 900MB. The kernel will set up special mappings (page
* table entries on i386) for each page that the kernel needs to
* access.
*/
ZONE_HIGHMEM,
#endif
ZONE_MOVABLE,
#ifdef CONFIG_ZONE_DEVICE
ZONE_DEVICE,
#endif
__MAX_NR_ZONES
};初始化:arch/arm/mm/init.c zone_sizes_init(...) 函数中进行初始化的
struct zone
struct zone {
/* Read-mostly fields */
/* zone watermarks, access with *_wmark_pages(zone) macros */
unsigned long watermark[NR_WMARK];
unsigned long nr_reserved_highatomic;
/*
* We don't know if the memory that we're going to allocate will be
* freeable or/and it will be released eventually, so to avoid totally
* wasting several GB of ram we must reserve some of the lower zone
* memory (otherwise we risk to run OOM on the lower zones despite
* there being tons of freeable ram on the higher zones). This array is
* recalculated at runtime if the sysctl_lowmem_reserve_ratio sysctl
* changes.
*/
long lowmem_reserve[MAX_NR_ZONES];
#ifdef CONFIG_NUMA
int node;
#endif
struct pglist_data *zone_pgdat;
struct per_cpu_pageset __percpu *pageset;
#ifndef CONFIG_SPARSEMEM
/*
* Flags for a pageblock_nr_pages block. See pageblock-flags.h.
* In SPARSEMEM, this map is stored in struct mem_section
*/
unsigned long *pageblock_flags;
#endif /* CONFIG_SPARSEMEM */
/* zone_start_pfn == zone_start_paddr >> PAGE_SHIFT */
unsigned long zone_start_pfn;
/*
* spanned_pages is the total pages spanned by the zone, including
* holes, which is calculated as:
* spanned_pages = zone_end_pfn - zone_start_pfn;
*
* present_pages is physical pages existing within the zone, which
* is calculated as:
* present_pages = spanned_pages - absent_pages(pages in holes);
*
* managed_pages is present pages managed by the buddy system, which
* is calculated as (reserved_pages includes pages allocated by the
* bootmem allocator):
* managed_pages = present_pages - reserved_pages;
*
* So present_pages may be used by memory hotplug or memory power
* management logic to figure out unmanaged pages by checking
* (present_pages - managed_pages). And managed_pages should be used
* by page allocator and vm scanner to calculate all kinds of watermarks
* and thresholds.
*
* Locking rules:
*
* zone_start_pfn and spanned_pages are protected by span_seqlock.
* It is a seqlock because it has to be read outside of zone->lock,
* and it is done in the main allocator path. But, it is written
* quite infrequently.
*
* The span_seq lock is declared along with zone->lock because it is
* frequently read in proximity to zone->lock. It's good to
* give them a chance of being in the same cacheline.
*
* Write access to present_pages at runtime should be protected by
* mem_hotplug_begin/end(). Any reader who can't tolerant drift of
* present_pages should get_online_mems() to get a stable value.
*
* Read access to managed_pages should be safe because it's unsigned
* long. Write access to zone->managed_pages and totalram_pages are
* protected by managed_page_count_lock at runtime. Idealy only
* adjust_managed_page_count() should be used instead of directly
* touching zone->managed_pages and totalram_pages.
*/
unsigned long managed_pages;
unsigned long spanned_pages;
unsigned long present_pages;
const char *name;
#ifdef CONFIG_MEMORY_ISOLATION
/*
* Number of isolated pageblock. It is used to solve incorrect
* freepage counting problem due to racy retrieving migratetype
* of pageblock. Protected by zone->lock.
*/
unsigned long nr_isolate_pageblock;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/* see spanned/present_pages for more description */
seqlock_t span_seqlock;
#endif
int initialized;
/* Write-intensive fields used from the page allocator */
ZONE_PADDING(_pad1_)
/* free areas of different sizes */
struct free_area free_area[MAX_ORDER];
/* zone flags, see below */
unsigned long flags;
/* Primarily protects free_area */
spinlock_t lock;
/* Write-intensive fields used by compaction and vmstats. */
ZONE_PADDING(_pad2_)
/*
* When free pages are below this point, additional steps are taken
* when reading the number of free pages to avoid per-cpu counter
* drift allowing watermarks to be breached
*/
unsigned long percpu_drift_mark;
#if defined CONFIG_COMPACTION || defined CONFIG_CMA
/* pfn where compaction free scanner should start */
unsigned long compact_cached_free_pfn;
/* pfn where async and sync compaction migration scanner should start */
unsigned long compact_cached_migrate_pfn[2];
#endif
#ifdef CONFIG_COMPACTION
/*
* On compaction failure, 1<内存节点:node
定义:include/linux/mmzone.h
内存模型:UMA(一致性存储模型),NUMA(非一致性存储模型)
struct pglist_data :表示一个node内存中的资源
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
struct zonelist node_zonelists[MAX_ZONELISTS];
int nr_zones;
#ifdef CONFIG_FLAT_NODE_MEM_MAP /* means !SPARSEMEM */
struct page *node_mem_map;
#ifdef CONFIG_PAGE_EXTENSION
struct page_ext *node_page_ext;
#endif
#endif
#ifndef CONFIG_NO_BOOTMEM
struct bootmem_data *bdata;
#endif
#ifdef CONFIG_MEMORY_HOTPLUG
/*
* Must be held any time you expect node_start_pfn, node_present_pages
* or node_spanned_pages stay constant. Holding this will also
* guarantee that any pfn_valid() stays that way.
*
* pgdat_resize_lock() and pgdat_resize_unlock() are provided to
* manipulate node_size_lock without checking for CONFIG_MEMORY_HOTPLUG.
*
* Nests above zone->lock and zone->span_seqlock
*/
spinlock_t node_size_lock;
#endif
unsigned long node_start_pfn;
unsigned long node_present_pages; /* total number of physical pages */
unsigned long node_spanned_pages; /* total size of physical page
range, including holes */
int node_id;
wait_queue_head_t kswapd_wait;
wait_queue_head_t pfmemalloc_wait;
struct task_struct *kswapd; /* Protected by
mem_hotplug_begin/end() */
int kswapd_order;
enum zone_type kswapd_classzone_idx;
int kswapd_failures; /* Number of 'reclaimed == 0' runs */
#ifdef CONFIG_COMPACTION
int kcompactd_max_order;
enum zone_type kcompactd_classzone_idx;
wait_queue_head_t kcompactd_wait;
struct task_struct *kcompactd;
#endif
#ifdef CONFIG_NUMA_BALANCING
/* Lock serializing the migrate rate limiting window */
spinlock_t numabalancing_migrate_lock;
/* Rate limiting time interval */
unsigned long numabalancing_migrate_next_window;
/* Number of pages migrated during the rate limiting time interval */
unsigned long numabalancing_migrate_nr_pages;
#endif
/*
* This is a per-node reserve of pages that are not available
* to userspace allocations.
*/
unsigned long totalreserve_pages;
#ifdef CONFIG_NUMA
/*
* zone reclaim becomes active if more unmapped pages exist.
*/
unsigned long min_unmapped_pages;
unsigned long min_slab_pages;
#endif /* CONFIG_NUMA */
/* Write-intensive fields used by page reclaim */
ZONE_PADDING(_pad1_)
spinlock_t lru_lock;
#ifdef CONFIG_DEFERRED_STRUCT_PAGE_INIT
/*
* If memory initialisation on large machines is deferred then this
* is the first PFN that needs to be initialised.
*/
unsigned long first_deferred_pfn;
/* Number of non-deferred pages */
unsigned long static_init_pgcnt;
#endif /* CONFIG_DEFERRED_STRUCT_PAGE_INIT */
#ifdef CONFIG_TRANSPARENT_HUGEPAGE
spinlock_t split_queue_lock;
struct list_head split_queue;
unsigned long split_queue_len;
#endif
/* Fields commonly accessed by the page reclaim scanner */
struct lruvec lruvec;
/*
* The target ratio of ACTIVE_ANON to INACTIVE_ANON pages on
* this node's LRU. Maintained by the pageout code.
*/
unsigned int inactive_ratio;
unsigned long flags;
ZONE_PADDING(_pad2_)
/* Per-node vmstats */
struct per_cpu_nodestat __percpu *per_cpu_nodestats;
atomic_long_t vm_stat[NR_VM_NODE_STAT_ITEMS];
} pg_data_t;核心结构体关联
typedef struct pglist_data {
struct zone node_zones[MAX_NR_ZONES];
}pg_data_t;
struct zone {
struct free_area free_area[MAX_ORDER];
struct pglist_data *zone_pgdat;
}____cacheline_internodealigned_in_smp;
struct free_area {
struct list_head free_list[MIGRATE_TYPES];
unsigned long nr_free;
};
struct list_head {
struct list_head *next, *prev;
};
enum {
MIGRATE_UNMOVABLE,
MIGRATE_MOVABLE,
MIGRATE_RECLAIMABLE,
MIGRATE_PCPTYPES, /* the number of types on the pcp lists */
MIGRATE_HIGHATOMIC = MIGRATE_PCPTYPES,
#ifdef CONFIG_CMA
/*
* MIGRATE_CMA migration type is designed to mimic the way
* ZONE_MOVABLE works. Only movable pages can be allocated
* from MIGRATE_CMA pageblocks and page allocator never
* implicitly change migration type of MIGRATE_CMA pageblock.
*
* The way to use it is to change migratetype of a range of
* pageblocks to MIGRATE_CMA which can be done by
* __free_pageblock_cma() function. What is important though
* is that a range of pageblocks must be aligned to
* MAX_ORDER_NR_PAGES should biggest page be bigger then
* a single pageblock.
*/
MIGRATE_CMA,
#endif
#ifdef CONFIG_MEMORY_ISOLATION
MIGRATE_ISOLATE, /* can't allocate from here */
#endif
MIGRATE_TYPES
};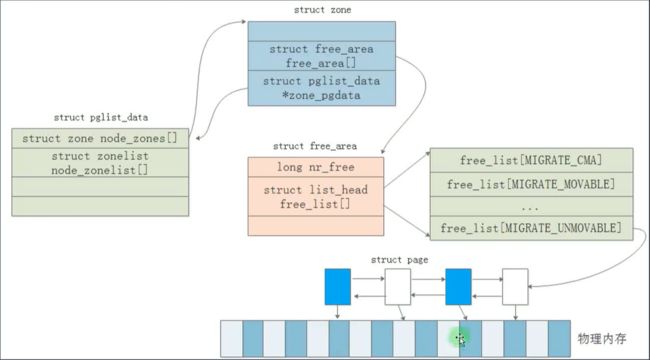
核心结构体关联
物理内存架构