dataWhale集成学习task01
dataWhale集成学习ch2——01
一、概述
机器学习的一个重要的目标就是利用数学模型来理解数据,发现数据中的规律,用作数据的分析和预测。现实生活中常见的学习问题可以分为"监督学习"(supervised learning)和"无监督学习"(unsupervised learning)

根据因变量的是否连续,有监督学习又分为回归和分类:
- List item回归:因变量是数值变量,如:房价,体重等。相应的模型称为“回归模型”
- List item分类:因变量是类别变量,如:是否患癌症,西瓜是好瓜还是坏瓜等。相应的模型称为“分类模型”、
无监督学习不依赖于标记信息,目标是发现数据的内在分布信息。其中一个典型的任务是“聚类”(clustering),即:发现数据点内在的“簇”(cluster)结构。
学习的根本目标在于“泛化”(generalization),即能把从训练样本学习获得的知识推广到未见样本。
二、回归
常见的模型有两种:
线性模型(Linear Model):
![]()
多项式模型(Polynomial Model):
![]()
例子1:(Boston房价数据集)
from sklearn import datasets
boston = datasets.load_boston() # 返回一个类似于字典的类
X = boston.data
y = boston.target
features = boston.feature_names
boston_data = pd.DataFrame(X,columns=features)
boston_data["Price"] = y
boston_data.head(10)

可视化可以看到:
# 可视化特征
sns.scatterplot(x=boston_data['NOX'],y=boston_data['Price'],color="r",alpha=0.6)
plt.title("Price~NOX")
plt.show()

数据给定任务所需要的因变量,因变量为波士顿房价Price是一个数值型变量,所以这是一个回归的例子。
三、分类
分类问题可以分为二分类问题(西瓜的好坏等)和多分类问题(鸢尾花的类别等)。
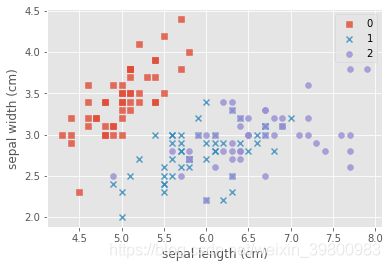
例子2:(iris数据集)
from sklearn import datasets
iris = datasets.load_iris()
X = iris.data
y = iris.target
features = iris.feature_names
iris_data = pd.DataFrame(X,columns=features)
iris_data['target'] = y
iris_data.head()

# 可视化特征
marker = ['s','x','o']
for index,c in enumerate(np.unique(y)):
plt.scatter(x=iris_data.loc[y==c,"sepal length (cm)"],y=iris_data.loc[y==c,"sepal width (cm)"],alpha=0.8,label=c,marker=marker[c])
plt.xlabel("sepal length (cm)")
plt.ylabel("sepal width (cm)")
plt.legend()
plt.show()
四、无监督
聚类任务的目标是将无标记数据分成若干簇来挖掘数据中的内在结构。
这里我们使用sklearn生成符合我们需求的无因变量的数据集:
https://scikit-learn.org/stable/modules/classes.html?highlight=datasets#module-sklearn.datasets
下面是使用sklearn生成数据的例子
(1)
# 生成月牙型非凸集
from sklearn import datasets
x, y = datasets.make_moons(n_samples=2000, shuffle=True,
noise=0.05, random_state=None)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c,0],x[y==c,1],s=7)
plt.show()

(2)
# 生成圆形的数据集
from sklearn import datasets
x, y = datasets.make_circles(n_samples=2500, shuffle=True,
noise=0.05, random_state=None)
for index,c in enumerate(np.unique(y)):
sns.scatterplot(x=x[y==c,0],y=x[y==c,1],s=7)
plt.show()

(3)
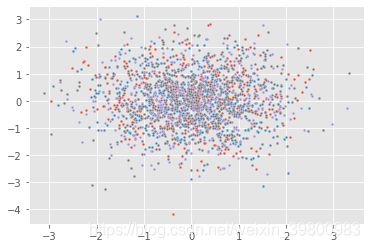
# 生成多分类的数据集
from sklearn import datasets
x, y = datasets.make_classification(n_samples=2000, n_features=30, n_informative=3, n_redundant=3,n_classes=4)
for index, c in enumerate(np.unique(y)):
sns.scatterplot(x=x[y==c, 0], y=x[y==c, 1], s=7)
plt.show()
(4)
# 生成高斯分布的数据集
from sklearn import datasets
x, y = datasets.make_gaussian_quantiles(cov=2.0, n_samples=2000, n_features=4, n_classes=8, shuffle=True, random_state=True)
for index, c in enumerate(np.unique(y)):
sns.scatterplot(x=x[y==c, 0], y=x[y==c, 1], s=7)
plt.show()

(5)
from sklearn import datasets
x, y = datasets.make_swiss_roll(n_samples=2000, noise=0.05, random_state=None)
for index, c in enumerate(np.unique(y)):
sns.scatterplot(x=x[y==c, 0], y=x[y==c, 1], s=7)
plt.show()
(6)
# 生成符合正态分布的聚类数据
from sklearn import datasets
x, y = datasets.make_blobs(n_samples=5000, n_features=4, centers=4)
for index,c in enumerate(np.unique(y)):
plt.scatter(x[y==c, 0], x[y==c, 1],s=7)
plt.show()

五、问题
使用seaborn画图时,发现由这种的警告:
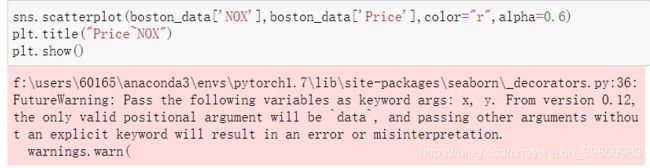
根据提示我们在前两个参数前加上x, y即可解决,具体如下所示:
sns.scatterplot(boston_data['NOX'],boston_data['Price'],color="r",alpha=0.6)
plt.title("Price~NOX")
plt.show()
改为:
sns.scatterplot(x=boston_data['NOX'],y=boston_data['Price'],color="r",alpha=0.6)
plt.title("Price~NOX")
plt.show()
最后感谢dataWhale和dataWhale中可爱的贡献者和助教们以及这么多热爱学习的小伙伴们!因为大家,学习之路从此不再孤独~~~~
参考:
[1].https://github.com/datawhalechina/team-learning-data-mining/tree/master/EnsembleLearning
[2].集成学习基础与算法,周志华