论文阅读——Deformable ConvNets v2: More Deformable, Better Results
可变形卷积DCNv2
from MSRA
Abstract
可变形卷积的优越性能来自于其适应物体集合变化的能力。通过对可变形卷积的自适应变化的研究,本文观察到与常规卷积神经网络相比,虽然其对特征的空间支持更深,更符合对象的结构,但是可能会超出ROI区域,导致特征受到图像无关区域内容的影响。
为了抑制这一问题,本文提出可变形卷积的升级版本,通过增强Deformable ConvNet的建模能力和改进训练过程,提升可变形卷积聚焦相关区域的能力。
其中建模能力的提升是通过在网络中引入集成度更高的全方位的可变形卷积,以及扩展对变形区域的调制机制。
为了更好的利用可变卷积的建模能力,本文提出一种特征模拟机制来引导模型的训练过程,这一机制有助于网络学习反映RCNN网络检测到的物体焦点/分类特征。
得益于以上优化,新版本的可变形卷积在基于COCO数据集做目标检测和实例分割任务上均超过了原始模型。
Section I Introduction
由于物体尺度、姿态以及部位变形导致的几何变形一直是目标检测任务的一大挑战。目前能够有效解决这一问题的就是可变形卷积网络(Deformable Convolutional Networks,DCNs),通过在网络中引入两种模块来对诸如此类的变形进行建模。一种是可变形卷积模块(deformable convolution),通过对标准卷积的常规网格采样中加入学习到的偏移量;另一种模块是可变形RoI池化(deformable RoI pooling)会对RoI pooling每一个bin的位置添加一个偏移量,从而根据物体的形状进行自适应的定位。从而有效提升了目标检测的精度。
为了理解可变形卷积的运作机制,本文可视化了对应感受野的变化,发现激活单元倾向于聚集在目标周围;但是同时也发现对于目标对象的覆盖仍不十分精确,有的样本超出了目标的RoI区域。在更具挑战的COCO数据集中,这一现象变得更加明显。可变形卷积仍有很大的发展空间。
因此本文提出可变形卷积的优化版本-DCNv2,提升了可变形卷积的建模能力。主要从以下两方面进行了提升:
一是扩展了可变形卷积的采样范围,允许在更广泛的范围内进行采样,从而提升对偏移的学习能力;
二是在可变形卷积中引入了调制机制,使得每个样本不仅需要学习一个偏移量还受到一个科学系的特征幅度的调制。从而使得网络具备应对网络分布对采样点的影响的能力。
为了充分利用可变形卷积网络的建模能力,需要有效的训练过程。受知识蒸馏的启发,本文使用RCNN作为teacher network用于在训练过程中提供指导。虽然RCNN是用于分类的网络但是其特征学习不会受到RoI区域以外的无关信息的影响。为了模拟这一性质,DCNv2在训练过程中引入一项特征模拟损失函数(feature mimicking loss),这样可以学习与RCNN一致的特征。这样DCNv2在训练的时候皆可以增强对变形区域的采样。
经过以上优化,可变形卷积模块依然保持轻量级,可以轻易集成到其他网络体系结构中。本文将DCNv2集成到Faster R-CNN和Mask R-CNN中,用于在COCO数据集上进行目标检测和实例分割。
Section II Analysis of Deformable ConvNet Behavior
对可变形卷积的分析
Part A Spatial Support Visualization
为了更好的理解可变形卷积,本文可视化了感受野以及有效采样位置、误差显著性区域来理解对空间变化的支持。
Effective receptive field:
有效感受野 并非所有像素点对相应响应的贡献是同等的,而是由差异的。这些贡献的差异用一个有效感受野(effective receptive field)表示不同像素点对网络节点的相对影响,但需要注意的是这一测度并不反映全局的结构化信息。
Effective sampling/bin locations:
通过可视化采样位置以及RoI池化中bin的位置可以进一步了解Dedormable ConvNet但是并没有揭示这些采样位置对网络节点的贡献,因此本文通过计算各网络节点相对于采样位置/bin位置的梯度来进一步了解这些位置对网络节点的贡献。
Error-bounded saliency regions:
如果移除与该节点无关的区域是不会影响该节点的响应的。基于这一性质本文可以将确定节点响应对应的最小区域定义为节点的support region,因为这部分区域可以给出与完整图像同样的响应。本文将这部分区域称之为误差显著性区域。这部分区域可以通过逐步mask图像并依次计算对应的节点响应来找到(详情参见附录)。通过误差显著性区域可以对比不同网络的support region.
Part B Spatial Support of Deformable ConvNets
本小节分析目标检测任务中可变形卷积网络的support region。基线网络为Faster-RCNN+ResNet50在COCO数据集上进行训练。需要注意的就是当偏移量的学习率设置为0的时候Deformable Faster-RCNN就退化为常规的Faster RCNN.

Fig 1展示了常规ConvNet,DCNv1和DCNv2conv5最后一层中不同节点的support region每幅图从上到下依次是有效采样位置、有效感受野以及错误显著性区域。在©中略过的有效采样位置与(b)中遗漏的很类似,这就使得卷积核能提供的额外信息很有限。可以得到以下观察结果:
1.常规卷积网络可以一定程度上建模集合变化,主要得益于深度卷积网络强大的特征表述能力,使得网络权重可以学习一定程度的几何变换。
2.通过引入可变卷积,即使在极具挑战性的COCO数据集上进一步增强了网络对于模型几何变化建模的能力。可以看到spatial support更加适应图像内容,前景物体的节点几乎覆盖整个物体,而背景部分对应的节点扩展能够获得更广阔的的上下文。但是这一空间支持的范围spatial support可能是不精确的,因为从实际有效感受野和错误显著性区域可以看到包括了与检测无关的背景区域。
3.使用这三种可视化方法显示采样位置可以提供更多的信息。比如在常规卷积网络中每一节点对应的采样位置是固定的,但也可通过调控网络权重参数进行动态调整;在可变形卷积网络中也可通过偏移的学习和权重的学习达到同样的效果。如果只分析具体的采样位置就可能得到关于可变形卷积网络一些误导性的结论。

Fig2展示了做目标检测的一些可视化结果。上下两行分别是有效Bin位置以及有效的感受野和错误显著性区域。c-e中省略的effective bin location的信息因为能够提供的信息有限。
根据可视化effective bin location表明,目标前景物体其分类分支传递过来的梯度一般更大,因此对最终的预测结果产生更大的影响。
随后在Deformable RoI pooling中由于学习了bin的偏移,使得bin对目标的覆盖范围更大,同时也能为下游的Faster RCNN提供更多的信息。而可视化错误显著性区域也能看出,不管在常规的RoI pooling还是在Deformable RoI pooling中都不能完全聚焦在前景物体上,根据相关研究[6]这种特征可能会干扰最终的检测任务。
通过以上可视化结果可以看出,虽然可变形卷积提升了应对几何变化的能力,但是其spatial support区域可能超出了RoI区域。
因此本文希望通过升级改进Deformable ConvNet使其能够更好的关注相关的图像内容,进一步提升检测精度。
Section III More deformable ConvNets
为了进一步提升网络应对几何变形的能力,本文对DCN做了一些改进提升模型对这种变化的建模能力。
Part A Stacking more deformable Conv Layers
鉴于可变形卷积网络可以有效应对几何变形,本文将网络中更多的常规卷积层替换为可变卷积层,从而进一步增强整个网络对几何变形的建模能力。
本文将ResNet-50 conv3\4\5中所有的3x3卷积层替换为deformable convolution,因此网络中一共有12层可变卷积层。
[8]中的结论是对于相对简单的小规模的PASCAL VOC基准网络中,当堆叠超过三层时性能就会饱和。而更具挑战性的COCO数据集一些误导性的可视化结果阻碍了对更具挑战性的基准模型的进一步探索。 通过本文的实验发现在COCO做目标检测任务中conv3-5阶段使用可变卷积可以在精度和效率之间达到最好的权衡。
Part B Modulated Deformable Modules
为了进一步增强可变卷积对空间区域的调控能力,本文引入了一种调制机制。这样可变卷积不仅可以调控输入特征的偏移量,还可以调节不同空间位置/不同bin其输入特征的幅度。
极端情况下,甚至可以通过将特征幅度值设定为0决定不接受特定区域传来的任何信息。这样图像对应位置的内容将不会对最终的模块输出产生任何影响,这样调控机制就为网络模块提供了调控其空间支持区域的另一个自由维度。
比如某卷积核采样K个点,wk和pk对应权重和学习的偏移量,x和y分别表示当前位置的输入和输出feature map,则modulated deformable convolution可以表述为:
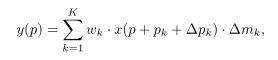
其中△pk和△mk分别代表第k个位置学习到的偏移量和调制量。而这两个量都是在单独的卷积层上输入相同的特征映射x得到的,因此卷积层与当前所在的卷积层具有同样的空间分辨率和膨胀尺度。
对于输出的3K通道,其中前2K对应于学习到的偏移量,剩下的K个通道经过sigmoid层获得最终的modulation scalar.
对deformable RoI pooling进行调制的思路类似,对于输入的RoI,RoI pooling会将其分成K个bin,在每个bin中使用均匀空间间隔的网格进行采样。随后将采样点取均值作为bin的输出,同样△pk和△mk代表学习的偏移量和modulation scalar,nk表示grid中包含多少cell,最终每个k位置的输出为:
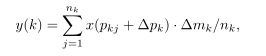
RoI pooling后经过两层1024维度的fc层,随后在经过一层额外的fc层产生3K个通道的输出,依旧对应于2K偏移量和1Kmodulation scalar。
Part C R-CNN Feature Mimicking
诚如Fig2展示的结果,每一个RoI分类节点的错误显著性区域都可能会超出RoI范围,不管是在常规卷积还是在可变卷积中都存在这种情况,因此RoI以外的区域可能会影响提取到的图像特征最终影响目标检测的效果。
在文献[6]中作者指出Faster RCNN检测误差的一大来源是冗余的上下文信息,考虑其他原因(在分类和bbox之间共享较少的特征)作者建议将RCNN和Faster RCNN的分类得分结合起来,作为最终的检测分数。因为RCNN的分类分数更关注于输入RoI裁剪后的结果,因此两者合并有助于缓解上下文冗余的问题。但是在训练和推理过程中融合两个网络分支大大减慢了网络的速度。
另一方面,要考虑到Deformable ConvNet强大的适应spatial support region的能力,以及调制机制的使用,仅仅通过将对应bin的modulation scalar设置为0就可以去除冗余的上下文信息。
但是通过本文5.3节的实验显示出即使加入了modulated deformable modules在标准Faster RCNN的训练过程中也无法学到一些表征,本文怀疑是Faster RCNN的损失函数不具备学习这些特征表述的能力,需要在训练过程中加入额外的引导。
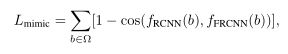
受feature mimicking的启发,本文在Deformable Faster RCNN中引入了feature mimic loss迫使Faster RCNN学习与RCNN从裁剪图像中提取的类似的特征。因为从Fig2可视化的spatial support region,聚焦的特征表述可能并不是背景RoI的最佳选择,因为在背景区域需要考虑更多的上下文信息才能避免假阳性的检测。因此feature mimic loss可以迫使正RoI区域尽可能覆盖GT目标。

Fig 3展示了Deformable Faster R-CNN的网络结构,与Faster RCNN相比,多了一个RCNN分支用于feature mimic。为了进行RoI feature mimic对应的patch裁剪为224x224大小。随后RCNN分支中产生的feature map大小为14x14.随后在最顶部使用deformable RoI pooling层,输入的RoI会覆盖整个图像大小。
最后在经过两层fc层后产生分类结果(C+1)类,C代表前景物体的类别,1则是背景类别。
在两个网路分支顶部都加入了feature mimic loss,计算的是FRCNN与RCNN之间的余弦相似度。
其他细节包括:
RPN会推荐出32个region proposal,RCNN网络最上面使用的是交叉熵损失函数作为分类损失函数,因此损失函数包括feature mimic loss和classification loss以及原有FRCNN的损失函数,前二者的权重为0.1。而在推理阶段仅使用FRCNN网络,而不使用额外的RCNN分支,这样推理阶段就不会引入额外的计算成本了。
Section IV Related work
Part A 可变模型
在深度学习之前就有诸多关于尺度不变特征的研究,包括SIFT,FAST,ORB,DPM等手动设计的特征。Spatial transformer networks是第一个借助深度卷积网络学习空间不变特征的工作,但是不足以应对复杂视觉任务中一些复杂的几何变换。而Deformable ConvNet学习的不是全局参数变换和特征扭曲,而是以局部和密集的方式从可变形卷积模块中学习偏移参数来应对几何变形。也是第一个能够应对复杂形状变换的网络。
本文进一步将DCN网络优化,提升了其建模网络变化的性能,与原始模型相比有了很大提升。
Part B Relation Networks and Attention Modules
早期主要用于NLP和物理系统建模中。其中注意力模块通过从一组元素的聚合特征来影响单个元素,单个元素的权重往往取决于元素之间的特征相似性,因此非常适合捕获长程依赖性以及上下文信息。但这些方法的一大共有问题就是局和权重和聚合操作需要成对的在元素上计算,这就使得计算非常繁琐。本文则是通过引入特殊的注意力机制,将部分元素权重设置为0完成注意力的施加。通过完成偏移量的学习,权重进一步被modulation scheme调控,这样的计算开销是线性的,与整个网络相比是微不足道的。
Part C Spatial Support Manipulation
空洞卷积通过在卷积核中填充0扩大卷积核的大小(spatial support),但是填充的参数是手动选择的且预先设定好的;在Active convolution中卷积核的偏移是通过BP学习的,但是这一偏移是全局共享的;在[40]的multi-path network中对每一个输入的RoI区域都进行RoI pooling这样可以更好的提取多尺度的上下文信息。但是上述方法都存在一个问题,那就是:spatial support都是静态的,无法随着图片内容进行调整。
Part D Effective Receptive Field and Salient Region
为了更好的理解卷积神经网络是如何工作的,已经有诸多研究在理解图像不同区域是如何影响网络预测结果的。最近在关于有效感受野和显著性区域的工作中解释了在感受野中只有一小部分像素对网络预测极其重要。有效的支持区域取决于网络权重和被采样的位置。因此本文通过可视化spatial support 和sampling region更好的理解网络。
Part E Network Mimicking and Distillation
主要用于网络加速和网络压缩。比如通过教师网络的学习引导较为紧凑的学生网络学习对具体特征是如何响应的,从而借助知识蒸馏使得训练后的学生模型可以迁移到更大的网络中。本文则是使用了feature mimic loss,通过模仿RCNN强大的分类能力来帮助网络更加聚焦于前景物体,也确实提升了精度。
Section V Experiemnts
Part A Experiement Settings
数据集:COCO 2017 train set(118K) test set:20K
评价指标: score:bbox 目标检测 mIoU-实例分割
基准模型:Faster RCNN Mask RCNN ,ResNet-50 pretrained on ImageNet
在Mask RCNN中将最后一组3x3卷积层替换为 deformable conv,以及将7x7,14x14的RoI pooling层替换为deformable RoI pooling。
在做feature mimic时feature mimic loss添加在RoI 顶上用来提升分类能力。
训练和验证阶段图片resize到短边为1000x。

Part B Enriched Deformable Modeling
进一步丰富可变卷积后的效果参见Table I,DCNv1是将stage 5的三层3x3卷积替换为可变形卷积,在Faster RCNN和Mask RCNN中分别达到了38%和40.4%的精度。
在DCNv2中首先将更多卷积层(conv3-5)替换为Deformable Conv,因此精度在DCNv1的基础上稳步提升,分别提升了2%、3%;而进一步将conv2替换为可变卷积就没什么明显提升;随后引入调制机制调控可变形卷积模块的幅度值,精度进一步提升0.3%和0.7%。
同时,与网络模型参数相比,使用可变卷积增加的网络参数量是微不足道的。
通过Fig1 (b)©可以看吹使用可变卷积模块后对不同尺度目标的spatial support空间支持更能贴合图像内容。
Table 2展示的是输入图像分辨率为800时的对比结果,结论也是一样的。

Part C RCNN Feature Mimicking
Table 3展示了不同RCNN feature mimic的对比效果,可以看到引入feature mimic在Fater RCNN和Mask RCNN上分别提升了1%和1.4%;尤其对前景物体positive box施加feature mimic尤其有效,如果只对所有negative box进行mimic效果没那么好。
如Fig 2©(d)所示 feature mimic可以帮助网络更聚焦前景物体的特征;而negative box网络则会倾向于提取更多的上下文信息,因此这是使用feature mimic可能没那么有效。
而如果对常规卷积网络进行feature mimic而不加入可变卷积层几乎就没什么提升-对应Fig 2(e),即使加了feature mimic loss也不会聚焦前景物体。可能是因为已经超出了常规网络的学习能力,无法将特征聚焦到前景物体上,因此无法学习。
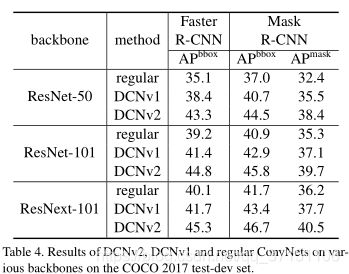
Part D Application on Stronger Backbones
Table 4展示了将可变卷积用在更强大的网络上,如ResNet-101和ResNext-101.依旧是在DCNv1中将stage 5中的3x3卷积替换为可变卷积,在DCNv2中将conv3-5中的卷积进行替换,并且使用modulated模式。可以看到依旧是DCNv2效果最好。
Section VI Conclusioin
虽然可变卷积已经极大的提升了适应物体几何变换的能力,但是其支持空间往往会超出RoI区域影响进一步检测;因此本文提出可变形卷积的改进版本,提升了网络对几何变形的建模能力,也增强了对一致图像区域的聚焦。在COCO数据集上进行的目标检测和实例分割任务都获得了较大提升。
Appendix A1 Error-bounded Image Saliency
在对图像显著性研究的工作中广泛使用下述准则:
![]()
N(I)代表输入图像I经过网络N后的响应,随后对原始图像I施加mask M;随后通过以下损失函数获得图像的显著性图谱。优化后的mask就叫做saliency map。
因此就需要不断优化重建误差:
![]()
最小化M。
但是这一问题很难被优化,本文使用两步法:第一步将support region限制为任意大小的矩形,矩形中心为待解释的节点,且面积初始化为0并逐渐放大,直至满足重建误差时停止放大;第二步在矩形区域内导出超像素级别的support region;最开始所有的超像素都会纳入计算,随后一点一点移除,每次迭代中移除重建误差最小的超像素;直到再移除就会不满足约束条件就停止。

本文将这种方法用于Faster RCNN目标检测任务中,还将特征映射节点和每个RoI检测中的2fc对应的检测节点都进行可视化。使用的重建损失都是mask与原始图像特征向量之间的余弦相似度,误差上限设置为0.1.
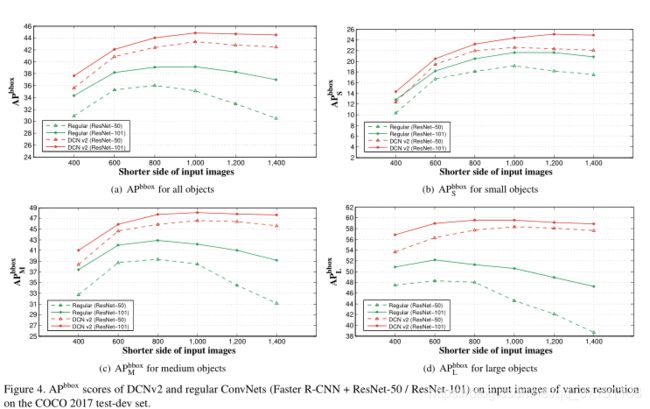
Appendix A2 不同图像分辨率使用DCNv2
Fig 4展示了在不同分辨率的图像中使用常规卷积和DCNv2的对比结果,基础模型是Faster RCNN + Resnet50,Faster RCNN + Resnet 101.不同分辨率图像{400,600,800,1000,1200,1400}中DCNv2均比常规的卷积网络性能优异。尤其在短边<1000x时常规卷积的APbox分数显著下降,而DCNv2则几乎没有影响。


这一现象在较大目标上更为显著,如Fig 5可视化的结果 常规卷积的空间支持区域只能覆盖较小范围,尤其在一些分辨率较高的图像中,但是DCNv2就会根据目标分辨率的大小调节对应的有效采样区域。
Appendix A3 ImageNet Pre-Trained
DCNv2
经过ImageNet预训练后对许多视觉任务都有提升,因此本小节就来探究在ImageNet上预训练后学到的offset和modualtion scalars如何微调后迁移到其他任务上。

Table 6展示了ConvNet、DCNv1、DCNv2的top-1和top-5精度,可以看到DCNv2相比DCNv1也有显著提升,说明DCNv2受益于ImageNet分类数据及提升了适应几何变形的能力。
随后将预训练后的结果迁移到其它视觉任务,包括在PASCAL VOC,ImageNet VID 和COCO数据集上进行目标检测以及在PASCAL VOC数据集上进行实例分割。
基线网络是Faster RCNN、DeepLabv3。

Table7显示了在不同数据集上的实验结果。实验结果发现,预训练对PASCAL VOC数据集上做实例分割和目标检测任务有精度提升,但对COCO目标检测的影响较小,可能是因为COCO数据集更大更具挑战性,从头开始训练学习offset和modulation scarlar就足够了。