PointNet++代码
PointNet++代码
参考:https://blog.csdn.net/weixin_39373480/article/details/88934146
大部分是这个作者的,搬运过来了,添加了一些帮助理解
文章目录
-
- PointNet++代码
-
- utils部分
-
- idx
- farthest_point_sample函数
- query_ball_point函数
utils部分
idx
def index_points(points, idx):
"""
Input:
points: input points data, [B, N, C]
idx: sample index data, [B, D1,...DN]
Return:
new_points:, indexed points data, [B, D1,...DN, C]
"""
device = points.device
B = points.shape[0]
view_shape = list(idx.shape)
view_shape[1:] = [1] * (len(view_shape) - 1)
repeat_shape = list(idx.shape)
repeat_shape[0] = 1
batch_indices = torch.arange(B, dtype=torch.long).to(device).view(view_shape).repeat(repeat_shape)
new_points = points[batch_indices, idx, :]
return new_points

区别:[[[0,1],[0,1]],:]和[[0,1],[0,1]]写法,前者[0,1],[0,1]取得都是0轴的,后者取得是[0,0] 和[0,1] 两个元素
再看batch_indices和idx同型,就类似[[[0,1],[0,1]],[[1,2],[1,2]],:]这种写法了,0,1轴使用多维数组坐标定位,2轴全保存
作用:?将B(0轴)按照[0,0],[1,1]多取了几次,而且对于[[0,0],[1,1]]这样的形状,会按照,这个形状将取到的放入,并对于points含义?
batch_indices例如这样子[[[0,0],[0,0]],[[1,1],[1,1]]],然后idx找到对应的
batch_indices是到B的,也就是说整个复制了repeat_shape份,排列形状和batch_indices一样
这样idx就能取到里面的行了,batch_indices与idx形状一样,idx形状为每个B中S个核心点,每个核心点附近K个邻近点,也就是BxSxK
所以复制了B份又复制了S份,然后取到K个。确实挺复杂的
也就能理解下面这段话了
按照输入的点云数据和索引返回由索引的点云数据。例如points为B × 2048 × 3 B\times 2048\times 3B×2048×3的点云,idx为[ 1 , 333 , 1000 , 2000 ] [1,333,1000,2000][1,333,1000,2000],则返回B个样本中每个样本的第1,333,1000,2000个点组成的B×4×3的点云集。当然如果idx为一个[ B , D 1 , . . . D N ] [B, D1,…DN][B,D1,…DN]维度的,则它会按照idx中的维度结构将其提取成[ B , D 1 , . . . D N , C ] [B, D1,…DN, C][B,D1,…DN,C]。
farthest_point_sample函数
最远点采样函数,其核心就是点集到点集计算的函数,举个简单的栗子,一个临近点间距都是1的一排点(ps:自己把dist放到格子里吧:) ):
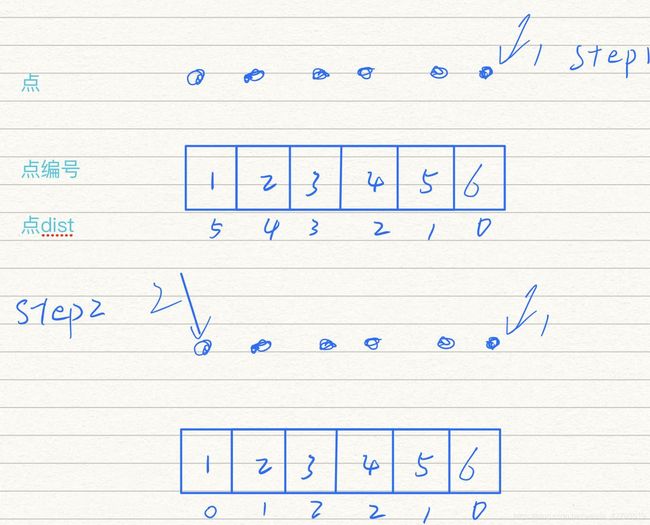
对着代码看看,帮助理解(之前我也没看太明白)
def farthest_point_sample(xyz, npoint):
"""
Input:
xyz: pointcloud data, [B, N, C]
npoint: number of samples
Return:
centroids: sampled pointcloud index, [B, npoint]
"""
device = xyz.device
B, N, C = xyz.shape
centroids = torch.zeros(B, npoint, dtype=torch.long).to(device)
distance = torch.ones(B, N).to(device) * 1e10
farthest = torch.randint(0, N, (B,), dtype=torch.long).to(device)
batch_indices = torch.arange(B, dtype=torch.long).to(device)
for i in range(npoint):
# 更新第i个最远点
centroids[:, i] = farthest
# 取出这个最远点的xyz坐标
centroid = xyz[batch_indices, farthest, :].view(B, 1, 3)
# 计算点集中的所有点到这个最远点的欧式距离
dist = torch.sum((xyz - centroid) ** 2, -1)
# 更新distances,记录样本中每个点距离所有已出现的采样点的最小距离
mask = dist < distance
distance[mask] = dist[mask]
# 从更新后的distances矩阵中找出距离最远的点,作为最远点用于下一轮迭代
farthest = torch.max(distance, -1)[1]
return centroids
query_ball_point函数
获得每个球型领域的nsample个点
- radius:搜索半径
- nsample:个数
- xyz:为所有的点云
- new_xyz:S个球形领域的中心(由最远点采样在前面得出)
def query_ball_point(radius, nsample, xyz, new_xyz):
"""
Input:
radius: local region radius
nsample: max sample number in local region
xyz: all points, [B, N, C]
new_xyz: query points, [B, S, C]
Return:
group_idx: grouped points index, [B, S, nsample]
"""
device = xyz.device
B, N, C = xyz.shape
_, S, _ = new_xyz.shape
group_idx = torch.arange(N, dtype=torch.long).to(device).view(1, 1, N).repeat([B, S, 1])
# sqrdists: [B, S, N] 记录中心点与所有点之间的欧几里德距离
sqrdists = square_distance(new_xyz, xyz)
# 找到所有距离大于radius^2的,其group_idx直接置为N;其余的保留原来的值
group_idx[sqrdists > radius ** 2] = N
# 做升序排列,前面大于radius^2的都是N,会是最大值,所以会直接在剩下的点中取出前nsample个点
group_idx = group_idx.sort(dim=-1)[0][:, :, :nsample]
# 考虑到有可能前nsample个点中也有被赋值为N的点(即球形区域内不足nsample个点),这种点需要舍弃,直接用第一个点来代替即可
# group_first: [B, S, k], 实际就是把group_idx中的第一个点的值复制为了[B, S, K]的维度,便利于后面的替换
group_first = group_idx[:, :, 0].view(B, S, 1).repeat([1, 1, nsample]) ####这里0应该就是中心点了,因为求dist没有去掉自己吧?
# 找到group_idx中值等于N的点
mask = group_idx == N
# 将这些点的值替换为第一个点的值
group_idx[mask] = group_first[mask]
return group_idx
数组参考:https://blog.csdn.net/forever_wen/article/details/89495480
未完!