Python 玩转数据 15 - Pandas 数据处理 拼接 pd.concat() axis join ignore_index verify_integrity
引言
本文主要介绍 Pandas 数据拼接 pd.concat(),更多 Python 进阶系列文章,请参考 Python 进阶学习 玩转数据系列
内容提要:
数据拼接 pd.concat()举例 axis = 0 axis = 1
处理重复索引 ignore_index, verify_integrity
拼接 DataFrames 不同的列 join
数据拼接 pd.concat()
pd.concat( objs, axis=0, join=‘outer’, join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True)
将两个或两个以上的 Pandas 对象 dataframe 或者 series 按某一轴(默认:axis = 0) 拼接在一起, 按行拼接 (axis=0), 按列拼接 (axis=1)
keys 和 names
当表格拼接完成后,就不能判断到底哪些数据是来自于哪一个表了,如果需要保留来源信息,就可以通过keys参数进行设置,而names参数可以给拼接后形成的数据结构添加名字。
串联两个Pandas Series

行拼接:

列拼接:

加上 Keys 和 Names 参数显示出数据来源:
行拼接

列拼接

代码:
import pandas as pd
s1 = pd.Series(['Ann', 'Fred'], index = [1, 2])
s2 = pd.Series (['John', 'Kate'], index = [3, 4])
print("s1:\n{}".format(s1))
print("s2:\n{}".format(s2))
s_concat_along_axis_0 = pd.concat ([s1, s2])
print("s_concat_along_axis_0:\n{}".format(s_concat_along_axis_0))
s_concat_along_axis_1 = pd.concat ([s1, s2], axis=1)
print("s_concat_along_axis_1:\n{}".format(s_concat_along_axis_1))
输出:
s1:
1 Ann
2 Fred
dtype: object
s2:
3 John
4 Kate
dtype: object
s_concat_along_axis_0:
1 Ann
2 Fred
3 John
4 Kate
dtype: object
s_concat_along_axis_1:
0 1
1 Ann NaN
2 Fred NaN
3 NaN John
4 NaN Kate
串联两个 Pandas DataFrames
两个 DataFrame 都是默认的 index, 按行串联时,会有重复的 index

行拼接:

列拼接:

加上 Key 和 names显示数据来源:


代码:
import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
age = [10,20,50]
grade = ['A','B','C']
df1 = pd.DataFrame({'id':idnumber,'fname':fname})
df2 = pd.DataFrame({'age':age,'grade':grade})
df3=pd.DataFrame({'id':[3,4],'age':[30,40]})
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
print("df3:\n{}".format(df3))
df_concat_along_axis_0 = pd.concat([df1, df2, df3], axis = 0,keys=["df1", "df2", "df3"], names=["From", "index"])
df_concat_along_axis_1 = pd.concat([df1, df2, df3], axis = 1,keys=["df1", "df2", "df3"], names=["From", "index"])
print("df_concat_along_axis_0:\n{}".format(df_concat_along_axis_0))
print("df_concat_along_axis_1:\n{}".format(df_concat_along_axis_1))
输出:
df1:
id fname
0 1 Kate
1 2 John
2 5 Eli
df2:
age grade
0 10 A
1 20 B
2 50 C
df3:
id age
0 3 30
1 4 40
df_concat_along_axis_0:
id fname age grade
From index
df1 0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
df2 0 NaN NaN 10.0 A
1 NaN NaN 20.0 B
2 NaN NaN 50.0 C
df3 0 3.0 NaN 30.0 NaN
1 4.0 NaN 40.0 NaN
df_concat_along_axis_1:
From df1 df2 df3
index id fname age grade id age
0 1 Kate 10 A 3.0 30.0
1 2 John 20 B 4.0 40.0
2 5 Eli 50 C NaN NaN
两个 DataFrame 自定义 Index,按行串联时,会有重复的 Index
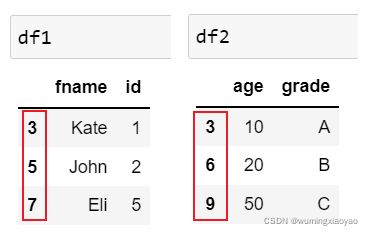

代码:
import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
age = [10,20,50]
grade = ['A','B','C']
df1=pd.DataFrame({'id':idnumber,'fname':fname}, index = [3, 5, 7])
df2= pd.DataFrame({'age':age,'grade':grade}, index = [3, 6, 9])
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
df_concat_along_axis_0 = pd.concat([df1, df2], axis = 0)
df_concat_along_axis_1 = pd.concat([df1, df2], axis = 1)
print("df_concat_along_axis_0:\n{}".format(df_concat_along_axis_0))
print("df_concat_along_axis_1:\n{}".format(df_concat_along_axis_1))
输出:
df1:
id fname
3 1 Kate
5 2 John
7 5 Eli
df2:
age grade
3 10 A
6 20 B
9 50 C
df_concat_along_axis_0:
id fname age grade
3 1.0 Kate NaN NaN
5 2.0 John NaN NaN
7 5.0 Eli NaN NaN
3 NaN NaN 10.0 A
6 NaN NaN 20.0 B
9 NaN NaN 50.0 C
df_concat_along_axis_1:
id fname age grade
3 1.0 Kate 10.0 A
5 2.0 John NaN NaN
6 NaN NaN 20.0 B
7 5.0 Eli NaN NaN
9 NaN NaN 50.0 C
处理重复索引 Duplicate Indices
由上面的例子可以看出pd.concat 会保留索引 indices, 这样会导致重复的索引 indices
pd.concat() 提供几个选项来处理重复的索引:
- 当捕捉到重复的索引时抛出异常
● 验证是否存在重复的索引用verify_integrity = True选项
● 需要 catch 到重复索引的异常 - 忽略索引
● 如果 index 不重要,我们可以忽略掉,用ignore_index = True选项
下面两 DataFrame 为例
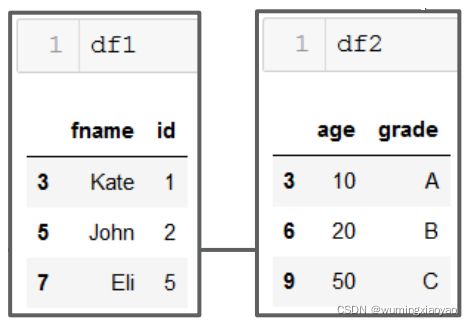
捕获异常:

忽略索引:
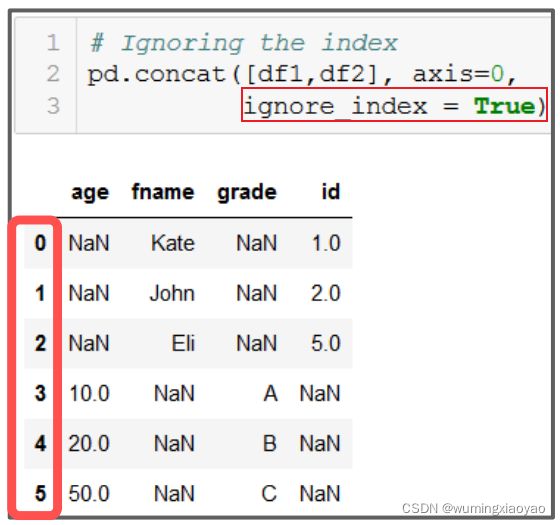
代码:
import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
age = [10,20,50]
grade = ['A','B','C']
df1=pd.DataFrame({'id':idnumber,'fname':fname}, index = [3, 5, 7])
df2= pd.DataFrame({'age':age,'grade':grade}, index = [3, 6, 9])
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
# catch repeat indices
try:
df_concat_along_axis_0 = pd.concat([df1, df2], axis = 0, verify_integrity=True)
except ValueError as e:
print("Value Error: ", e)
# ignore index
df_concat_along_axis_0 = pd.concat([df1, df2], axis = 0, ignore_index=True)
df_concat_along_axis_1 = pd.concat([df1, df2], axis = 1, ignore_index=True)
print("df_concat_along_axis_0:\n{}".format(df_concat_along_axis_0))
print("df_concat_along_axis_1:\n{}".format(df_concat_along_axis_1))
输出:
df1:
id fname
3 1 Kate
5 2 John
7 5 Eli
df2:
age grade
3 10 A
6 20 B
9 50 C
Value Error: Indexes have overlapping values: Int64Index([3], dtype='int64')
df_concat_along_axis_0:
id fname age grade
0 1.0 Kate NaN NaN
1 2.0 John NaN NaN
2 5.0 Eli NaN NaN
3 NaN NaN 10.0 A
4 NaN NaN 20.0 B
5 NaN NaN 50.0 C
df_concat_along_axis_1:
0 1 2 3
3 1.0 Kate 10.0 A
5 2.0 John NaN NaN
6 NaN NaN 20.0 B
7 5.0 Eli NaN NaN
9 NaN NaN 50.0 C
串联 DataFrames 不同的列
对于简单的串联,两个 Pandas 对象正好共享相同的列。然而,现时情况,数据来源不同,可能存在不同的列名。为了处理不同列名情况,pd.concat() 提供了 join = 和 join_axis = 选项。其中 join 参数控制的是外连接还是内连接,默认外连接,保留两个表中的所有信息;如果设置成内连接,拼接结果只保留两个表共有的信息
● 返回两个表的交集 (join = ‘inner’)
● 返回两个表的并集 (join = ‘outer’ 默认)
● 指定返回的集合(如, join_axes = [df2.columns] 注意:新版本的Pandas 已经不支持该选项了)
举例:

join=inner:
行拼接,上下拼接的时候,保留了共有的列信息!
列拼接,左右拼接的时候,保留了共有的行信息!

完整代码:
import pandas as pd
idnumber = [1,2,5]
fname = ['Kate','John','Eli']
fname_2 = ['Kate 2','John 2','Eli 2']
age = [10,20,50]
grade = ['A','B','C']
df1=pd.DataFrame({'id':idnumber,'fname':fname}, index = [3, 5, 7])
df2= pd.DataFrame({'age':age,'grade':grade, 'fname':fname_2}, index = [3, 6, 9])
print("df1:\n{}".format(df1))
print("df2:\n{}".format(df2))
# Intersection: join = inner
df_intesection_axis_0 = pd.concat ([df1, df2], join = 'inner', axis=0, keys=["df1", "df2"], names=["From"])
df_intesection_axis_1 = pd.concat ([df1, df2], join = 'inner', axis=1,keys=["df1", "df2"], names=["From"])
# Union: join = outer
df_union_axis_0 = pd.concat([df1, df2], join = 'outer', axis=0,keys=["df1", "df2"], names=["From"])
df_union_axis_1 = pd.concat([df1, df2], join = 'outer', axis=1,keys=["df1", "df2"], names=["From"])
# Specification: which columns to keep, discard in pandas new version
# df_specification = pd.concat ([df1, df2], join_axes = [df2.columns])
print("df_intesection_axis_0:\n{}".format(df_intesection_axis_0))
print("df_intesection_axis_1:\n{}".format(df_intesection_axis_1))
print("df_union_axis_0:\n{}".format(df_union_axis_0))
print("df_union_axis_1:\n{}".format(df_union_axis_1))
输出:
df1:
id fname
3 1 Kate
5 2 John
7 5 Eli
df2:
age grade fname
3 10 A Kate 2
6 20 B John 2
9 50 C Eli 2
df_intesection_axis_0:
fname
From
df1 3 Kate
5 John
7 Eli
df2 3 Kate 2
6 John 2
9 Eli 2
df_intesection_axis_1:
From df1 df2
id fname age grade fname
3 1 Kate 10 A Kate 2
df_union_axis_0:
id fname age grade
From
df1 3 1.0 Kate NaN NaN
5 2.0 John NaN NaN
7 5.0 Eli NaN NaN
df2 3 NaN Kate 2 10.0 A
6 NaN John 2 20.0 B
9 NaN Eli 2 50.0 C
df_union_axis_1:
From df1 df2
id fname age grade fname
3 1.0 Kate 10.0 A Kate 2
5 2.0 John NaN NaN NaN
6 NaN NaN 20.0 B John 2
7 5.0 Eli NaN NaN NaN
9 NaN NaN 50.0 C Eli 2