focalloss,diceloss 知识点总结
一 focalloss
1.什么是focalloss,用来干嘛
Focal loss最早是 He et al 在论文 Focal Loss for Dense Object Detection 中实现的。
例如在目标检测中损失函数Binary Cross Entropy loss,这种训练目标要求模型 对自己的预测真的很有信心。而Focal Loss所做的是,它使模型可以更"放松"地预测事物,而无需80-100%确信此对象是“某物”。简而言之,它给模型提供了更多的自由,可以在进行预测时承担一些风险。这在处理高度不平衡的数据集时尤其重要,因为在某些情况下(例如癌症检测),即使预测结果为假阳性也可接受,确实需要模型承担风险并尽量进行预测。
因此,Focal loss在样本不平衡的情况下特别有用。特别是在“对象检测”的情况下,大多数像素通常都是背景,图像中只有很少数的像素具有我们感兴趣的对象。

该损失函数是一个动态缩放的交叉熵损失,当正确类别的置信度增加时,比例因子衰减为零,见图。直观地说,这个比例因子可以在训练过程中自动降低简单示例的权重,并快速将模型集中到难样本上。从图像中可以看出,当模型预测为真实标签的概率为0.6左右时,交叉熵损失仍在0.5左右。因此,为了在训练过程中减少损失,我们的模型将必须以更高的概率来预测到真实标签。换句话说,交叉熵损失要求模型对自己的预测非常有信心。但这也同样会给模型表现带来负面影响。深度学习模型会变得过度自信,泛化能力下降。
从比较Focal loss与CrossEntropy的图表可以看出,当使用γ> 1的Focal Loss可以减少“分类得好的样本”或者说“模型预测正确概率大”的样本的训练损失,而对于“难以分类的示例”,比如预测概率小于0.5的,则不会减小太多损失。因此,在数据类别不平衡的情况下,会让模型的注意力放在稀少的类别上,因为这些类别的样本见过的少,比较难分。
2. 原理
以下引自原论文:
焦点损失旨在解决单级目标检测场景在训练期间前景类和背景类之间存在极端不平衡(例如,1:1000)的问题。我们引入了从二元分类的交叉熵(CE)损失开始的焦点损失
其中y∈{±1}指定了基本真值类,p∈[0,1]是该类的模型估计概率。为了便于标注,我们将pt定义为: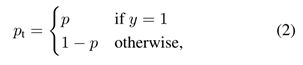
并重新写成CE(p, y) = CE(pt) = −log(pt).
CE损耗可以看作图1中的蓝色(顶部)曲线。这一损失的一个显著特征是,即使是那些容易分类的例子(pt>0.5),也可以很容易地从图中看出并损失较大。在大量简单的例子中进行总结时,这些小的损失值就会覆盖稀有类。
解决类不平衡的一种常见方法是为类1引入权重因子α∈[0,1],为类−1引入1−α。在实践中,α可以通过逆类频率来设置,也可以作为一个超参数通过交叉验证来设置。为了便于注释,我们将α定义为pt的定义。我们将α-平衡CE损耗写为:![]()
这个损耗是CE的一个简单扩展,我们将其作为我们提出的焦点损耗的实验基线。
---------------------------------------------------------------------------------------------------------------------------
focalloss定义:
![]()
对比crossentropy,其中多了两部分
(原文:类间不均衡较大会导致,交叉熵损失在训练的时候收到影响。易分类的样本的分类错误的损失占了整体损失的绝大部分,并主导梯度。尽管α平衡了正面/负面例子的重要性,但它并未区分简单/困难例子。虽然有上方的因子α,但是在大多数情况下往往是不够的,所以主要就取决于γ)
γ控制曲线的形状. γ的值越大, 好分类样本的loss就越小, 我们就可以把模型的注意力投向那些难分类的样本. 一个大的 γ让获得小loss的样本范围扩大了.
二 diceloss
1 dice coefficient定义
dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度:
 范围为【0,1】
范围为【0,1】
相应的diceloss为

预测的分割图的 dice 系数计算,首先将 |X⋂Y| 近似为预测图与 GT 分割图之间的点乘,并将点乘的元素结果相加:
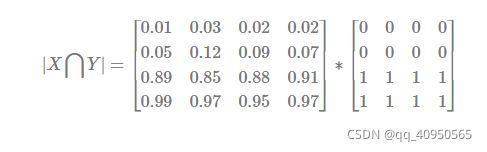

关于 |X| 和 |Y| ,可采用直接简单的元素相加;也有采用取元素平方求和的做法。
2 适用情况
dice loss 比较适用于样本极度不均的情况,一般的情况下,使用 dice loss 会对反向传播造成不利的影响,容易使训练变得不稳定.
直接采用 dice-coefficient 或者 IoU 作为损失函数的原因,是因为分割的真实目标就是最大化 dice-coefficient 和 IoU 度量. 而交叉熵仅是一种代理形式,利用其在 BP 中易于最大化优化的特点.
另外,Dice-coefficient 对于类别不均衡问题,效果可能更优. 然而,类别不均衡往往可以通过简单的对于每一个类别赋予不同的 loss 因子,以使得网络能够针对性的处理某个类别出现比较频繁的情况. 因此,对于 Dice-coefficient 是否真的适用于类别不均衡场景,还有待探讨.