SuperPoint特征检测算法Train&Evaluate教程
SuperPoint: Self-Supervised Interest Point Detection and Description
前言
SuperPoint是一种基于深度学习的自监督特征点检测算法,关于这个论文的详细内容不在此篇文章解释,本文只介绍如何使用该算法进行特征点检测。
paper原文:SuperPoint: Self-Supervised Interest Point Detection and Description
官方代码:GitHub/magicleap/SuperPointPretrainedNetwork
因为原文作者明确表示不发布训练&评估代码,本篇文章使用的代码是非官方的训练代码,链接:GitHub/rpautrat/SuperPoint
在此之前已经有人写过SuperPoint训练的过程,但用的是官方训练的COCO数据集,我将在此基础上更详细的介绍并补充如何替换训练数据集及使用评估代码。
准备工作
运行环境:python==3.6.1。
requirements.txt:
tensorflow-gpu==1.12
numpy
scipy
opencv-python==3.4.2.16
opencv-contrib-python==3.4.2.16
tqdm
pyyaml
flake8
jupyter
make install # install the Python requirements and setup the paths
我用的是Debian GNU系统,其他Linux发行版也一样。
关于dataset读取路径和输出路径都在 superpoint/settings.py 中,分别为DATA_PATH和EXPER_PATH。
第一步:创建Synthetic Shapes Dataset并训练MagicPoint特征检测器
Synthetic Shapes Dataset是合成形状数据集,该数据集有9种不同的形状(包括椭圆和高斯噪声,作为负样本),并有.npy文件记录特征点的坐标位置作为label进行训练,如下图所示。

python experiment.py train configs/magic-point_shapes.yaml magic-point_synth
其中magic-point_synth是实验名称,可以更改为任何名称。训练可以在任何时候使用Ctrl+C中断,权重将保存在 EXPER_PATH/magic-point_synth/ 中,里面也包括了Tensorboard的记录文件。当第一次训练时,将生成合成形状数据集,数据集保存在 superpoint/datasets/synthetic_shapes_v6 文件夹中。
magic-point_shapes.yaml文件里面有可修改的各种数据及训练参数。
第二步:MagicPoint检测器自标注数据集
得到训练后的MagicPoint检测器后,我们需要使用它对真实图像数据集进行标注,获得伪真实(pseudo-ground truth)的data及label,其中进行了一个图像处理操作叫做Homographic Adaptation,它也是SuperPoint这么好用的一个创新点。当然,你也可以在yaml文件中设置选择开启或关闭该操作。
python export_detections.py configs/magic-point_coco_export.yaml magic-point_synth --pred_only --batch_size=5 --export_name=magic-point_coco-export1

输出为一堆.npy文件,记录了输入图像的特征点伪真实标签,输出路径在 EXPER_PATH/outputs/magic-point_coco-export1/ 。在npy文件中特征点坐标保存在 属性f.points 。同样,在 magic-point_coco_export.yaml 文件中可以进行各种调参。
查看特征点标签(label)的坐标:
import numpy as np
point_path = r'hjOD70.npz'
npz = np.load(point_path)
point = npz.f.points.tolist()
print(npz.f.points)
这一步我们可以选择不用COCO数据集,替换为自己的数据集,但要注意替换的数据集图像尺寸必须要能被8整除。
1.修改训练图像尺寸
paper和code中使用COCO数据集图像尺寸为240×320,如果想要修改尺寸需要在 superpoint/datasets/coco.py 代码中default_config ={‘'preprocessing ': [‘resize’ : [240, 320] ] }修改成自己数据集图像的尺寸。
coco.py:
default_config = {
'labels': None,
'cache_in_memory': False,
'validation_size': 100,
'truncate': None,
'preprocessing': {
# 'resize': [240, 320]
'resize': [800, 400]
},
......
2.修改读取图像路径
在 coco.py 文件中修改base_path,DATA_PATH在 settings.py 中修改。
coco.py:
def _init_dataset(self, **config):
# base_path = Path(DATA_PATH, 'COCO/train2014/')
base_path = Path(DATA_PATH, '自己的数据集地址')
......
3.(可选)修改数据集名称
如果你的数据集不想叫COCO…可以修改 magic-point_coco_export.yaml 文件data的name属性。
magic-point_coco_export.yaml:
data:
name: 'coco' <-----修改这里
cache_in_memory: false
validation_size: 100
但一定要在 superpoint/datasets/ 文件夹下复制 coco.py 并重命名为自己的 数据集名称.py ,且修改其中的class类名为自己的数据集名称。
下图是用MagicPoint检测器检测到的特征点。
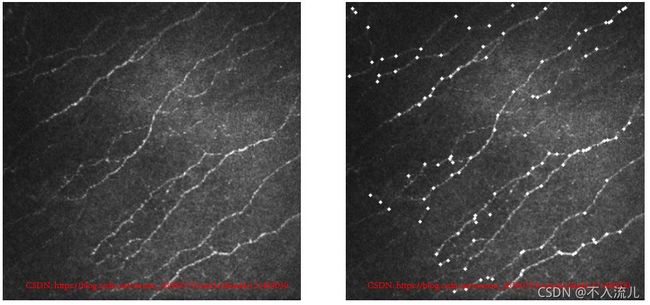
第三步:再次训练MagicPoint检测器
在第一步训练出来的MagicPoint检测器虽然可以检测出一些特征点,可因为是使用合成形状数据集训练出来的模型,检测性能还有些不足,所以进行第二步自标注数据,再用标记好的真实图像训练,得到的强化版的检测器。
python experiment.py train configs/magic-point_coco_train.yaml magic-point_coco
在此步骤依旧需要修改labels读取路径,将第二步得到的npz文件夹路径替换到labels路径中,代码作者也在 magic-point_coco_train.yaml 文件中做了提醒。
magic-point_coco_train.yaml:
data:
name: 'coco' # 如果第二步中修改了name,此处依旧需要修改。
labels: outputs/mp_synth-v10_ha2-100 # Complete with your export labels 修改此处labels路径!!!
cache_in_memory: false
validation_size: 192

训练结束后会得到最终的MagicPoint特征检测器。
第四步:(可选)使用MagicPoint进行特征检测
paper中使用Hpatches数据集进行性能评估验证,HPatches: Homography-patches dataset.该数据集在ECCV2016上提出,被用作局部描述符评估挑战的基础,每个文件夹下包含5张.ppm格式的图像与其单应矩阵H,每张图像相较于原图像都做了不同的变换(视角或光照)。评估检测器的性能:
python export_detections_repeatability.py configs/magic-point_repeatability.yaml magic-point_coco --export_name=magic-point_hpatches-repeatability-v
结果保存在 EXPER_DIR/outputs/magic-point_hpatches-repeatability-v/ ,我们还可以修改 magic-point_repeatability.yaml 中的相关参数 :
data:
name: 'patches_dataset'
dataset: 'coco' # 'coco' 'hpatches' 图像后缀为.jpg选择'coco',后缀为.ppm选择'hpatches'。
alteration: 'all' # 'all' 'i' 'v' 'i'为光照(illumination)变化,'v'为视角(viewpoint)变化。
preprocessing:
resize: [384, 384] # [240, 320] for HPatches and False for coco
如果我们的数据集仅有图像,不是Hpatches dataset格式(有变化后的图像和可验证单应矩阵H),作者还为我们留了生成该格式的代码 generate_coco_patches.py ,修改代码的43和45行的base_path、output_dir,运行后就可以得到Hpatches dataset格式的图像数据。
每个文件夹都包含了原图像和变换后的图像。

评估后的结果是一堆.npz格式文件,里面的f属性包含以下5个内容,分别是单应矩阵、原图像、原图像每个点的特征置信度、变换图像、变换图像每个点的特征置信度。这些是paper中repeatability评估指标的所需数据,更多解释在paper中寻找…

第五步:训练SuperPoint检测器
将第二步标注好的label用来训练SuperPoint模型,首先修改 superpoint_coco.yaml 中data/label的路径:
data:
name: 'coco' #如果修改了data name,这里依旧需要修改
cache_in_memory: false
validation_size: 96
labels: outputs/mp_synth-v11_export_ha2 # 使用第二步中保存出的label路径
修改完成后键入指令:
python experiment.py train configs/superpoint_coco.yaml superpoint_coco
![]()
等待训练完成即可得到SuperPoint特征检测模型。
注意此环节可能报错:段错误 或 Segmentation fault,是因为爆显存了…本人使用tesla P100 16G显卡,训练384×384尺寸 共10000张图像,在 superpoint_coco.yaml 配置文件中batch size设置1(初始为2),可解决此问题。
未完待续…