pointnet++代码逐行解析(一)——— train_classification
继续巩固PointNet++代码的实现这篇博客,把代码逐行注释一遍!
pointnet++的所有代码和数据集都在github上,Pytorch代码:https://github.com/yanx27/Pointnet2_pytorch
train_classification部分的python代码注释如下:
"""
Author: Benny
Date: Nov 2019
"""
import os
import sys
import torch
import numpy as np
import datetime
import logging
import provider
import importlib
import shutil
import argparse
from pathlib import Path
from tqdm import tqdm
from data_utils.ModelNetDataLoader import ModelNetDataLoader
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
ROOT_DIR = BASE_DIR
sys.path.append(os.path.join(ROOT_DIR, 'models'))
def parse_args():
'''PARAMETERS'''
parser = argparse.ArgumentParser('training')
parser.add_argument('--use_cpu', action='store_true', default=False, help='use cpu mode')
parser.add_argument('--gpu', type=str, default='0', help='specify gpu device')
parser.add_argument('--batch_size', type=int, default=24, help='batch size in training')
parser.add_argument('--model', default='pointnet_cls', help='model name [default: pointnet_cls]')
parser.add_argument('--num_category', default=40, type=int, choices=[10, 40], help='training on ModelNet10/40')
parser.add_argument('--epoch', default=200, type=int, help='number of epoch in training')
parser.add_argument('--learning_rate', default=0.001, type=float, help='learning rate in training')
parser.add_argument('--num_point', type=int, default=1024, help='Point Number')
parser.add_argument('--optimizer', type=str, default='Adam', help='optimizer for training')
parser.add_argument('--log_dir', type=str, default=None, help='experiment root')
parser.add_argument('--decay_rate', type=float, default=1e-4, help='decay rate')
parser.add_argument('--use_normals', action='store_true', default=False, help='use normals')
parser.add_argument('--process_data', action='store_true', default=False, help='save data offline')
parser.add_argument('--use_uniform_sample', action='store_true', default=False, help='use uniform sampiling')
return parser.parse_args()
def inplace_relu(m):
classname = m.__class__.__name__
if classname.find('ReLU') != -1:
m.inplace=True
def test(model, loader, num_class=40):
mean_correct = []
class_acc = np.zeros((num_class, 3))
classifier = model.eval()
for j, (points, target) in tqdm(enumerate(loader), total=len(loader)):
if not args.use_cpu:
points, target = points.cuda(), target.cuda()
points = points.transpose(2, 1)
pred, _ = classifier(points)
pred_choice = pred.data.max(1)[1]
for cat in np.unique(target.cpu()):
classacc = pred_choice[target == cat].eq(target[target == cat].long().data).cpu().sum()
class_acc[cat, 0] += classacc.item() / float(points[target == cat].size()[0])
class_acc[cat, 1] += 1
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
class_acc[:, 2] = class_acc[:, 0] / class_acc[:, 1]
class_acc = np.mean(class_acc[:, 2])
instance_acc = np.mean(mean_correct)
return instance_acc, class_acc
def main(args):
def log_string(str):
logger.info(str)
print(str)
'''HYPER PARAMETER'''
os.environ["CUDA_VISIBLE_DEVICES"] = args.gpu
'''CREATE DIR'''
timestr = str(datetime.datetime.now().strftime('%Y-%m-%d_%H-%M'))
exp_dir = Path('./log/')
exp_dir.mkdir(exist_ok=True)
exp_dir = exp_dir.joinpath('classification')
exp_dir.mkdir(exist_ok=True)
if args.log_dir is None:
exp_dir = exp_dir.joinpath(timestr)
else:
exp_dir = exp_dir.joinpath(args.log_dir)
exp_dir.mkdir(exist_ok=True)
checkpoints_dir = exp_dir.joinpath('checkpoints/')
checkpoints_dir.mkdir(exist_ok=True)
log_dir = exp_dir.joinpath('logs/')
log_dir.mkdir(exist_ok=True)
'''LOG'''
args = parse_args()
logger = logging.getLogger("Model")
logger.setLevel(logging.INFO)
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
file_handler = logging.FileHandler('%s/%s.txt' % (log_dir, args.model))
file_handler.setLevel(logging.INFO)
file_handler.setFormatter(formatter)
logger.addHandler(file_handler)
log_string('PARAMETER ...')
log_string(args)
'''DATA LOADING'''
log_string('Load dataset ...')
data_path = 'data/modelnet40_normal_resampled/'
#训练集:9843个样本 shuffle为True为打乱
train_dataset = ModelNetDataLoader(root=data_path, args=args, split='train', process_data=args.process_data)
test_dataset = ModelNetDataLoader(root=data_path, args=args, split='test', process_data=args.process_data)
trainDataLoader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, num_workers=10, drop_last=True)
testDataLoader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, num_workers=10)
'''MODEL LOADING''' # 分类类别数目
num_class = args.num_category
model = importlib.import_module(args.model)
shutil.copy('./models/%s.py' % args.model, str(exp_dir))
shutil.copy('models/pointnet2_utils.py', str(exp_dir))
shutil.copy('./train_classification.py', str(exp_dir))
classifier = model.get_model(num_class, normal_channel=args.use_normals)
criterion = model.get_loss()
classifier.apply(inplace_relu)
if not args.use_cpu:
classifier = classifier.cuda()
criterion = criterion.cuda()
try:
checkpoint = torch.load(str(exp_dir) + '/checkpoints/best_model.pth')
start_epoch = checkpoint['epoch']
classifier.load_state_dict(checkpoint['model_state_dict'])
log_string('Use pretrain model')
except:
log_string('No existing model, starting training from scratch...')
start_epoch = 0
# 优化器
if args.optimizer == 'Adam':
optimizer = torch.optim.Adam(
classifier.parameters(),
lr=args.learning_rate,
betas=(0.9, 0.999),
eps=1e-08,
weight_decay=args.decay_rate
)
else:
optimizer = torch.optim.SGD(classifier.parameters(), lr=0.01, momentum=0.9)
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=20, gamma=0.7)
global_epoch = 0
global_step = 0
best_instance_acc = 0.0
best_class_acc = 0.0
'''TRANING'''
logger.info('Start training...')
for epoch in range(start_epoch, args.epoch):
log_string('Epoch %d (%d/%s):' % (global_epoch + 1, epoch + 1, args.epoch))
mean_correct = []
classifier = classifier.train()
# optimizer.step()通常用在每个mini-batch之中,而sheduler,step()通常用在epoch里面
# 但也不是绝对的,可以根据具体的需求来做
# 只有用了optimizer,step(),模型才回更新,而scheduler.step()是对lr进行调整
scheduler.step()
for batch_id, (points, target) in tqdm(enumerate(trainDataLoader, 0), total=len(trainDataLoader), smoothing=0.9):
optimizer.zero_grad()
#点云数据预处理;数据增强
points = points.data.numpy()
points = provider.random_point_dropout(points)
points[:, :, 0:3] = provider.random_scale_point_cloud(points[:, :, 0:3])
points[:, :, 0:3] = provider.shift_point_cloud(points[:, :, 0:3])
points = torch.Tensor(points)
points = points.transpose(2, 1)
if not args.use_cpu:
points, target = points.cuda(), target.cuda()
#训练分类器
pred, trans_feat = classifier(points)
loss = criterion(pred, target.long(), trans_feat)
pred_choice = pred.data.max(1)[1]
correct = pred_choice.eq(target.long().data).cpu().sum()
mean_correct.append(correct.item() / float(points.size()[0]))
loss.backward()#反向传播(梯度计算)
optimizer.step()#更新权重
global_step += 1
train_instance_acc = np.mean(mean_correct)
log_string('Train Instance Accuracy: %f' % train_instance_acc)
#性能评估
with torch.no_grad():
instance_acc, class_acc = test(classifier.eval(), testDataLoader, num_class=num_class)
if (instance_acc >= best_instance_acc):
best_instance_acc = instance_acc
best_epoch = epoch + 1
if (class_acc >= best_class_acc):
best_class_acc = class_acc
log_string('Test Instance Accuracy: %f, Class Accuracy: %f' % (instance_acc, class_acc))
log_string('Best Instance Accuracy: %f, Class Accuracy: %f' % (best_instance_acc, best_class_acc))
if (instance_acc >= best_instance_acc):
logger.info('Save model...')
savepath = str(checkpoints_dir) + '/best_model.pth'
log_string('Saving at %s' % savepath)
state = {
'epoch': best_epoch,
'instance_acc': instance_acc,
'class_acc': class_acc,
'model_state_dict': classifier.state_dict(),
'optimizer_state_dict': optimizer.state_dict(),
}
torch.save(state, savepath) #保存网络模型
global_epoch += 1
logger.info('End of training...')
if __name__ == '__main__':
args = parse_args()
main(args)

逐行解析开始!
第一句:BASE_DIR = os.path.dirname(os.path.abspath(file))
file_
file_ 是模块文件(即 .py 文件)的一个属性,返回当前模块文件所在的路径,例如在 E 盘下,file_ 是模块文件(即 .py 文件)的一个属性,返回当前模块文件所在的路径,例如在 E 盘下,
print(__file__)
# 运行结果:
E:/PythonProject/test.py
os.path.abspath(path)
os.path.abspath() 是 os 模块当中的一个函数,这个函数接收一个 path 路径对象,返回 path 标准化的绝对路径。
在 Linux 系统中,路径分隔符为斜杠 “/”,在 Windows 系统下,路径分隔符为反斜杠 “\” 。
print(os.path.abspath(__file__))
# 运行结果:
E:\PythonProject\test.py
os.path.dirname()
os.path.dirname() 是 os 模块当中的一个函数,这个函数接收一个 path 路径对象,返回路径 path 的父目录名称。
这是将 path 传入函数 split() 之后,返回的一对值中的第一个元素。
os.path.split(path)
- 将路径 path 拆分为一对,即 (head, tail),其中,tail 是路径的最后一部分,而 head 里是除最后部分外的所有内容。
- tail 部分不会包含斜杠,如果 path 以斜杠结尾,则 tail 将为空。
- 如果 path 中没有斜杠,head 将为空。
- 如果 path 为空,则 head 和 tail 均为空。
- head 末尾的斜杠会被去掉,除非它是根目录(即它仅包含一个或多个斜杠)。
- 简单地说 os.path.split(path) 的作用就是返回 path 的上级目录。
# os.path.dirname() 调用的时候调用 os.path.split()
print(os.path.split(os.path.abspath(__file__)))
print(os.path.dirname(os.path.abspath(__file__)))
#运行结果:
('E:\\PythonProject', 'test.py')
E:\PythonProject
第二句:sys.path.append(os.path.join(ROOT_DIR, ‘models’))
sys.path.append():
当我们导入一个模块时:import xxx,默认情况下python解析器会搜索当前目录、已安装的内置模块和第三方模块,搜索路径存放在sys模块的path中:
import sys
sys.path
##输出
['d:\\program\\anaconda3\\envs\\learn_py36\\python36.zip',
'd:\\program\\anaconda3\\envs\\learn_py36\\DLLs',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib',
'd:\\program\\anaconda3\\envs\\learn_py36',
'',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib\\site-packages',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib\\site-packages\\win32',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib\\site-packages\\win32\\lib',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib\\site-packages\\Pythonwin',
'd:\\program\\anaconda3\\envs\\learn_py36\\lib\\site-packages\\IPython\\extensions',
'C:\\Users\\DELL\\.ipython']
第一句:os.path.exists():
os.path.exists():
os即operating system(操作系统),Python 的 os 模块封装了系统的文件和文件路径。
os.path模块主要用于文件的属性获取,exists是“存在”的意思,所以顾名思义,os.path.exists()就是判断括号里的文件是否存在的意思,括号内的可以是文件路径。对于系统内的所有文件及其路径,都可以进行判断。
返回结果为:True或者False
os.path.join():
os.path.join(“父集”,“子集”)
返回的结果为:
父集\子集’
含义为把“子集”添加到“父集”路径之后。
第三句: parser = argparse.ArgumentParser(‘training’)
parser = argparse.ArgumentParser(‘training’)
argparse是一个Python模块:命令行选项、参数和子命令解析器
argparse模块可以让人轻松编写用户友好的命令行接口。程序定义它需要的参数。然后argparser将弄清
是在深度学习中管理超参数的好办法
1.首先创建解析器
使用 argparse 的第一步是创建一个 ArgumentParser 对象:
parser = argparse.ArgumentParser(description='PyTorch MNIST Example') # 创建对象
ArgumentParser 对象包含将命令行解析成 Python 数据类型所需的全部信息。
描述description
大多数对 ArgumentParser 构造方法的调用都会使用 description= 关键字参数。这个参数简要描述这个程度做什么以及怎么做。在帮助消息中,这个描述会显示在命令行用法字符串和各种参数的帮助消息之间。
2、添加参数
给一个 ArgumentParser 添加程序参数信息是通过调用 add_argument() 方法完成的。通常,这些调用指定 ArgumentParser 如何获取命令行字符串并将其转换为对象。这些信息在 parse_args() 调用时被存储和使用。例如
parser.add_argument('--batch-size', type=int, default=32, metavar='N', help='input batch size for training (default: 64)')
parser.add_argument('--test-batch-size', type=int, default=32, metavar='N',help='input batch size for testing (default: 1000)')
add_argument() 方法定义如何解析命令行参数:
add_argument() 方法定义如何解析命令行参数
ArgumentParser.add_argument(name or flags...[, action][, nargs][, const][, default][, type][, choices][, required][, help][, metavar][, dest])
每个参数解释如下:
name or flags - 选项字符串的名字或者列表,例如 foo 或者 -f, --foo。
action - 命令行遇到参数时的动作,默认值是 store。
store_const,表示赋值为const;
append,将遇到的值存储成列表,也就是如果参数重复则会保存多个值;
append_const,将参数规范中定义的一个值保存到一个列表;
count,存储遇到的次数;此外,也可以继承 argparse.Action 自定义参数解析;
nargs - 应该读取的命令行参数个数,可以是具体的数字,或者是?号,当不指定值时对于 Positional argument 使用 default,对于 Optional argument 使用 const;或者是 * 号,表示 0 或多个参数;或者是 + 号表示 1 或多个参数。
const - action 和 nargs 所需要的常量值。
default - 不指定参数时的默认值。
type - 命令行参数应该被转换成的类型。
choices - 参数可允许的值的一个容器。
required - 可选参数是否可以省略 (仅针对可选参数)。
help - 参数的帮助信息,当指定为 argparse.SUPPRESS 时表示不显示该参数的帮助信息.
metavar - 在 usage 说明中的参数名称,对于必选参数默认就是参数名称,对于可选参数默认是全大写的参数名称.
dest - 解析后的参数名称,默认情况下,对于可选参数选取最长的名称,中划线转换为下划线.
3.解析参数
ArgumentParser 通过 parse_args() 方法解析参数。它将检查命令行,把每个参数转换为适当的类型然后调用相应的操作。在大多数情况下,这意味着一个简单的 Namespace 对象将从命令行解析出的属性构建:
args = parser.parse_args()
4.方便使用定义好的超参数
if args.cuda:
torch.cuda.manual_seed(args.seed)
第四句:
def inplace_relu(m):
classname = m.class.name
if classname.find(‘ReLU’) != -1:
m.inplace=True
在用pytorch实现一个tensorflow project的时候遇到了GPU显存超出 (out of memory) 的问题,有没有什么优化方法?答案就是这边这几句。
没整明白,整体也像是初始化内容。
在深度神经网络中,通常使用一种叫修正线性单元(Rectified linear unit,ReLU)作为神经元的激活函数。ReLU起源于神经科学的研究:2001年,Dayan、Abott从生物学角度模拟出了脑神经元接受信号更精确的激活模型,首先,我们来看一下ReLU激活函数的形式,如下图:
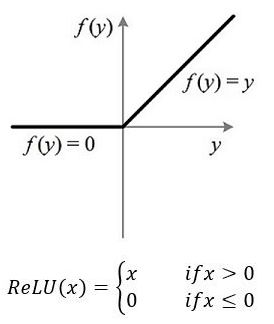
如果不适用激励函数,那么在这种情况下每一层的输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(perceptron)了
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了,不再是输入的线性组合,可以逼近任意函数,最早的想法是用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入。
第五句:
def test(model, loader, num_class=40):
mean_correct = []
class_acc = np.zeros((num_class, 3))
classifier = model.eval()
这句比较复杂,慢慢理解:
1、Dropout和BN(Batch Normalization)(层归一化)详解
无论是机器学习,还是深度学习,模型过拟合是很常见的问题,解决手段无非是两个层面,一个是算法层面,一个是数据层面。数据层面一般是使用数据增强手段,算法层面不外乎是:正则化、模型集成、earlystopping、dropout、BN等,重点详细讲解一下dropout和BN。
Dropout
dropout 是指在深度学习网络的训练过程中,按照一定的概率将一部分神经网络单元暂时从网络中丢弃,相当于从原始的网络中找到一个更瘦的网络。

Dropout具体工作流程:
假设我们要训练这样一个神经网络:
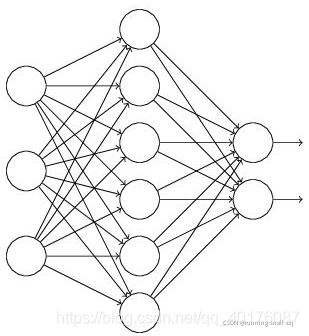
输入是x输出是y,正常的流程是:我们首先把x通过网络前向传播,然后把误差反向传播以决定如何更新参数让网络进行学习。使用Dropout之后,过程变成如下:(1)首先随机(临时)删掉网络中一半的隐藏神经元,输入输出神经元保持不变(图中虚线为部分临时被删除的神经元):

然后把输入x通过修改后的网络前向传播,然后把得到的损失结果通过修改的网络反向传播。一小批训练样本执行完这个过程后,在没有被删除的神经元上按照随机梯度下降法更新对应的参数(w,b)。
然后继续重复这一过程:. 恢复被删掉的神经元(此时被删除的神经元保持原样,而没有被删除的神经元已经有所更新). 从隐藏层神经元中随机选择一个一半大小的子集临时删除掉(备份被删除神经元的参数)。. 对一小批训练样本,先前向传播然后反向传播损失并根据随机梯度下降法更新参数(w,b) (没有被删除的那一部分参数得到更新,删除的神经元参数保持被删除前的结果)。不断重复这一过程。
为什么dropout可以防止过拟合?
在某种程度上,dropout相当于模型融合。dropout工作中,每次随机丢弃一
- 部分神经元,每次丢弃都是随机的,不一样,相当于每次形成的网络结构都不一样,更新的参数都不一样,最后的预测结果类似于多个网络模型的集成的结果;
- dropout随机丢弃一部分神经元,减少了网络结构中的需要更新的参数,有利于减少过拟合;
- dropout随机丢弃一部分神经元,相当于这部分神经元对应的特征直接舍弃了,可以理解成从所有特征中挑选了一部分特征进行训练,每次选的特征集还不一样,这就是类似于RF中的列采样了,增强了模型的泛化能力,减少过拟合;
深度学习中的归一化(BN、LN、IN、GN)
为什么要归一化?
神经网络学习过程的本质就是为了学习数据分布,如果我们没有做归一化处理,那么每一批次训练数据的分布不一样,从大的方向上看,神经网络则需要在这多个分布中找到平衡点,从小的方向上看,由于每层网络输入数据分布在不断变化,这也会导致每层网络在找平衡点,显然,神经网络就很难收敛了。当然,如果我们只是对输入的数据进行归一化处理(比如将输入的图像除以255,将其归到0到1之间),只能保证输入层数据分布是一样的,并不能保证每层网络输入数据分布是一样的,所以也需要在神经网络的中间层加入归一化处理。神经网络学习过程本质上就是为了学习数据分布,如果训练数据与测试数据的分布不同,网络的泛化能力就会严重降低。
四种归一化
在深度学习中,有多种归一化,接下来,我们先用一个示意图来形象的表现BN、LN、IN和GN的区别,在输入图片的维度为(NCHW)中,HW是被合成一个维度,这个是方便画出示意图,C和N各占一个维度。
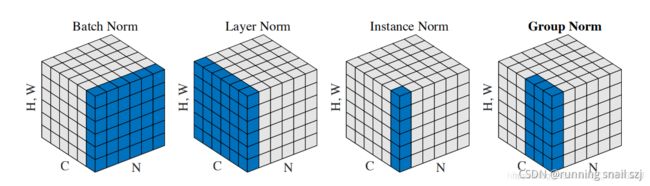
Batch Normalization
- 1.BN的计算就是把每个通道的NHW单独拿出来归一化处理
- 2.针对每个channel我们都有一组γ,β,所以可学习的参数为2*C
- 3.当batch size越小,BN的表现效果也越不好,因为计算过程中所得到的均值和方差不能代表全局
Layer Normalizaiton
- 1.LN的计算就是把每个CHW单独拿出来归一化处理,不受batchsize 的影响
- 2.常用在RNN网络,但如果输入的特征区别很大,那么就不建议使用它做归一化处理
Instance Normalization
- 1.IN的计算就是把每个HW单独拿出来归一化处理,不受通道和batchsize 的影响
- 2.常用在风格化迁移,但如果特征图可以用到通道之间的相关性,那么就不建议使用它做归一化处理
Group Normalizatio
- 1.GN的计算就是把先把通道C分成G组,然后把每个gHW单独拿出来归一化处理,最后把G组归一化之后的数据合并成CHW
- 2.GN介于LN和IN之间,当然可以说LN和IN就是GN的特列,比如G的大小为1或者为C
为什么BN可以缓解过拟合?
在训练中,BN的使用使得一个mini-batch中的所有样本都被关联在了一起,因此网络不会从某一个训练样本中生成确定的结果。这句话什么意思呢?意思就是同样一个样本的输出不再仅仅取决于样本本身,也取决于跟这个样本属于同一个mini-batch的其它样本。同一个样本跟不同的样本组成一个mini-batch,它们的输出是不同的(仅限于训练阶段,在inference阶段是没有这种情况的)。我把这个理解成一种数据增强:同样一个样本在超平面上被拉扯,每次拉扯的方向的大小均有不同。不同于数据增强的是,这种拉扯是贯穿数据流过神经网络的整个过程的,意味着神经网络每一层的输入都被数据增强处理了。
下一步再分析:
model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别
model.train()
如果模型中有BN层(Batch Normalization)和 Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
model.eval()
不启用 Batch Normalization 和 Dropout。
如果模型中有BN层(Batch Normalization)和Dropout,在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
训练完train样本后,生成的模型model要用来测试样本。在model(test)之前,需要加上model.eval(),否则的话,有输入数据,即使不训练,它也会改变权值。这是model中含有BN层和Dropout所带来的的性质。
在做one classification的时候,训练集和测试集的样本分布是不一样的,尤其需要注意这一点。
综上,model.train()和model.eval()区别:
train():启用 BatchNormalization 和 Dropout
eval():不启用 BatchNormalization 和 Dropout,保证BN和dropout不发生变化,pytorch框架会自动把BN和Dropout固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层影响结果。
在利用原始.pth模型进行前向推理之前,一定要先进行model.eval()操作,不启用 BatchNormalization 和 Dropout。