融合知识图谱的电影推荐系统构建_图谱构建
笔者的论文项目部分分享,主要内容为使用Neo4j构建知识图谱,使用python实现融合知识图谱推荐算法与相关的简单交互界面。
内容脑图如下图:主要学习自项亮的推荐系统实践与唐宇迪的推荐系统实战 其中不足 望多多指正
文章目录
- 1.图数据简介
-
- 1.1.简单介绍
- 1.2Neo4j的优势与应用现状
- 2.电影图谱的构建
-
- 2.1图谱主体的构建
- 2.2.图谱主体关系的构建
1.图数据简介
1.1.简单介绍
属性图、三原图与超图是目前主用在应用的三种图数据库,本实验选用的Neo4j的模型为属性图,属性图的数据模型主要有四种特征。主要为具有节点和关系、关系具有属性、节点具有属性和标签与关系有名称和两个开始、结束的节点。
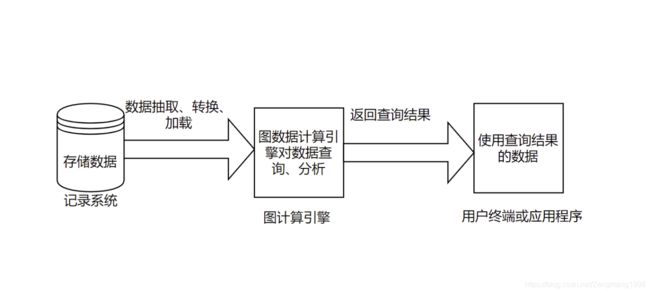
此外,目前运用较多的关系型数据库与Neo4j图数据库都具有的相同点是图数据库也有一个计算引擎存在。可以存储大型的图数据集,是用来实现全局图计算的数据库核心构建[8]。关于图数据的计算引擎流程如下图所示:
目前,开发中使用的主流图数据如下表所示:
| 名称 | Neo4j | ArangoDB | OtientDB | JanusGraph | HugeGraph |
|---|---|---|---|---|---|
| 可用文档 | 很多(成功案例多) | 很多 | 很多 | 很少 | 只有国内文档 |
| 开源 | 社区版开源 | 企业版不开源 | 开源 | 开源 | 开源 |
| 基础语言 | Java、scala | C、c++、JavaScript | Java | Java | c++ |
| 支持编程语言 | .Net Java JavaScript Groovy Clojure PHP Python Ruby Scala …… | C# Clojure Java Ruby…… | C C# C++ Java…… | Clojure Java Python…… | C++ Java PHP Python |
1.2Neo4j的优势与应用现状
相比于其他的图数据库,Neo4j与传统的关系型数据库类似,不需要掌握过深的数学集合理论,也不需要掌握掌握系统的图论知识,只需要了解掌握一定的SQL知识与一定的Cypher语言基础即可上手操作,对新手友好。作为最近几年才发展起来的新兴技术,Neo4j一直紧随大数据时代步伐不断前行,越发凸显出相对于传统关系型数据的强大优势,并且随着选用Neo4j作为需求实现工具的开发者的数量的不断增多,Neo4j的相关使用文档也变着越来越完善与系统化;另外,Neo4j也支持相对较多的编程语言如Python、Java等。综上,笔者最终原Neo4j作为本文知识图谱的实现工具。
面向语义网络的RDF图模型,与面向结构化实体的属性图模型是目前知识图谱的主要应用领域。随着大数据的不断发展及其时代的到来,通过Neo4j实现的属性图由于其可理解性与便捷性正受到越来越多开发者的青睐。
知识图是图数据库的最基本的基础应用方案。 它充分利用其图模型在存储和查询中的优势,电子商务,金融,法律,医疗,智能家居等领域的决策系统,推荐系统,智能问答系统等多个行业都存在知识图谱为其知识信息的身影。图数据库主要被应用处理复杂、可变的网络型数据,其效率比传统关系数据要快出2-3个数量级。 基于图数据库应用程序的优势,越来越多的开发人员和研究人员开始致力于将基于图数据库的知识图应用于推荐领域[。
2.电影图谱的构建
2.1图谱主体的构建
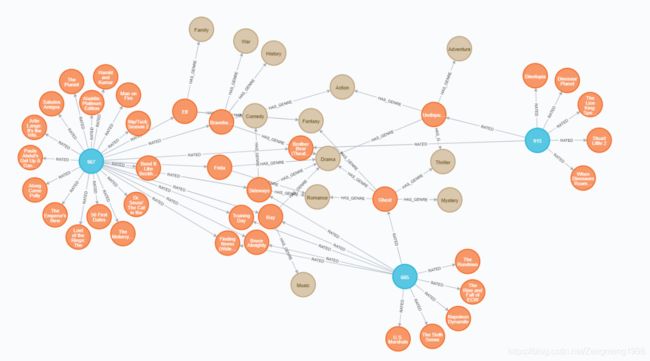
本文电影知识图谱的构建,从TMDB 5000数据集中获取电影信息(电影主题、名称、关键字、制作方),从Netflix数据集中获取用户的行为信息,再以电影的title作为知识图谱的主题,利用从数据中获取的相关信息构建电影主题、评分、关键字等关系三元组,完成电影知识图谱的初步构建,在通过基于余弦相似度完成用户间相似度的计算加入用户间的相似关系,是电影知识图谱的信息更加完整,为下一步推荐系统提供用户的相关知识信息基础。具体在Neo4j图数据库中构建的电影关系如下表所示:
| 关系名 | 三元组内容 | 作用 |
|---|---|---|
| RATED | User_rated—>movie | 向图谱存入电影评分信息 |
| HAS_GENRE | Movie_HAS_GENRE—>GENRE | 向图谱存入电影主题信息 |
| HAS_KEYWORD | Movie_HAS_KEYWORD—>KEY WORD | 向图谱存入电影关键词信息 |
| HAS_PRODUCTOR | Movie_HAS_PRODUCTOR—>PRODUCTOR | 向图谱存入电影制作方信息 |
| SIMILARITY | User SIMILARITY—>User | 向图谱用户间相似度信息 |
其中构建图谱时以TMDB 5000数据集中电影作为知识库主体,构建源码如下:
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_movies.csv" AS csv
CREATE (:Movie {title: csv.title})
""")
2.2.图谱主体关系的构建
完成电影主体构建后,再通过Neo4j三元组的形式构建主体关系,其中评分关系为电影与用户间的知识关系,记录某用户id对某电影的id的评分信息,其关系形式为多对多,构建源码如下:
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_keyword.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (k:Keyword {keyword: csv.keyword})
CREATE (m)-[:HAS_KEYWORD]->(k)
""")
基于此元组得到的电影评分关系实现结果如下图
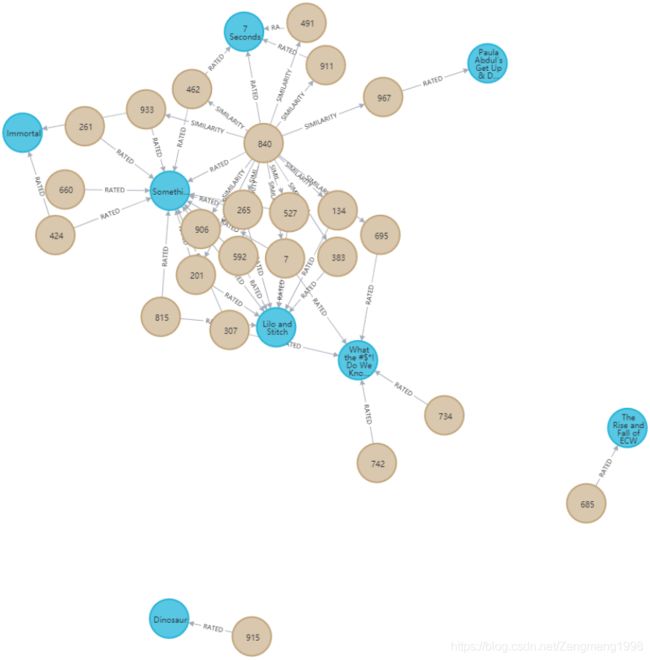
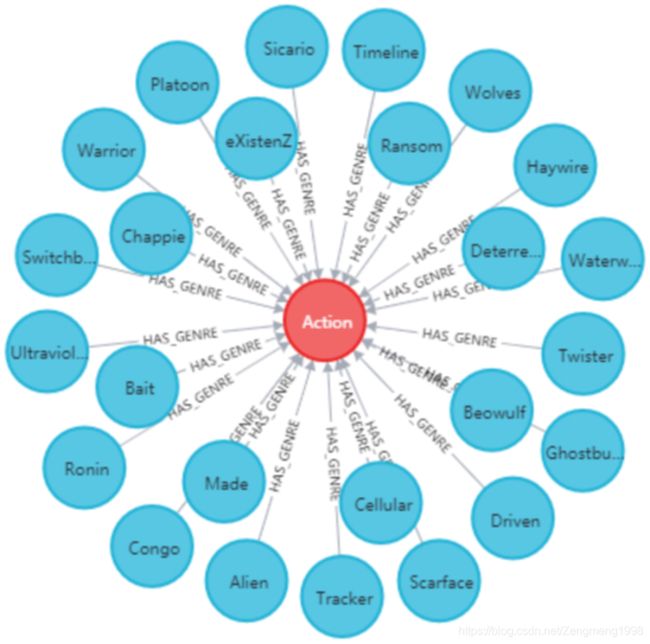
电影主题关系记录的是电影的主题信息,其关系形式为多对多(如电影Congo的电影主题为Action和Thriller),主题关系构建源码如下
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_genre.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (g:Genre {genre: csv.genre})
CREATE (m)-[:HAS_GENRE]->(g)
""")
源码得到的电影主题关系实现结果如下图
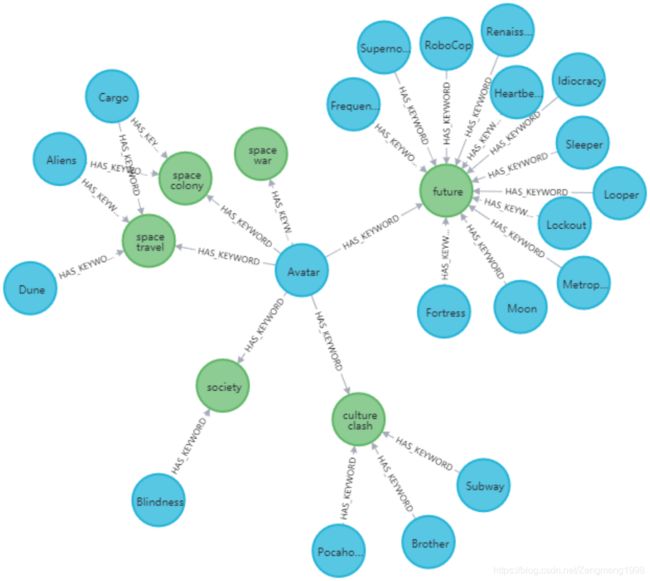
电影图谱的关键词关系主要记录电影的关键词信息,其关键形式为多对多,如电影Avatar的关键词为space war、space colony等,主题为space war的电影有Avatar、Cargo等,关键词关系的构建源码如下
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_keyword.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (k:Keyword {keyword: csv.keyword})
CREATE (m)-[:HAS_KEYWORD]->(k)
""")
得到的电影风格关系实现结果如下图
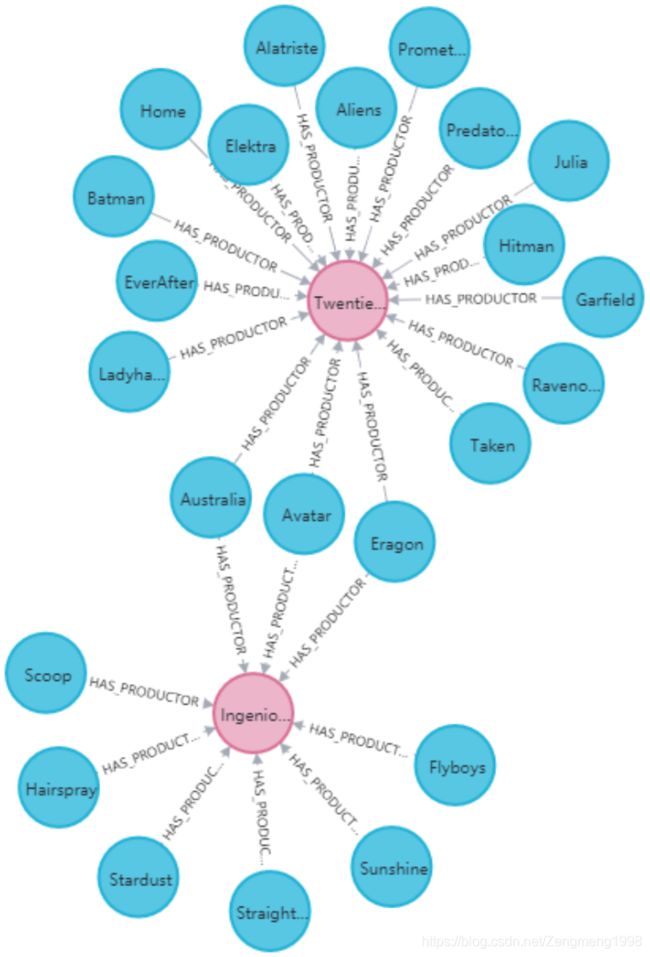
电影图谱的制作方关系主要记录电影的制作方信息,关系形式为多对多(如电影Avatar的制作方为Twentieth Century Fox Film Corporation、Dune Entertainment等,制作方Dune Entertainment制作的电影有Avatar、Prometheus等),制作方关系构建源码如下
session.run("""
LOAD CSV WITH HEADERS FROM "file:///out_productor.csv" AS csv
MERGE (m:Movie {title: csv.title})
MERGE (p:Productor {name: csv.productor})
CREATE (m)-[:HAS_PRODUCTOR]->(p)
""")
得到的电影制作方关系实现结果如下图
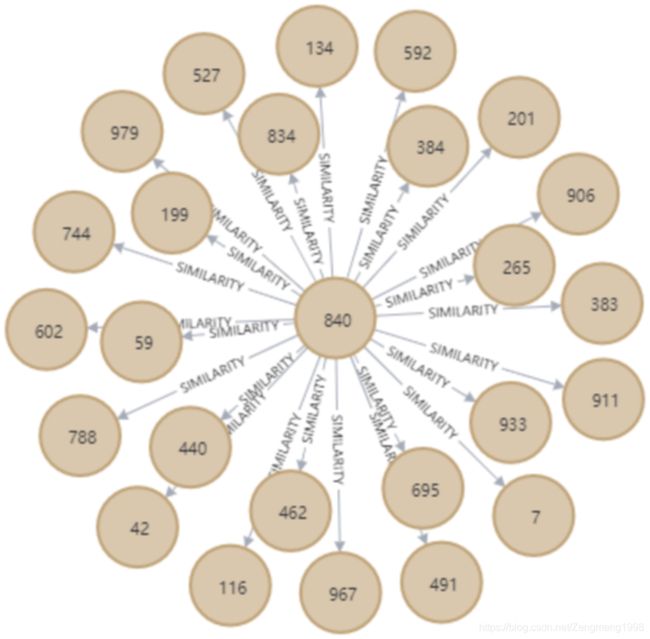
电影图谱的相似度关系是在构建推荐系统时记录的用户与用户之间的相似度信息,关系形式为多对多(比如用户1与用户2的相似度为0.68),构建用户相似关系的部分源码如下
session.run(f"""
MATCH (u1:User {{id : {userid}}})-[r1:RATED]-(m:Movie)-[r2:RATED]-(u2:User)
WITH
u1, u2,
COUNT(m) AS movies_common,
SUM(r1.grading * r2.grading)/(SQRT(SUM(r1.grading^2)) * SQRT(SUM(r2.grading^2))) AS sim
WHERE movies_common >= {movies_common} AND sim > {threshold_sim}
MERGE (u1)-[s:SIMILARITY]-(u2)
SET s.sim = sim
""")
得到的电影观众间相似度关系实现结果如下图
利用TMDB 5000与Netflix数据集获取电影知识信息,以电影为主体添加关系(具体见表)构建电影知识库,使用Neo4j构建得到的知识图谱最终结果果如下图