知识表示与融入技术前沿进展及应用

作者|李杨[1],李晶阳[1],牛广林[2],唐呈光[1],付彬[1],余海洋[1],孙健[1]
单位|阿里巴巴-达摩院-小蜜Conversational AI团队[1],北京航空航天大学计算机学院[2]

引言
目前,业界公认的人工智能(AI)三个层次为计算智能、感知智能、认知智能。一般来讲,计算智能即快速计算、记忆和储存能力;感知智能,即视觉、听觉、触觉等感知能力,当下十分热门的人脸识别、语音识别即是感知智能,本质上是充分利用深度学习模型对大数据分布的拟合能力;认知智能则更为复杂,包括分析、思考、理解和推理的能力。
随着 AI 技术的不断推进,认知智能的研究也越来越受到重视。而“知识”作为认知智能的核心元素之一,逐渐成为继大数据、算法、算力后,第四个推动人工智能发展的关键要素。

对于 AI 的核心分支——自然语言处理(NLP)而言,要做到精细深度的语义理解,单纯依靠大规模数据标注的解决方案遇到越来越多的阻碍,相反地,知识在语义理解上的作用不断凸显。
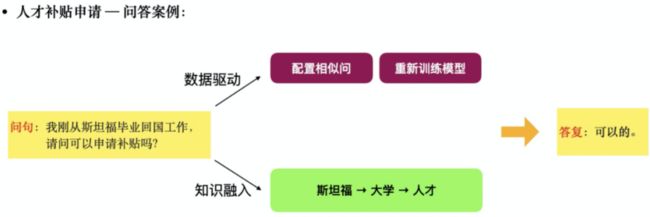
举例来说,对于和“人才工作补贴”相关的问题“我刚从斯坦福毕业回国工作,请问可以申请补贴吗?”,在目前采用传统的语义匹配架构的问答系统中,由于没有关于“斯坦福”的知识,因此往往需要配置若干条相似问数据,重新训练的模型才能给予上述问题正确解答。
而如果模型拥有先验知识 “斯坦福”→“大学”→“人才”,那么其就能很自然的对上述问题给予肯定的答复。因此,利用人类广泛的先验知识为自然语言处理提供先验知识与逻辑支撑,进而构建融入知识的自然语言处理模型,成为越来越热门的研究范式。
从如何利用大规模先验知识增强语义理解的课题出发,结合阿里巴巴云小蜜的业务场景,本文第二部分对知识表示与融入的技术前沿和若干行业应用进行介绍,具体来说主要对知识图谱表示学习和融入知识的预训练语言模型及其在若干场景下的应用介绍,在第三部分,本文介绍了阿里巴巴云小蜜在知识应用上的探索与实践,主要分为三部分:
1. 在基于知识图谱的问答(KBQA)场景下,介绍结合知识图谱表示学习的 KBQA 动态自适应能力;2. 知识图谱表示学习在 Few-Shot 情形下的深入探索;3. 融入行业知识的预训练语言模型的应用实践。


知识表示与融入技术进展
2.1 知识图谱表示学习及应用
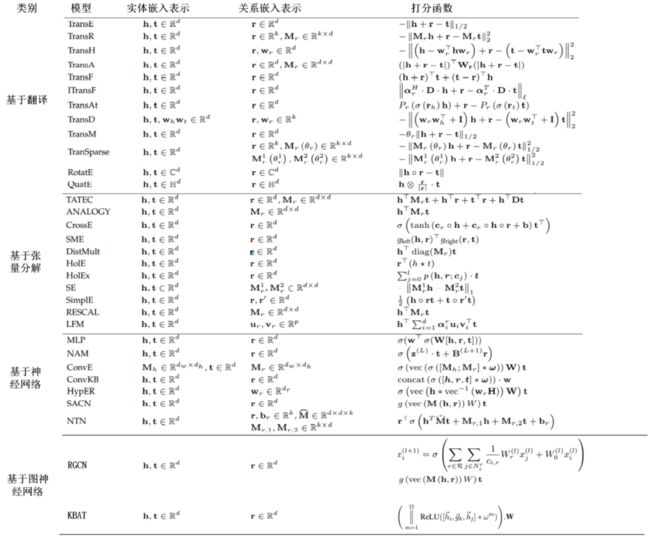
本节主要介绍知识图谱表示学习及其应用。知识图谱表示学习共分为四类:基于翻译的 Trans 系列模型、基于张量分解模型、基于神经网络的模型以及基于图神经网络模型。
知识图谱表示学习的嵌入表示可广泛应用于下游任务如:图谱知识成份相关的预测、实体类别识别、实体消歧等任务,以及非图谱知识成份相关的问答、推荐、关系分类等任务 [1]。本文将以问答和推荐任务为代表,介绍如下几篇经典工作。
2.1.1 知识图谱表示学习
2.1.1.1 基于翻译的模型
将知识图谱中的每个三元组看成是从头实体经过关系到尾实体的翻译过程,不同的基于翻译的模型之间的区别就在于打分函数的设计,经典算法为 TransE 模型 [2]。TransE 模型的原理如下图所示:

由上图可以看出,TransE 的思想就是对头实体向量通过关系的平移操作得到尾实体向量。TransE 模型的打分函数设计为:
![]()
这个打分函数也可以被称为距离函数,用于衡量头实体表示加关系表示与尾实体表示之间的距离,当一个三元组(h, r, t)成立时,这个打分函数应取值为零。基于该打分函数,TransE 模型在训练过程中,采用最大间隔方法的 hinge loss。TransE 的 Loss function 为:

其中,(h, r, t)为知识图谱中存在的一个正例三元组,(h', r', t')为通过随机替换(h, r, t)中的一个元素为另一个实体或关系的负采样方法得到的一个负例三元组。整个 loss function 的优化目标为使得正例三元组和负例三元组的打分之间的距离尽可能更大。基于翻译的知识图谱表示学习模型还包括 TransH, TransR, TransD, TranSparse, TransG, RotatE 等。
2.1.1.2 基于张量分解的模型
一个知识图谱可以看成是一个大的三阶张量,利用张量分解的思想可以将这个大尺寸的三阶张量分解为低维的实体矩阵和低维的关系张量乘积的形式,用以判断每个三元组成立的可能性,典型代表模型为 RESCAL [3]。RESCAL 模型的原理如下图所示:

在三阶张量中的每个位置表示第 i 个实体和第 j 个实体之间是否满足第 k 个关系,利用分解后的低维的实体和关系嵌入表示可以还原出三阶张量中的每个位置上的真值。RESCAL 的打分函数为:
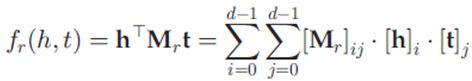
其中,h 和 t 分别为实体关系的嵌入表示,Mr 表示关系的低维张量表示。基于张量分解的知识图谱表示学习模型还包括 DisMult, HolE, ComplEx 等。
2.1.1.3 基于神经网络的模型
对于每个关系,可以用一组神经网络的参数来表示,输入为头实体和尾实体的嵌入表示,输出为当前三元组成立的可能性,经典模型为 NTN [4]。NTN 模型的结构图为:

可以看出,NTN 的整个网络结构包括针对头实体和尾实体的线性映射和双线性映射,激活函数和关系 r 的显式参数表示。NTN 的打分函数为:
![]()
基于神经网络的知识图谱表示学习模型还包括 ConvE, ConvKB 等。
2.1.1.4 基于图神经网络的模型
整体模型为一个 encoder-decoder 架构,encoder 部分通过图卷积神经网络(GCN)将实体的邻域信息进行聚合,来更新实体的表示,decoder 部分用三元组打分函数来对更新后的实体表示和关系表示进行打分并进一步训练参数,经典算法为 RGCN 模型 [5]。RGCN 模型是最早将图卷积神经网络(GCN)引入知识图谱表示学习的研究,模型结构为:

由于知识图谱是一个多关系图数据,因此,RGCN 在使用 GCN 的过程中针对一个实体邻域中的不同关系分别进行聚合操作,encoder 部分中每一层的 GCN 的设计为:

其中,hj 为第 i 个实体的第 j 个领域实体的嵌入表示,r 表示邻域中的每一个不同的关系。在 decoder 部分,采用基于张量分解的模型计算打分:
![]()
基于图神经网络的知识图谱表示学习模型还包括 KBAT 等。
知识图谱表示学习相关综述论文比较多,此处不再赘述,下图对不同类别的典型模型进行了总结。
2.1.2 知识图谱表示学习的应用
本节我们将以问答和推荐任务为代表,介绍如下 3 篇知识图谱表示学习应用的经典工作,其中问答任务:KEQA [6] 和 EmbedKGQA [7],推荐任务:KGAT [8]。
2.1.2.1 KEQA
百度针对只包含一个头实体和一个谓语的简单问句提出基于知识图谱表示学习的 KEQA 框架 [6]。框架主要包括以下三个步骤:
(1)先训练一个谓语学习模型,给定一个问句作为输入,模型返回一个分布在知识图谱嵌入空间的向量作为预测的谓语表示。类似的,KEQA 还训练了一个可以识别头实体的模型来预测头实体的向量表示。
(2)由于知识图谱中的实体数量通常很大,KEQA 采用召回模块来减少候选头实体数量。
(3)通过知识图谱表示学习算法的打分函数可以计算出预测的尾实体表示。
本文解决的是简单问句 KBQA,它可以直接通过图谱中单个三元组进行回答。在问答阶段,将 query 通过以下模型获得头实体、谓词的向量表示,与知识图谱中三元组的嵌入表示进行匹配,筛选出分值最大的候选三元组,将尾实体作为答案输出。

2.1.2.2 EmbedKGQA
KEQA 工作只是针对简单问句的 KBQA 任务,不能解决多跳的 KBQA 任务。发表在 ACL2020 上的 EmbedKGQA 方法 [7],利用知识图谱表示学习进一步解决了多跳的 KBQA 任务。文章首先使用知识图谱表示学习模型 ComplEx 预训练知识图谱中实体和关系的嵌入表示。
然后,使用预训练语言模型学习问句的向量表示,同时从知识图谱中取得候选答案实体,最后利用前面预训练得到 topic entity 的嵌入表示,答案实体的嵌入表示,以及 query 的向量表示,根据知识表示学习模型 ComplEx 的三元组打分函数对所有候选答案实体进行排序,并取排名最高的候选答案实体为问句的答案。EmbedKGQA 在实现多跳 KBQA 任务的同时,还解决了由于图谱不完备给 KBQA 带来的挑战。

2.1.2.3 KGAT
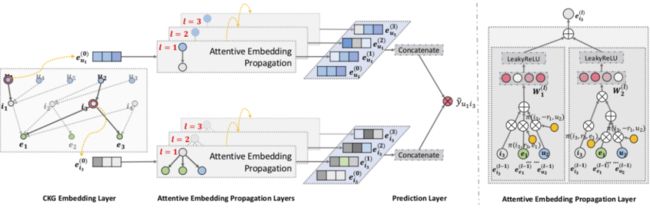
接下来介绍一篇经典的结合知识图谱表示的推荐模型 KGAT [8]。KGAT 将 user-item 和知识图谱融合在一起形成一种新的网络结构,并从该网络结构中抽取多跳路径表达网络中的节点之间的关系。整个 KGAT 模型由三部分组成:
(1)知识表示层:利用知识图谱表示学习基于 TransR 模型 [9] 将网络中的节点表示成知识嵌入。
(2)知识传播层:利用基于知识表示的图注意力机制学习每个邻域中节点的传播权重,并更新中心节点的向量表示。
(3)预测层:通过求 user-item 两向量表示的内积,可以计算出 user-item 之间的得分,最终选择 Top-N 结果输出。
2.2 预训练语言模型知识融入及应用
本节首先介绍预训练语言模型中融入知识的三种主流范式:利用知识设计 mask 机制、优化自然语言和知识的交互、设计更多知识相关的 Pre-training task,之后对融入知识的预训练语言模型的垂直行业应用案例进行介绍。
2.2.1 预训练语言模型知识融入
2.2.1.1 利用知识设计mask机制
本类方法是指将知识图谱中主要元素(如实体)引入 mask 机制,主要介绍百度的两篇相关工作。
百度提出的 ERNIE1.0 [10] 将 mask 的对象从词拓展到短语和知识图谱中的实体,提出了一种多阶段的融合知识的 mask 策略,将短语和实体级的知识融合到语言表达中。这个新的训练任务可以利用文本信息和知识图谱来实现对实体 token 的预测,从而成为一个富有知识的语言表示模型。
在数据上:利用百科类、资讯类、论坛对话类等语料构造具有上下文关系的句子对作为训练数据。在训练任务上:基于对话数据设计了 Dialogue Language Model(DLM)任务,该任务通过学习对话中的隐式关系,增强了模型的语义表示能力。

进一步,百度在 ERNIE 2.0 [11] 继续采用包含实体、词、短语级别多维度的 mask 机制外,还增加了非图谱知识相关的预训练任务:大小写预测、句子间顺序和句子间逻辑关系等。为了更好融合不同预训练任务,模型在各种预训练任务之间采用了 Sequential multi-task learning 的训练框架,该框架可在引入新的学习任务时,不遗忘之前学到过的信息。
2.2.1.2 优化自然语言和知识交互
本类方法中自然语言和知识的链接和交互方式比较多样:如将文本 token 表示和对应实体的知识嵌入表示通过 attention 等方式链接在一起 [12,13,14];通过将知识和文本融合成一个树或者图的整体形式,并设计针对树或者图进行编码 [15,16]。如下介绍几篇经典工作。
清华提出的 ERNIE 模型 [12] 首先识别文本中的实体,然后通过实体链接将其链接到知识图谱中相应的实体。通过知识图谱嵌入算法 TransE 学习知识图谱中实体嵌入表示,然后将实体嵌入表示作为 ERNIE 的输入,以此将知识模块中的实体的表示,引入到预训练语言模型下层的语义表示中。为了更好地融合文本信息和知识信息,文章也设计使用了 2.1.1 中介绍的实体级别的 mask 机制。
原生 BERT 中的 Transformer 是用来学习上下文之间的词法句法表示,由于本文模型结合了知识表示信息,该方法在 Transformer(T-Encoder)之后增加了一个聚合模块(K-Encoder)来将文本 token 表示和实体表示映射到同一个向量空间。如图,虚线框中的 w 和 e 分别表示经过实体链接处理后链接到一起的文本 token 和实体。

预训语言练模型大多是通过设计如 MLM 和 NSP 等预训练任务利用大量无监督语料进行预训练,学习到文本中语义知识。但上述方法存在明显的缺点,即在每次需要添加新的知识类型时,需要重新预训练整个模型,可能会导致之前知识的遗忘。K-Adapter [13] 可以把预训练模型参数固定,然后依据不同类型的知识设计不同的学习器 Adapter 分别独立学习,从而解决“知识遗忘”的问题。
通过分析发现,K-Adapter 有几个特点:1. 它是一个知识可插拔、非侵入式的预训练语言模型;2. 它可以关注不同类型的知识,包括知识图谱知识、表格知识和句法知识等;3. 它还能持续学习。下一步可以沿着这个方向深入的探索。

KnowBERT [14] 首先识别输入文本中的实体跨度(Entity spans),并使用实体链接器(Entity Linker)从知识图谱中获取对应的候选实体,并进一步获取实体的嵌入表示(不同数据源的实体嵌入表示计算方式不同,下文进一步介绍),以形成知识增强的实体跨度表示。
然后,设计 word-to-entity 注意力机制对文本中的每个实体跨度对应的所有候选实体的嵌入表示进行注意力加权,并将加权后的实体表示通过拼接的方式融合到实体跨度的表示当中,具体如下图所视。
不同数据源的实体嵌入表示计算方式不同,对 CrossWikis 和 YAGO 知识库,取得实体 embedding 方式是使用 doc2vec 方法直接从 Wikipedia 的文本描述中学习 Wikipedia 页面标题的向量表示。对于 WordNet 中的同义词和词根,采用知识图谱 Embeding 模型 TuckER,学习到同义词和词根的向量表示。
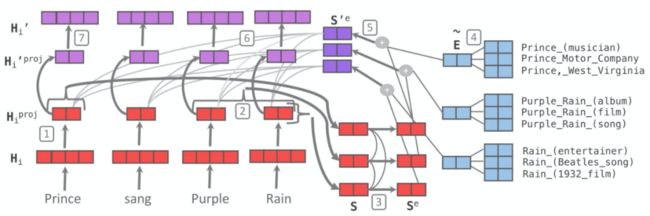
K-BERT [15] 提出了一种基于知识图谱的语言表示模型,模型首先通过实体识别和实体链接获取知识图谱中对应的实体,然后获取该实体一跳内相关三元组,并将三元组作为领域知识注入到句子中,形成一个富有知识的句子树(Sentence tree)。
然而,传统的 BERT,只能处理序列结构的句子输入,而图结构的句子树是无法直接输入到 BERT 中的。如果强行把句子树平铺成序列输入模型,必然造成知识图谱中结构信息的丢失。此外,注入过多的三元组知识同时会引入一些噪声,造成句子偏离正确的含义的问题,具体见下图。
为解决如上两个问题,K-BERT提出了软位置(Soft-position)和可见矩阵(Visible Matrix)两个策略。除了软位置和可见矩阵,K-BERT 中的其余结构均与 Google BERT保持一致,保证了 K-BERT 能够兼容 BERT 类的模型参数来进行 fine-tune,包括直接加载 Google BERT、Baidu ERNIE、Facebook RoBERTa 等公开的已预训练好的预训练模型。

当前融入知识的预训练语言模型,大多使用知识图谱嵌入算法如 TransE 预先训练好实体的嵌入表示,然后将其融入到模型中去,之后实体的嵌入表示不再考虑其所在的上下文信息而随模型一起更新。
CoLAKE [16] 在加入实体嵌入表示的同时也加入它的上下文信息,允许模型在不同语境下关注实体的不同邻居,同时学习文本和知识的上下文表示。为此,CoLAKE 将文本和知识的上下文组成了一张图作为训练样本,称为 word-knowledge graph,然后在图上做 MLM 同时学习文本和知识的表示。
具体地,CoLAKE 首先将输入文本中的所以单词节点形成全连接 word graph,接着把文本中表示实体的单词节点替换为对应的实体节点(这类实体节点被称为anchor node),然后获取该实体在知识图谱中子图(knowledge subgraph)并将子图与 word graph 进行拼接组成 word-knowledge graph,具体构建过程如下图。
最后,将 word-knowledge graph 输入到基于 Transformer 的 MLM 进行预训练学习,其中 Transformer 的 embedding 层和 encoder 层进行了简单调整来适配 word-knowledge graph。

2.2.1.3 设计更多知识相关的Pre-training task
本类方法是指设计一些与知识相关的 Pre-training task,如知识图谱表示学习任务或者针对知识设计的特定任务如实体替换等,如下介绍几篇经典工作。
使用训练好的知识图谱嵌入表示作为预训练语言模型的输入存在如下问题:1. 知识图谱的表示空间难以和语言表示空间对齐,需要特殊的设计;2. 需要使用实体链接组件,其会带来额外的开销以及错误累积。KEPLER 模型 [17] 将知识图谱表示学习也作为一个 Pre-training task,将其和传统的文本表示学习联合成多任务学习。模型设计思路简单,且模型在 Entity Typing 和 Relation Classification 两个任务上取得较好效果。

Facebook 提出的 WSKLM [18] 同样是将知识引入预训练模型,但与之前的方法不同的是,论文设计了如下新的 Pre-training task:通过用相同类型的其他实体替换原始文本中的实体,然后训练模型区分正确的实体和随机选择的其他实体。相比先前的以前利用外部知识库获取实体知识的方法,该方法能够直接从非结构化文本中获取真实世界的知识。此方法设计的 Pre-training task 简单有效,数据容易获取,在下游任务效果提升明显。

2.2.2 预训练语言模型知识融入的应用
在医疗领域的 AI 研究中,药物推荐是重要的医疗应用。大多数现有 AI 模型仅利用少数多次访问的患者的纵向电子病例,在纯文本层面进行预测分析,而忽视了文本中所涉及的医疗背景知识,其中包含各类药物之间的 Hierarchical 关系与各类疾病和病症之间的关系等。
在此类知识融入的研究上,IBM 提出的 G-BERT [19] 通过将 ICD-9(国际疾病图谱)、ATC(国际药品图谱)融入预训练语言模型中,在大量单次访问的患者电子病例上设计医疗相关的任务进行语言模型的训练,再在多次访问的患者的电子病例上进行 finetune,最终在英文医疗数据集 MIMIC-III 的药物推荐上取得了当前最好的效果。

华为提出的 BERT-MK [20] 模型通过将 UMLS(统一医学语言图谱)融入预训练语言模型中,在医学领域多个数据集上实体类别分类任务和关系分类任务均取得当前最好效果。其中在融入知识的过程中,论文设计 GCKE 模块学习子图中实体及其邻域信息。特别的,论文将子图中实体和边都看成节点,形成一个有向图,并将其作为 GCKE 的输入。

2.3 前沿工作总结
通过对前沿工作的分析和总结,我们发现基于知识图谱表示学习应用知识的方法成本最低,但对下游任务效果提升有限,在融入知识的预训练语言模型方法中,设计和下游相关的 Pre-training task,效果提升较明显,值得进一步探索。当前大部分融入知识的预训练语言模型只是在实体类型识别、小样本关系分类任务上进行比较。
实验结果表明,图谱成分识别相关任务和低资源场景下的任务,融入知识方法能有效提升效果。但大部分工作都没有在 GLUE 数据集上比较,原因是 GLUE 属于通用数据集,而用于训练普通语言模型的海量无标数据已经包含充足信息,融入通用知识提供的信息增益很少。

云小蜜知识应用的探索与实践
3.1 知识图谱表示学习的应用:动态自适应能力
本节通过介绍云小蜜 KBQA 平台中的动态自适应能力,具体阐述知识图谱表示学习如何在真实的工业界产品中落地。
3.1.1 动态自适应能力必要性
在同一场景下,随着 KBQA 业务不断运营,会不断出现新的属性,即unseen property,这给模型识别带来很大的挑战。以税务场景为例,运营第 1 个月新增 15 个属性,平均每个属性 7.6 条样本,属性识别准确率为 70%。

训练传统的 KBQA 有监督模型一般需要标注大量的训练语料,这种方法在中长尾部分不适用,原因有 3 点:1. 长尾属性语料本身就很稀疏,达不到有监督模型的样本量要求;2. 即使攒够了训练语料,重新训练模型链路很长,耗时耗力;3. 重训模型后,整体效果不一定正向,还需要反复调试,非常繁琐。

基于以上分析,我们迫切需要一种动态自适应能力以解决新增属性的问题。为此,我们从产品层面和算法层面对问题进行拆解。在产品层面,我们允许用户为图谱中的属性配置相似问句,通过引导用户配置相似问句降低属性识别的难度。算法模块具体工作见下一节。
3.1.2 融入知识的动态自适应算法
对于动态新增的 unseen property,用户在产品界面为其配置几条相似问后,系统能获取少量标注语料,这时我们可以将这个任务抽象为小样本属性识别任务。为了更好的利用图谱中的信息,我们引入知识图谱补全任务来提升 unseen property 识别效果。
模型采用多任务学习的方法,将 unseen property 识别任务和知识补全任务迭代训练。考虑到实际业务场景中知识图谱主要是由<实体,属性,属性值>组成,并且属性值一般为长文本而非实体。借鉴 [7] 工作,我们将传统的知识补全任务优化目标从 Head_Entity + Relation = Tail_Entity 改为 Head_Entity + Property = Query。
实验结果表明,通过知识补全任务融入知识的动态自适应算法相对于基于 Bert 的属性识别算法在税务和保险两个数据集上均有比较明显的提升。通过实验分析发现,模型能够有效利用知识补全任务的监督信号,聚合出同一个 property 下的 query 集合中语义相近但表示形式不一样的多种表述 span,丰富了 property 的语义表征,提升了模型对新属性的泛化能力。

3.1.3 小结
知识图谱是动态的,新增属性在业务运营过程中是常态,为了降低模型训练成本同时保证准确率,我们提出了一套图谱动态自适应的算法方案,核心思路通过引入知识补全任务辅助提升 unseen property 识别效果。当前动态自适应模型不仅适用于单属性的简单问句,对包含约束、多跳的复杂问句也有一定的处理能力。
动态自适应模型的核心任务是知识图谱表示学习,最初我们采用 TransE 模型,而动态自适应面临的是小样本场景,因此我们对基于知识图谱表示学习任务进行了进一步探索,见 3.2。
3.2 知识图谱表示学习的进一步探索
考虑到实际的知识图谱存在长尾分布的关系或由于知识图谱的动态更新导致知识图谱包含很多小样本(few-shot)的关系,我们研究了小样本知识图谱表示学习。目前,该任务主要面临以下两个挑战:
知识图谱邻域稀疏性:对于一些知识图谱,例如 Wikidata,每个实体的邻域中只有非常少量的关联实体和关系,在稀疏邻域的情况下采用邻域信息来学习小样本关系的表示很可能会引入噪声,影响对小样本关系的表示。
知识图谱中的很多关系都具有一对多、多对一和多对多的复杂关系特性,而现有的小样本知识图谱表示学习的研究都难以直接解决这一复杂关系的建模和推理的问题。
针对上述挑战,我们设计了一种新的 Global-Local 两阶段小样本关系学习模型来实现小样本知识图谱表示学习,我们的方法主要包含两个创新点:
设计了一种新的门控加注意力的邻居聚合器,用小样本关系的邻域信息来学习当前的关系表示。当邻域信息非常稀疏时,门控机制可以滤除噪声邻域信息,用实体 Embedding 来表示当前小样本关系,保证在不同情况下都能学习到良好的关系表示。
在 TransH 的基础上结合 MAML 的元学习方法,在小样本的情况下学习每个关系超平面的参数,并用于建模和推理复杂关系。
模型的整体框架如下:

通过实验,我们的模型在 NELL-One 和 Wiki-One 两个数据集上都取得 SOTA 结果,相比于 Strong Baseline MetaR,在 NELL-One 5-shot FKGC 任务上 Hits@10 提升 8.0%。
3.3 融入行业知识的预训练语言模型
在云小蜜实际业务中,新场景下如何快速上线问答模型非常重要,为此,我们构建和训练了融入行业知识的预训练语言模型,为问答模型提供了强大的算法底座,从而降低冷启动成本。传统语言模型基本都是基于通用语料进行训练,它们在专业领域,例如:法律、医疗、保险、教育等行业,由于缺乏领域知识,表现并不理想。我们对此进行了改进,具体方法如下:
实体链接:将用户输入问句中的实体 mention 链接到我们沉淀的行业知识图谱中的实体;
知识和文本融合:将文本的向量表示与其实体的向量表示通过特定网络层和函数进行融合;
Pre-training task:借鉴 KEPLER [17] 的思想,引入知识表示学习作为新的 Pre-training task 进一步提升模型效果。
通过保险和政务场景的实验,融入行业知识的模型在低资源情形下,属性识别准确率相对通用 BERT 模型 Finetune 提升 6%~8%。

总结和展望
本文对知识图谱表示学习和融入知识的预训语言练模型最新进展进行了介绍和分析,同时介绍了我们在知识应用上的探索与实践。我们有以下 3 点发现:
知识图谱表示学习由于知识嵌入表示和文本表示语义空间不同,在具体任务中效果提升不够明显。
融入知识的预训练语言模型在图谱成分识别和低资源场景下的任务上,效果提升明显。
当前针对下游特定任务设计 Pre-training task 还处于探索期,是一个值得持续深耕的方向。
随着知识图谱表示学习和融入知识的预训练语言模型不断发展和完善,应用知识来进一步提升效果的任务也越来越多,结合我们的调研工作和实际业务实践,我们认为知识表示与融入技术未来有以下 3 个发展趋势:
知识来源:充分利用常识知识和概念知识
当前融入知识的预训练语言模型研究工作主要集中使用世界知识如 Freebase、DbPedia,如何进一步融入常识和概念知识将是一个重要研究方向。
知识选择:知识降噪需要更加有效的方法
依据输入文本从规模庞大的知识图谱中选取相关知识是知识融入必不可少的重要模块。而知识获取的过程,首先是基于实体链接从图谱中选出最相关的实体,然后再从相关实体中选出相关三元组,如上两步都会引入不相关的知识,因此需要有效的办法来降噪,保证知识的质量。
Pre-training task:设计融入知识的下游任务相关 Pre-training task
当前融入知识预训练语言模型的Pre-training task更多是通用任务,如实体级别的 MLM 和知识图谱表示学习任务,但针对下游任务设计 Pre-training task的工作研究较少,这方面主要工作是 Facebook 的 WSKLM [18],它已经证明方法的有效性。因此为更多的下游任务如问答、推荐等设计相关的 Pre-training task 将是一个非常重要的方向。
最后,希望本篇工作可以对工业界和学术界读者的工作带来一定的启发和帮助,同时也感谢各位读者的耐心研读,本文若有纰漏或不妥之处,请不吝赐教。
参考文献
[1] Wang, Q., Mao, Z., Wang, et al. (2017). Knowledge graph embedding: A survey of approaches and applications. IEEE Transactions on Knowledge and Data Engineering, 29(12), 2724-2743.
[2] Antoine B, Nicolas U, Alberto G D, et al. (2013). Translating Embeddings for Modeling Multi-relational Data. NIPS, 2787-2795.
[3] Maximilian N, Volker T, Kriegel H P, et al. (2011). A Three-Way Model for Collective Learning on Multi-Relational Data. ICML, 809-816.
[4] Schero R, Chen D Q, Manning C D, et al.(2013). Reasoning With Neural Tensor Networks for Knowledge Base Completion. NIPS, 926-934.
[5] Schlichtkrull M S, Thomas N. K, Bloem P, et al.(2018). Modeling Relational Data with Graph Convolutional Networks. ESWC, 593-607.
[6] Huang, X., Zhang, J., Li, D., & Li, P. (2019). Knowledge graph embedding based question answering. In Proceedings of the Twelfth ACM International Conference on Web Search and Data Mining (pp. 105-113).
[7] Saxena, A., Tripathi, A., & Talukdar, P. (2020). Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (pp. 4498-4507).
[8] Xiang Wang, Xiangnan He, Yixin Cao, Meng Liu and Tat-Seng Chua (2019). KGAT: Knowledge Graph Attention Network for Recommendation. KDD, 950–958.
[9] Yankai Lin, Zhiyuan Liu, Maosong Sun, Yang Liu, Xuan Zhu (2015). Learning Entity and Relation Embeddings for Knowledge Graph Completion. AAAI, 2181-2187.
[10]Sun Y, Wang S, Li Y, et al. Ernie: Enhanced representation through knowledge integration[J]. arXiv preprint arXiv:1904.09223, 2019.
[11] Sun, Y., Wang, S., Li, Y., et al. (2020). ERNIE 2.0: A Continual Pre-Training Framework for Language Understanding. Proceedings of the AAAI Conference on Artificial Intelligence, 34(05), 8968-8975.
[12] Zhang Z, Han X, Liu Z, et al. ERNIE: Enhanced language representation with informative entities[J]. arXiv preprint arXiv:1905.07129, 2019.
[13] Wang R, Tang D, Duan N, et al. K-adapter: Infusing knowledge into pre-trained models with adapters[J]. arXiv preprint arXiv:2002.01808, 2020.
[14] Peters M E, Neumann M, Logan IV R L, et al. Knowledge enhanced contextual word representations[J]. arXiv preprint arXiv:1909.04164, 2019.
[15] Liu, W., Zhou, P., Zhao, Z., et al. (2020). K-BERT: Enabling Language Representation with Knowledge Graph. Proceedings of the AAAI Conference on Artificial Intelligence, 34(03), 2901-2908.
[16] Sun T, Shao Y, Qiu X, et al. CoLAKE: Contextualized Language and Knowledge Embedding[J]. arXiv preprint arXiv:2010.00309, 2020.
[17] Wang X, Gao T, Zhu Z, et al. KEPLER: A unified model for knowledge embedding and pre-trained language representation[J]. arXiv preprint arXiv:1911.06136, 2019.
[18] Xiong W, Du J, Wang W Y, et al. Pretrained Encyclopedia: Weakly Supervised Knowledge-Pretrained Language Model[J]. arXiv preprint arXiv:1912.09637, 2019.
[19] Hong Sh D.,Zhou Y X., Shang J Y, et al. (2019). Pre-training of Graph Augmented Transformers for Medication Recommendation. In The 28th International Joint Conference on Artificial Intelligence
[20] H Bin, Zhou , Xiao J H, et al. (2019). BERT-MK: Integrating Graph Contextualized Knowledge into Pre-trained Language Models.Findings of the Association for Computational Linguistics: EMNLP, 2281–2290
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

