Tensorflow之TFRecord的原理和使用心得
作者|对白
出品|公众号:对白的算法屋
大家好,我是对白。
目前,越来越多的互联网公司内部都有自己的一套框架去训练模型,而模型训练时需要的数据则都保存在分布式文件系统(HDFS)上。Hive作为构建在HDFS上的一个数据仓库,它本质上可以看作是一个翻译器,可以将HiveSQL语句翻译成MapReduce程序或Spark程序,因此模型需要的数据例如csv/libsvm文件都会保存成Hive表并存放在HDFS上,那么问题就来了,如何大规模地把HDFS中的数据直接喂到Tensorflow中呢?
Tensorflow提供了一种解决方法:
spark-tensorflow-connector,支持将spark DataFrame格式数据直接保存为TFRecords格式数据,接下来就带大家了解一下TFRecord的原理、构成和如何生成TFRecords文件。
TFRcord介绍
TFRecord是Tensorflow训练和推断标准的数据存储格式之一,将数据存储为二进制文件(二进制存储具有占用空间少,拷贝和读取(from disk)更加高效的特点),而且不需要单独的标签文件了,其本质是一行行字节字符串构成的样本数据。
一条TFRecord数据代表一个Example,一个Example就是一个样本数据,每个Example内部由一个字典构成,每个key对应一个Feature,key为字段名,Feature为字段名所对应的数据,Feature有三种数据类型:ByteList、FloatList,Int64List。
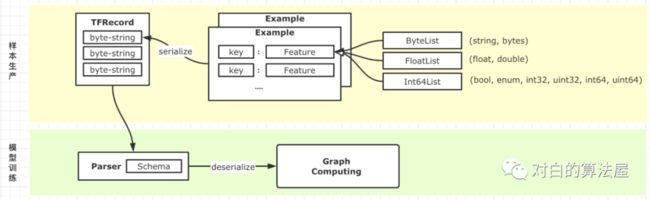
它实质上是由protobuf定义的一种数据协议,其中tensorflow提供了两种Example表示形式 Example和SequenceExample。它的定义代码位于:
[tensroflow/core/example/example.proto & feature.proto]。
Example和SequenceExample的定义
message Example {
Features features = 1;
};
message SequenceExample {
Features context = 1;
FeatureLists feature_lists = 2;
};
message Features {
// Map from feature name to feature.
map feature = 1;
};
// Containers for non-sequential data.
message Feature {
// Each feature can be exactly one kind.
oneof kind {
BytesList bytes_list = 1;
FloatList float_list = 2;
Int64List int64_list = 3;
}
};
// Containers for sequential data.
//
// A FeatureList contains lists of Features. These may hold zero or more
// Feature values.
//
// FeatureLists are organized into categories by name. The FeatureLists message
// contains the mapping from name to FeatureList.
//
message FeatureList {
repeated Feature feature = 1;
};
message FeatureLists {
// Map from feature name to feature list.
map feature_list = 1;
};
我们这里以最常用的Example来进行解释。从图中可以看到,在样本生产环节,每个Example内部由一个dict构成,每个key(string)对应着一个Feature结构,这个Feature结构有三种具体形式,分别是ByteList,FloatList,Int64List三种。这三种形式便可以承载string,bytes,float,double,int,long等多种样本结构,并且基于list的表示,使得我们既可以表达scalar,也可以表达vector类型的数据(注意如果想要将一个matrix保存到到一个Feature内,其值需要时按照Row-Major拍平的1-D array, 行列数据需使用额外字段保存,方便反序列化)。
这里需要注意的是,我们在序列化的时候,并未将格式信息序列化进去,实质上,序列化后的,每条tfrecord中的数据,只具有以下数据:
TFRecord中每条数据的格式:
uint64 length
uint32 masked_crc32_of_length
byte data[length]
uint32 masked_crc32_of_data
因此我们可以看出来,TFRecord并不是一个self-describing的格式,也就是说,tfrecord的write和read都需要额外指明schema。从上图我们也能看出来,在实际训练的时候,样本都需要经过一个知晓了Schema的Parser来进行解析,然后才能传递给Tensorflow进行实际的训练。
注:这里只展示了CTR场景常使用的Example,当然也有图像等场景需要使用SequenceExample进行一些样本的结构化表达,这里不做展开。根据官方文档来看,SequenceExample主要是使用在时序特征和视频特征。其中context字段描述的是和当期时间和特征不相关的共性数据,而feature_list则持有和时间或者视频帧相关的数据。感兴趣可以参考youtube-8M这个数据集中关于样本数据的表示。
TFRecord的生成(小规模)
TFRecord的生成=Example序列化+写入TFRecord文件
构建Example时需要指定格式信息(字典)key是特征,value是BytesList/FloatList/Int64List值,但Example序列化时并未将格式信息序列化进去,因此读取TFRecord文件需要额外指明schema。
每个Example会序列化成字节字符串并写入TFRecord文件中,代码如下:
import tensorflow as tf
# 回忆上一小节介绍的,每个Example内部实际有若干种Feature表达,下面
# 的四个工具方法方便我们进行Feature的构造
def _bytes_feature(value):
return tf.train.Feature(bytes_list=tf.train.BytesList(value=[value]))
def _float_feature(value):
return tf.train.Feature(float_list=tf.train.FloatList(value=[value]))
def _int64_feature(value):
return tf.train.Feature(int64_list=tf.train.Int64List(value=[value]))
def _int64list_feature(value_list):
return tf.train.Feature(int64_list=tf.train.Int64List(value=value_list))
# Example序列化成字节字符串
def serialize_example(user_id, city_id, app_type, viewd_pois, avg_paid, comment):
# 注意我们需要按照格式来进行数据的组装,这里的dict便按照指定Schema构造了一条Example
feature = {
'user_id': _int64_feature(user_id),
'city_id': _int64_feature(city_id),
'app_type': _int64_feature(app_type),
'viewd_pois': _int64list_feature(viewd_pois),
'avg_paid': _float_feature(avg_paid),
'comment': _bytes_feature(comment),
}
# 调用相关api将Example序列化为字节字符串
example_proto = tf.train.Example(features=tf.train.Features(feature=feature))
return example_proto.SerializeToString()
# 样本的生产,这里展示了将2条样本数据写入到了TFRecord文件中
def write_demo(filepath):
with tf.python_io.TFRecordWriter(filepath) as writer:
writer.write(serialize_example(1, 10, 1, [658, 325], 36.3, "yummy food."))
writer.write(serialize_example(2, 20, 2, [897, 568, 126], 89.6, "nice place to have dinner."))
print "write demo data done."
filepath = "testdata.tfrecord"
write_demo(filepath)
由以上代码可知,TFRecord的原理是:将每个样本传给serialize_example函数并输出字节字符串,再通过TFRecordWriter类写入TFRecord文件中,有多少个样本就会生成多少个字节字符串。
TFRecord的生成(大规模)
TFRecord的生成=spark DataFrame格式数据保存为tfrecords格式数据
from pyspark.sql.types import *
def main():
#从hive表中读取数据
df=spark.sql("""
select * from experiment.table""")
#tfrecords保存路径
path = "viewfs:///user/hadoop-hdp/ml/demo/tensorflow/data/tfrecord"
#将spark DataFrame格式数据转换为tfrecords格式数据
df.repartition(file_num).write \
.mode("overwrite") \
.format("tfrecords") \
.option("recordType", "Example")\
.save(path)
if __name__ == "__main__":
main()
TFRecord的读取
在模型训练的时候需要读取TFRecord文件,有三个步骤:
1、首先通过tf.data.TFRecordDataset() API读取TFRecord文件并创建dataset;
2、定义schema;
3、使用tf.parse_single_example() 按照schema解析dataset中每个样本;
schema的意义在于指定每个样本的每一列数据应该用哪一种特征解析函数去解析。
Tensorflow提供了三种解析函数:
-
tf.FixedLenFeature(shape,dtype,default_value):解析定长特征,shape:输入数据形状、dtype:输入数据类型、default_value:默认值;
-
tf.VarLenFeature(dtype):解析变长特征,dtype:输入数据类型;
-
tf.FixedSequenceFeature(shape,dtype,default_value):解析定长序列特征,shape:输入数据形状、dtype:输入数据类型、default_value:默认值;
代码如下:
def read_demo(filepath):
# 定义schema
schema = {
'user_id': tf.FixedLenFeature([], tf.int64),
'city_id': tf.FixedLenFeature([], tf.int64),
'app_type': tf.FixedLenFeature([], tf.int64),
'viewed_pois': tf.VarLenFeature(tf.int64),
'avg_paid': tf.FixedLenFeature([], tf.float32, default_value=0.0),
'comment': tf.FixedLenFeature([], tf.string, default_value=''),
}
# 使用相关api,按照schema解析dataset中的样本
def _parse_function(example_proto):
return tf.parse_single_example(example_proto, schema)
# 读取TFRecord文件来创建dataset
dataset = tf.data.TFRecordDataset(filepath)
#按照schema解析dataset中的每个样本
parsed_dataset = dataset.map(_parse_function)
#创建Iterator并迭代Iterator即可访问dataset中的样本
next = parsed_dataset.make_one_shot_iterator().get_next()
# 这里直接利用session,打印dataset中的样本
with tf.Session() as sess:
while True:
try:
print sess.run(next)
except:
print "out of data"
break
其中,
tf.parse_single_example(
serialized,
features,
name=None,
example_names=None
)
参数:
-
serialized:序列化的Example。
-
features:一个字典,key是特征,value是FixedLenFeature/VarLenFeature/FixedSequenceFeature值。
-
name:此操作的名称(可选)。
-
example_names:(可选)标量字符串张量,关联的名称。
返回:
一个字典,key是特征,value是Tensor或Sparse Tensor值。
对比学习算法交流群
已建立对比学习算法交流群!想要进交流群学习的同学,可以直接加我的微信号:duibai996。加的时候备注一下:昵称+学校/公司。群里聚集了很多学术界和工业界大佬,欢迎一起交流算法心得,日常还可以唠嗑~
关于我
你好,我是对白,清华计算机硕士毕业,现大厂算法工程师,拿过8家大厂算法岗SSP offer(含特殊计划),薪资40+W-80+W不等。
高中荣获全国数学和化学竞赛二等奖。
本科独立创业五年,两家公司创始人,拿过三百多万元融资(已到账),项目入选南京321高层次创业人才引进计划。创业做过无人机、机器人和互联网教育,保研清华后退居股东。
我每周至少更新三篇原创,分享人工智能前沿算法、创业心得和人生感悟。我正在努力实现人生中的第二个小目标,上方关注后可以加我微信交流。
期待你的关注,我们一起悄悄拔尖,惊艳所有~