Pytorch 深度学习实践Lecture_9 Softmax Classifier
up主 刘二大人
视频链接 刘二大人的个人空间_哔哩哔哩_Bilibili
使用Softmax预测多分类问题
输出需要满足分布的条件
1) ![]()
2) 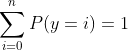
假设 ![]() 是最后一层的输出, Softmax 公式为
是最后一层的输出, Softmax 公式为
![]()
示例

损失函数(交叉熵)
![]()

numpy 计算loss示例:
import numpy as np
y = np.array([1, 0, 0])
z = np.array([0.2, 0.1, -0.1])
y_pred = np.exp(z) / np.exp(z).sum()
loss = (-y * np.log(y_pred)).sum()
print(loss)
# output: 0.9729189131256584
如下过程可以使用torch.nn.CrossEntropyLoss() 计算loss
只要把最后一层的输出作为输入即可

import torch
y = torch.LongTensor([0])
z = torch.Tensor([[0.2, 0.1, -0.1]])
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(z, y)
print(loss)
# output: tensor(0.9729)
"""
Mini-Batch: batch_size = 3
"""
Y = torch.LongTensor([2, 0, 1])
y_pred_1 = torch.Tensor([[0.1, 0.2, 0.9], # 2 (True)
[1.1, 0.1, 0.2], # 0 (True)
[0.2, 2.1, 0.1]]) # 1 (True)
y_pred_2 = torch.Tensor([[0.8, 0.2, 0.3], # 2 (False)
[0.2, 0.3, 0.5], # 0 (False)
[0.2, 0.2, 0.5]]) # 1 (False)
loss_1 = criterion(y_pred_1, Y)
loss_2 = criterion(y_pred_2, Y)
print(f"Batch Loss1 = {loss_1}")
print(f"Batch Loss2 = {loss_2}")
#Batch Loss1 = 0.4966353178024292
#Batch Loss2 = 1.2388995885849
CrossEntropyLoss 和NLLLoss的用法
CrossEntropyLoss — PyTorch 1.11.0 documentation
NLLLoss — PyTorch 1.11.0 documentation
1) CrossEntropyLoss: 网络的最后一层线性层的输出可以直接作为该损失函数的输入。
CrossEntropyLoss = Softmax + Log + NLLLoss
2) NLLLoss: 网络的最后一层线性层的输入不能直接使用,需要经过LogSoftmax后的输出作为NLLLoss的输入
借鉴如下博客:
Pytorch详解NLLLoss和CrossEntropyLoss_豪哥123的博客-CSDN博客_nllloss
pytorch中CrossEntropyLoss和NLLLoss的区别与联系_Dynamicw的博客-CSDN博客_crossentropyloss nllloss 区别
MNIST 手写数字预测
【PyTorch学习笔记】15:动量(momentum),学习率衰减_LauZyHou的博客-CSDN博客_momentum取值
解决pytorch本地导入mnist数据集报错问题_Shine.Zhang的博客-CSDN博客_使用pytorch导入mnist数据集
每一张image都只有黑白色,通道数为1,大小为 28*28 , 所以输入为1*28*28
代码实现:
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.optim as optim
import torch.nn.functional as F
import matplotlib.pyplot as plt
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.l1 = torch.nn.Linear(784, 512)
self.l2 = torch.nn.Linear(512, 256)
self.l3 = torch.nn.Linear(256, 128)
self.l4 = torch.nn.Linear(128, 64)
self.l5 = torch.nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 784)
x = F.relu(self.l1(x))
x = F.relu(self.l2(x))
x = F.relu(self.l3(x))
x = F.relu(self.l4(x))
return self.l5(x) # 最后一层不激活
batch_size = 64
"""
torchvision.transforms: pytorch中的图像预处理包
一般用Compose把多个步骤整合到一起, 这里采用了两步:
1) ToTensor(): Convert a PIL Image or numpy.ndarray to tensor
2) Normalize(mean, std[, inplace]): 使用均值, 方差对Tensor进行归一化处理
"""
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
"""
torchvision.datasets.MNIST(root, train=True, transform=None, target_transform=None, download=False)
root: 数据集存放目录
train:
True: 导入训练数据
False: 导入测试数据
download: 是否下载数据集
transform: 对数据进行变换(主要是对PIL image做变换)
"""
train_dataset = datasets.MNIST(root='data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
model = Net()
criterion = torch.nn.CrossEntropyLoss()
"""
momentum: 动量因子(默认0),综合考虑了梯度下降的方向和上次更新的方向
"""
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0
for batch_id, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_id % 300 == 299:
print('[epoch=%d, batch=%d] loss: %3f' % (epoch + 1, batch_id + 1, running_loss / 300))
print(f'epoch={epoch}, total loss={running_loss}')
return running_loss
def test():
correct = 0
total = 0
with torch.no_grad(): # 以下code不生成计算图
for data in test_loader:
"""
images, labels = x, y
images: torch.Size([64, 1, 28, 28])
labels: 64
"""
images, labels = data
# batch=64 -> output shape=(64,10)
outputs = model(images)
"""
torch.max(input_tensor): 返回input_tensor中所有元素的最大值
max_value, max_value_index = torch.max(input_tensor, dim=0): 返回每一列的最大值,且返回索引(返回最大元素在各列的行索引)
max_value, max_value_index = torch.max(input_tensor, dim=1): 返回每一行的最大值,且返回索引(返回最大元素在各列的行索引)
"""
_, predict = torch.max(outputs.data, dim=1)
total += labels.size(0)
"""
predict==labels -> tensor (size=predict=labels) value:True/False
(predict == labels).sum() -> tensor, value: 等于True的个数
(predict == labels).sum().item() -> 数值(上一步等于True的个数)
"""
correct += (predict == labels).sum().item()
accuracy = str(100 * correct / total) + '%'
print(f'Accuracy on test set: {accuracy}')
return accuracy
if __name__ == '__main__':
epoch_list = []
accuracy_list = []
loss_list = []
for epoch in range(10):
loss = train(epoch)
accuracy = test()
epoch_list.append(epoch)
loss_list.append(loss)
accuracy_list.append(accuracy)
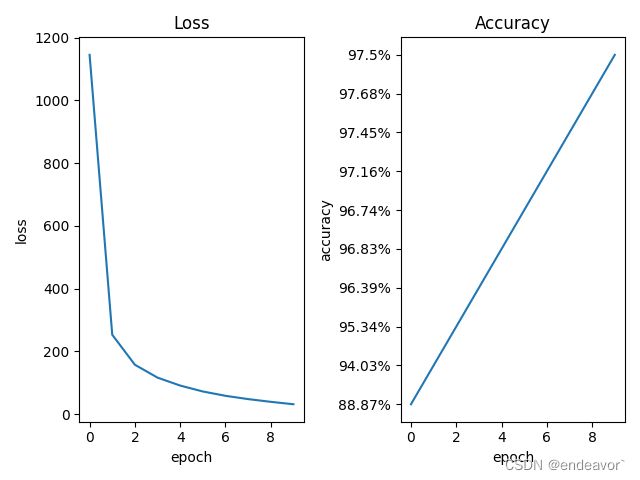
# plot 1 loss:
plt.subplot(1, 2, 1)
plt.plot(epoch_list, loss_list)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.title("Loss")
plt.tight_layout() # 设置默认的间距
# plot 2 accuracy:
plt.subplot(1, 2, 2)
plt.plot(epoch_list, accuracy_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.title("Accuracy")
plt.tight_layout() # 设置默认的间距
plt.show()
结果显示: