商业发展与职能技术部-体验保障研发组 康睿 姚再毅 李振 刘斌 王北永
说明:以下全部均基于eslaticsearch 8.1 版本
一.索引的定义
官网文档地址:https://www.elastic.co/guide/...
索引的全局认知
| ElasticSearch | Mysql |
|---|---|
| Index | Table |
| Type废弃 | Table废弃 |
| Document | Row |
| Field | Column |
| Mapping | Schema |
| Everything is indexed | Index |
| Query DSL | SQL |
| GET http://... | select * from |
| POST http://... | update table set ... |
| Aggregations | group by\sum\sum |
| cardinality | 去重 distinct |
| reindex | 数据迁移 |
索引的定义
定义: 相同文档结构(Mapping)文档的结合 由唯一索引名称标定 一个集群中有多个索引 不同的索引代表不同的业务类型数据 注意事项: 索引名称不支持大写 索引名称最大支持255个字符长度 字段的名称,支持大写,不过建议全部统一小写
索引的创建
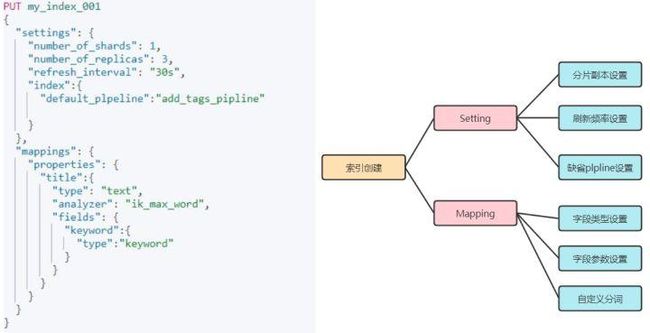
编辑切换为居中
添加图片注释,不超过 140 字(可选)
index-settings 参数解析
官网文档地址:https://www.elastic.co/guide/...
注意: 静态参数索引创建后,不再可以修改,动态参数可以修改 思考: 一、为什么主分片创建后不可修改? A document is routed to a particular shard in an index using the following formula:
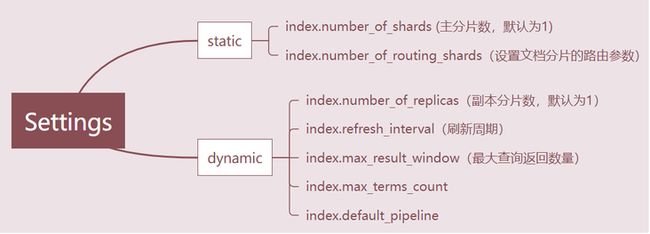
编辑切换为居中
添加图片注释,不超过 140 字(可选)
索引的基本操作
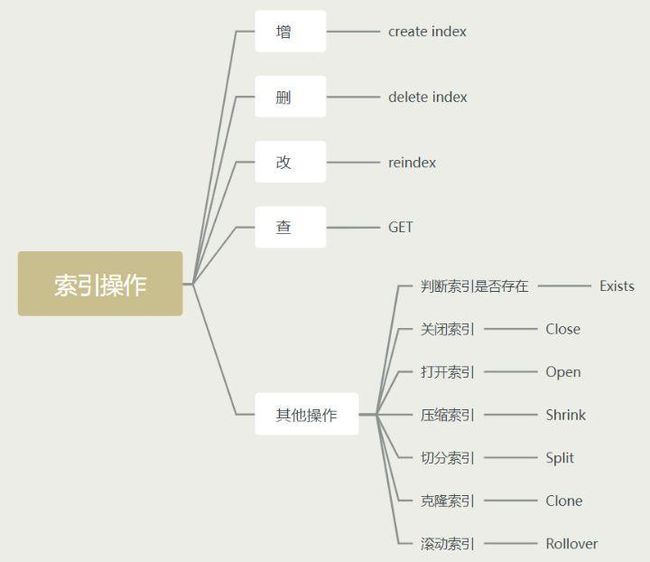
编辑切换为居中
添加图片注释,不超过 140 字(可选)
二.Mapping-Param之dynamic
官网文档地址:https://www.elastic.co/guide/...
核心功能
自动检测字段类型后添加字段 也就是哪怕你没有在es的mapping中定义该字段,es也会动态的帮你检测字段类型
初识dynamic
// 删除test01索引,保证这个索引现在是干净的
DELETE test01
// 不定义mapping,直接一条插入数据试试看,
POST test01/_doc/1
{
"name":"kangrui10"
}
// 然后我们查看test01该索引的mapping结构 看看name这个字段被定义成了什么类型
// 由此可以看出,name一级为text类型,二级定义为keyword,但其实这并不是我们想要的结果,
// 我们业务查询中name字段并不会被分词查询,一般都是全匹配(and name = xxx)
// 以下的这种结果,我们想要实现全匹配 就需要 name.keyword = xxx 反而麻烦
GET test01/_mapping
{
"test01" : {
"mappings" : {
"properties" : {
"name" : {
"type" : "text",
"fields" : {
"keyword" : {
"type" : "keyword",
"ignore_above" : 256
}
}
}
}
}
}
}dynamic的可选值
| 可选值 | 说明 | 解释 |
|---|---|---|
| true | New fields are added to the mapping (default). | 创建mapping时,如果不指定dynamic的值,默认true,即如果你的字段没有收到指定类型,就会es帮你动态匹配字段类型 |
| false | New fields are ignored. These fields will not be indexed or searchable, but will still appear in the _source field of returned hits. These fields will not be added to the mapping, and new fields must be added explicitly. | 若设置为false,如果你的字段没有在es的mapping中创建,那么新的字段,一样可以写入,但是不能被查询,mapping中也不会有这个字段,也就是被写入的字段,不会被创建索引 |
| strict | If new fields are detected, an exception is thrown and the document is rejected. New fields must be explicitly added to the mapping. | 若设置为strict,如果新的字段,没有在mapping中创建字段,添加会直接报错,生产环境推荐,更加严谨。示例如下,如要新增字段,就必须手动的新增字段 |
动态映射的弊端
- 字段匹配相对准确,但不一定是用户期望的
- 比如现在有一个text字段,es只会给你设置为默认的standard分词器,但我们一般需要的是ik中文分词器
- 占用多余的存储空间
- string类型匹配为text和keyword两种类型,意味着会占用更多的存储空间
- mapping爆炸
- 如果不小心写错了查询语句,get用成了put误操作,就会错误创建很多字段
三.Mapping-Param之doc_values
官网文档地址:https://www.elastic.co/guide/...
核心功能
DocValue其实是Lucene在构建倒排索引时,会额外建立一个有序的正排索引(基于document => field value的映射列表) DocValue本质上是一个序列化的 列式存储,这个结构非常适用于聚合(aggregations)、排序(Sorting)、脚本(scripts access to field)等操作。而且,这种存储方式也非常便于压缩,特别是数字类型。这样可以减少磁盘空间并且提高访问速度。 几乎所有字段类型都支持DocValue,除了text和annotated_text字段。
何为正排索引
正排索引其实就是类似于数据库表,通过id和数据进行关联,通过搜索文档id,来获取对应的数据
doc_values可选值
- true:默认值,默认开启
- false:需手动指定,设置为false后,sort、aggregate、access the field from script将会无法使用,但会节省磁盘空间
真题演练
// 创建一个索引,test03,字段满足以下条件
// 1. speaker: keyword
// 2. line_id: keyword and not aggregateable
// 3. speech_number: integer
PUT test03
{
"mappings": {
"properties": {
"speaker": {
"type": "keyword"
},
"line_id":{
"type": "keyword",
"doc_values": false
},
"speech_number":{
"type": "integer"
}
}
}
}四.分词器analyzers
ik中文分词器安装
https://github.com/medcl/elas...
何为倒排索引
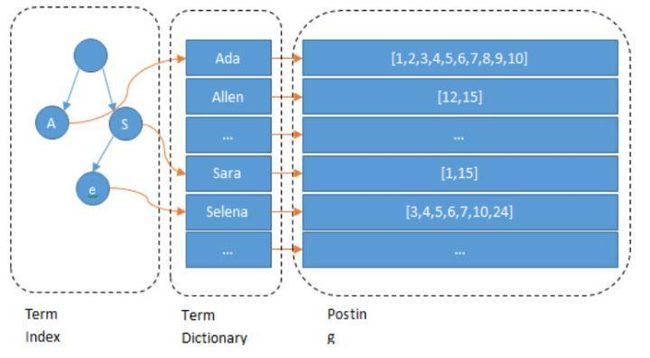
编辑切换为居中
添加图片注释,不超过 140 字(可选)
数据索引化的过程
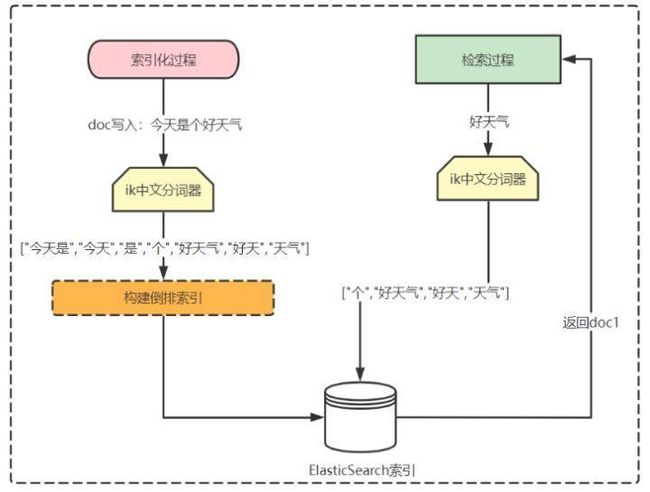
编辑切换为居中
添加图片注释,不超过 140 字(可选)
分词器的分类
官网地址: https://www.elastic.co/guide/...

编辑切换为居中
添加图片注释,不超过 140 字(可选)
五.自定义分词
自定义分词器三段论
1.Character filters 字符过滤
官网文档地址:https://www.elastic.co/guide/... 可配置0个或多个
HTML Strip Character Filter:用途:删除HTML元素,如 ,并解 码HTML实体,如&amp
Mapping Character Filter:用途:替换指定字符
Pattern Replace Character Filter:用途:基于正则表达式替换指定字符
2.Tokenizer 文本切为分词
官网文档地址:https://www.elastic.co/guide/... 只能配置一个 用分词器对文本进行分词
3.Token filters 分词后再过滤
官网文档地址:https://www.elastic.co/guide/... 可配置0个或多个 分词后再加工,比如转小写、删除某些特殊的停用词、增加同义词等
真题演练
有一个文档,内容类似 dag & cat, 要求索引这个文档,并且使用match_parase_query, 查询dag & cat 或者 dag and cat,都能够查到 题目分析: 1.何为match_parase_query:match_phrase 会将检索关键词分词。match_phrase的分词结果必须在被检索字段的分词中都包含,而且顺序必须相同,而且默认必须都是连续的。 2.要实现 & 和 and 查询结果要等价,那么就需要自定义分词器来实现了,定制化的需求 3.如何自定义一个分词器:https://www.elastic.co/guide/...
解法1
# 新建索引
PUT /test01
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"char_filter": [
"my_mappings_char_filter"
],
"tokenizer": "standard",
}
},
"char_filter": {
"my_mappings_char_filter": {
"type": "mapping",
"mappings": [
"& => and"
]
}
}
}
},
"mappings": {
"properties": {
"content":{
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
// 说明
// 三段论之Character filters,使用char_filter进行文本替换
// 三段论之Token filters,使用默认分词器
// 三段论之Token filters,未设定
// 字段content 使用自定义分词器my_analyzer
# 填充测试数据
PUT test01/_bulk
{"index":{"_id":1}}
{"content":"doc & cat"}
{"index":{"_id":2}}
{"content":"doc and cat"}
# 执行测试,doc & cat || oc and cat 结果输出都为两条
POST test01/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"content": "doc & cat"
}
}
]
}
}
}解法2
# 解题思路,将& 和 and 设定为同义词,使用Token filters
# 创建索引
PUT /test02
{
"settings": {
"analysis": {
"analyzer": {
"my_synonym_analyzer": {
"tokenizer": "whitespace",
"filter": [
"my_synonym"
]
}
},
"filter": {
"my_synonym": {
"type": "synonym",
"lenient": true,
"synonyms": [
"& => and"
]
}
}
}
},
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "my_synonym_analyzer"
}
}
}
}
// 说明
// 三段论之Character filters,未设定
// 三段论之Token filters,使用whitespace空格分词器,为什么不用默认分词器?因为默认分词器会把&分词后剔除了,就无法在去做分词后的过滤操作了
// 三段论之Token filters,使用synony分词后过滤器,对&和and做同义词
// 字段content 使用自定义分词器my_synonym_analyzer
# 填充测试数据
PUT test02/_bulk
{"index":{"_id":1}}
{"content":"doc & cat"}
{"index":{"_id":2}}
{"content":"doc and cat"}
# 执行测试
POST test02/_search
{
"query": {
"bool": {
"must": [
{
"match_phrase": {
"content": "doc & cat"
}
}
]
}
}
}六.multi-fields
官网文档地址:https://www.elastic.co/guide/...
// 单字段多类型,比如一个字段我想设置两种分词器
PUT my-index-000001
{
"mappings": {
"properties": {
"city": {
"type": "text",
"analyzer":"standard",
"fields": {
"fieldText": {
"type": "text",
"analyzer":"ik_smart",
}
}
}
}
}
}七.runtime_field 运行时字段
官网文档地址:https://www.elastic.co/guide/...
产生背景
假如业务中需要根据某两个数字类型字段的差值来排序,也就是我需要一个不存在的字段, 那么此时应该怎么办? 当然你可以刷数,新增一个差值结果字段来实现,假如此时不允许你刷数新增字段怎么办?
解决方案
编辑切换为居中
添加图片注释,不超过 140 字(可选)
应用场景
- 在不重新建立索引的情况下,向现有文档新增字段
- 在不了解数据结构的情况下处理数据
- 在查询时覆盖从原索引字段返回的值
- 为特定用途定义字段而不修改底层架构
功能特性
- Lucene完全无感知,因没有被索引化,没有doc_values
- 不支持评分,因为没有倒排索引
- 打破传统先定义后使用的方式
- 能阻止mapping爆炸
- 增加了API的灵活性
- 注意,会使得搜索变慢
实际使用
- 运行时检索指定,即检索环节可使用(也就是哪怕mapping中没有这个字段,我也可以查询)
- 动态或静态mapping指定,即mapping环节可使用(也就是在mapping中添加一个运行时的字段)
真题演练1
# 假定有以下索引和数据
PUT test03
{
"mappings": {
"properties": {
"emotion": {
"type": "integer"
}
}
}
}
POST test03/_bulk
{"index":{"_id":1}}
{"emotion":2}
{"index":{"_id":2}}
{"emotion":5}
{"index":{"_id":3}}
{"emotion":10}
{"index":{"_id":4}}
{"emotion":3}
# 要求:emotion > 5, 返回emotion_falg = '1',
# 要求:emotion < 5, 返回emotion_falg = '-1',
# 要求:emotion = 5, 返回emotion_falg = '0', 解法1
检索时指定运行时字段: https://www.elastic.co/guide/... 该字段本质上是不存在的,所以需要检索时要加上 fields *
GET test03/_search
{
"fields": [
"*"
],
"runtime_mappings": {
"emotion_falg": {
"type": "keyword",
"script": {
"source": """
if(doc['emotion'].value>5)emit('1');
if(doc['emotion'].value<5)emit('-1');
if(doc['emotion'].value==5)emit('0');
"""
}
}
}
}解法2
创建索引时指定运行时字段:https://www.elastic.co/guide/... 该方式支持通过运行时字段做检索
# 创建索引并指定运行时字段
PUT test03_01
{
"mappings": {
"runtime": {
"emotion_falg": {
"type": "keyword",
"script": {
"source": """
if(doc['emotion'].value>5)emit('1');
if(doc['emotion'].value<5)emit('-1');
if(doc['emotion'].value==5)emit('0');
"""
}
}
},
"properties": {
"emotion": {
"type": "integer"
}
}
}
}
# 导入测试数据
POST test03_01/_bulk
{"index":{"_id":1}}
{"emotion":2}
{"index":{"_id":2}}
{"emotion":5}
{"index":{"_id":3}}
{"emotion":10}
{"index":{"_id":4}}
{"emotion":3}
# 查询测试
GET test03_01/_search
{
"fields": [
"*"
]
}真题演练2
# 有以下索引和数据
PUT test04
{
"mappings": {
"properties": {
"A":{
"type": "long"
},
"B":{
"type": "long"
}
}
}
}
PUT task04/_bulk
{"index":{"_id":1}}
{"A":100,"B":2}
{"index":{"_id":2}}
{"A":120,"B":2}
{"index":{"_id":3}}
{"A":120,"B":25}
{"index":{"_id":4}}
{"A":21,"B":25}
# 需求:在task04索引里,创建一个runtime字段,其值是A-B,名称为A_B; 创建一个range聚合,分为三级:小于0,0-100,100以上;返回文档数
// 使用知识点:
// 1.检索时指定运行时字段: https://www.elastic.co/guide/en/elasticsearch/reference/8.1/runtime-search-request.html
// 2.范围聚合 https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-bucket-range-aggregation.html解法
# 结果测试
GET task04/_search
{
"fields": [
"*"
],
"size": 0,
"runtime_mappings": {
"A_B": {
"type": "long",
"script": {
"source": """
emit(doc['A'].value - doc['B'].value);
"""
}
}
},
"aggs": {
"price_ranges_A_B": {
"range": {
"field": "A_B",
"ranges": [
{ "to": 0 },
{ "from": 0, "to": 100 },
{ "from": 100 }
]
}
}
}
}八.Search-highlighted
highlighted语法初识
官网文档地址:https://www.elastic.co/guide/...

编辑切换为居中
添加图片注释,不超过 140 字(可选)
九.Search-Order
Order语法初识
官网文档地址: https://www.elastic.co/guide/...
// 注意:text类型默认是不能排或聚合的,如果非要排序或聚合,需要开启fielddata
GET /kibana_sample_data_ecommerce/_search
{
"query": {
"match": {
"customer_last_name": "wood"
}
},
"highlight": {
"number_of_fragments": 3,
"fragment_size": 150,
"fields": {
"customer_last_name": {
"pre_tags": [
""
],
"post_tags": [
""
]
}
}
},
"sort": [
{
"currency": {
"order": "desc"
},
"_score": {
"order": "asc"
}
}
]
}十.Search-Page
page语法初识
官网文档地址:https://www.elastic.co/guide/...
# 注意 from的起始值是 0 不是 1
GET kibana_sample_data_ecommerce/_search
{
"from": 5,
"size": 20,
"query": {
"match": {
"customer_last_name": "wood"
}
}
}真题演练1
# 题目
In the spoken lines of the play, highlight the word Hamlet (int the text_entry field) startint the highlihnt with "#aaa#" and ending it with "#bbb#"
return all of speech_number field lines in reverse order; '20' speech lines per page,starting from line '40'
# highlight 处理 text_entry 字段 ; 关键词 Hamlet 高亮
# page分页:from:40;size:20
# speech_number:倒序
POST test09/_search
{
"from": 40,
"size": 20,
"query": {
"bool": {
"must": [
{
"match": {
"text_entry": "Hamlet"
}
}
]
}
},
"highlight": {
"fields": {
"text_entry": {
"pre_tags": [
"#aaa#"
],
"post_tags": [
"#bbb#"
]
}
}
},
"sort": [
{
"speech_number.keyword": {
"order": "desc"
}
}
]
}十一.Search-AsyncSearch
官网文档地址:https://www.elastic.co/guide/...
发行版本
7.7.0
适用场景
允许用户在异步搜索结果时可以检索,从而消除了仅在查询完成后才等待最终响应的情况
常用命令
- 执行异步检索
- POST /sales*/_async_search?size=0
- 查看异步检索
- GET /_async_search/id值
- 查看异步检索状态
- GET /_async_search/id值
- 删除、终止异步检索
- DELETE /_async_search/id值
异步查询结果说明
| 返回值 | 含义 |
|---|---|
| id | 异步检索返回的唯一标识符 |
| is_partial | 当查询不再运行时,指示再所有分片上搜索是成功还是失败。在执行查询时,is_partial=true |
| is_running | 搜索是否仍然再执行 |
| total | 将在多少分片上执行搜索 |
| successful | 有多少分片已经成功完成搜索 |
十二.Aliases索引别名
官网文档地址:https://www.elastic.co/guide/...
Aliases的作用
在ES中,索引别名(index aliases)就像一个快捷方式或软连接,可以指向一个或多个索引。别名带给我们极大的灵活性,我们可以使用索引别名实现以下功能:
- 在一个运行中的ES集群中无缝的切换一个索引到另一个索引上(无需停机)
- 分组多个索引,比如按月创建的索引,我们可以通过别名构造出一个最近3个月的索引
- 查询一个索引里面的部分数据构成一个类似数据库的视图(views
假设没有别名,如何处理多索引的检索
方式1:POST index_01,index_02.index_03/_search 方式2:POST index*/search
创建别名的三种方式
- 创建索引的同时指定别名
# 指定test05的别名为 test05_aliases
PUT test05
{
"mappings": {
"properties": {
"name":{
"type": "keyword"
}
}
},
"aliases": {
"test05_aliases": {}
}
}- 使用索引模板的方式指定别名
PUT _index_template/template_1
{
"index_patterns": ["te*", "bar*"],
"template": {
"settings": {
"number_of_shards": 1
},
"mappings": {
"_source": {
"enabled": true
},
"properties": {
"host_name": {
"type": "keyword"
},
"created_at": {
"type": "date",
"format": "EEE MMM dd HH:mm:ss Z yyyy"
}
}
},
"aliases": {
"mydata": { }
}
},
"priority": 500,
"composed_of": ["component_template1", "runtime_component_template"],
"version": 3,
"_meta": {
"description": "my custom"
}
}- 对已有的索引创建别名
POST _aliases
{
"actions": [
{
"add": {
"index": "logs-nginx.access-prod",
"alias": "logs"
}
}
]
}删除别名
POST _aliases
{
"actions": [
{
"remove": {
"index": "logs-nginx.access-prod",
"alias": "logs"
}
}
]
}真题演练1
# Define an index alias for 'accounts-row' called 'accounts-male': Apply a filter to only show the male account owners
# 为'accounts-row'定义一个索引别名,称为'accounts-male':应用一个过滤器,只显示男性账户所有者
POST _aliases
{
"actions": [
{
"add": {
"index": "accounts-row",
"alias": "accounts-male",
"filter": {
"bool": {
"filter": [
{
"term": {
"gender.keyword": "male"
}
}
]
}
}
}
}
]
}十三.Search-template
官网文档地址:https://www.elastic.co/guide/...
功能特点
模板接受在运行时指定参数。搜索模板存储在服务器端,可以在不更改客户端代码的情况下进行修改。
初识search-template
# 创建检索模板
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"{{query_key}}": "{{query_value}}"
}
},
"from": "{{from}}",
"size": "{{size}}"
}
}
}
# 使用检索模板查询
GET my-index/_search/template
{
"id": "my-search-template",
"params": {
"query_key": "your filed",
"query_value": "your filed value",
"from": 0,
"size": 10
}
}索引模板的操作
创建索引模板
PUT _scripts/my-search-template
{
"script": {
"lang": "mustache",
"source": {
"query": {
"match": {
"message": "{{query_string}}"
}
},
"from": "{{from}}",
"size": "{{size}}"
},
"params": {
"query_string": "My query string"
}
}
}验证索引模板
POST _render/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world",
"from": 20,
"size": 10
}
}执行检索模板
GET my-index/_search/template
{
"id": "my-search-template",
"params": {
"query_string": "hello world",
"from": 0,
"size": 10
}
}获取全部检索模板
GET _cluster/state/metadata?pretty&filter_path=metadata.stored_scripts删除检索模板
DELETE _scripts/my-search-templateath=metadata.stored_scripts十四.Search-dsl 简单检索
官网文档地址:https://www.elastic.co/guide/...
检索选型
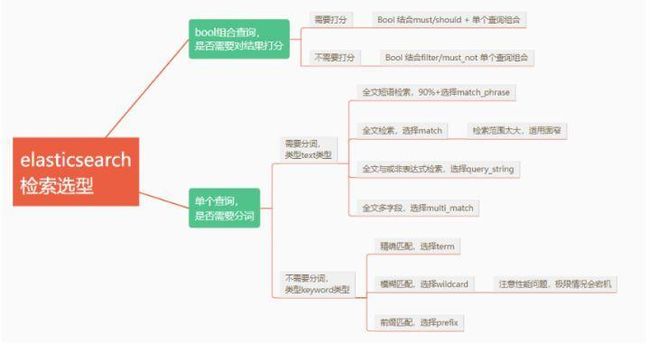
编辑切换为居中
添加图片注释,不超过 140 字(可选)
检索分类
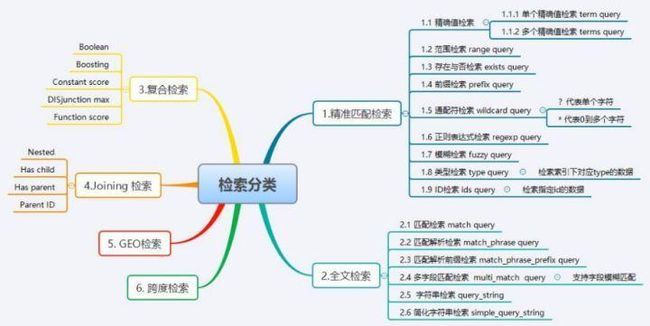
编辑切换为居中
添加图片注释,不超过 140 字(可选)
自定义评分
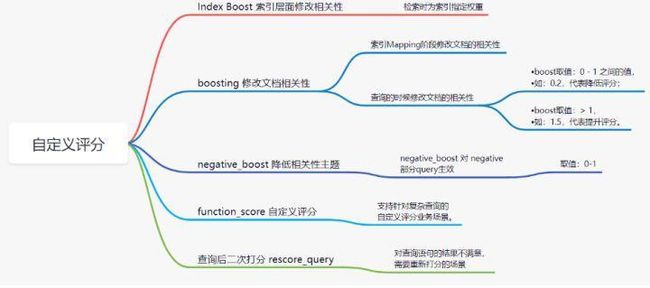
如何自定义评分
编辑切换为居中
添加图片注释,不超过 140 字(可选)
1.index Boost索引层面修改相关性
// 一批数据里,有不同的标签,数据结构一致,不同的标签存储到不同的索引(A、B、C),最后要严格按照标签来分类展示的话,用什么查询比较好?
// 要求:先展示A类,然后B类,然后C类
# 测试数据如下
put /index_a_123/_doc/1
{
"title":"this is index_a..."
}
put /index_b_123/_doc/1
{
"title":"this is index_b..."
}
put /index_c_123/_doc/1
{
"title":"this is index_c..."
}
# 普通不指定的查询方式,该查询方式下,返回的三条结果数据评分是相同的
POST index_*_123/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "this"
}
}
]
}
}
}
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-search.html
indices_boost
# 也就是索引层面提升权重
POST index_*_123/_search
{
"indices_boost": [
{
"index_a_123": 10
},
{
"index_b_123": 5
},
{
"index_c_123": 1
}
],
"query": {
"bool": {
"must": [
{
"match": {
"title": "this"
}
}
]
}
}
}2.boosting 修改文档相关性
某索引index_a有多个字段, 要求实现如下的查询:
1)针对字段title,满足'ssas'或者'sasa’。
2)针对字段tags(数组字段),如果tags字段包含'pingpang',
则提升评分。
要求:写出实现的DSL?
# 测试数据如下
put index_a/_bulk
{"index":{"_id":1}}
{"title":"ssas","tags":"basketball"}
{"index":{"_id":2}}
{"title":"sasa","tags":"pingpang; football"}
# 解法1
POST index_a/_search
{
"query": {
"bool": {
"must": [
{
"bool": {
"should": [
{
"match": {
"title": "ssas"
}
},
{
"match": {
"title": "sasa"
}
}
]
}
}
],
"should": [
{
"match": {
"tags": {
"query": "pingpang",
"boost": 1
}
}
}
]
}
}
}
# 解法2
// https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-dsl-function-score-query.html
POST index_a/_search
{
"query": {
"bool": {
"should": [
{
"function_score": {
"query": {
"match": {
"tags": {
"query": "pingpang"
}
}
},
"boost": 1
}
}
],
"must": [
{
"bool": {
"should": [
{
"match": {
"title": "ssas"
}
},
{
"match": {
"title": "sasa"
}
}
]
}
}
]
}
}
}3.negative_boost降低相关性
对于某些结果不满意,但又不想通过 must_not 排除掉,可以考虑可以考虑boosting query的negative_boost。
即:降低评分
negative_boost
(Required, float) Floating point number between 0 and 1.0 used to decrease the relevance scores of documents matching the negative query.
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-dsl-boosting-query.html
POST index_a/_search
{
"query": {
"boosting": {
"positive": {
"term": {
"tags": "football"
}
},
"negative": {
"term": {
"tags": "pingpang"
}
},
"negative_boost": 0.5
}
}
}4.function_score 自定义评分
如何同时根据 销量和浏览人数进行相关度提升?
问题描述:针对商品,例如有想要有一个提升相关度的计算,同时针对销量和浏览人数?
例如oldScore*(销量+浏览人数)
**************************
商品 销量 浏览人数
A 10 10
B 20 20
C 30 30
**************************
# 示例数据如下
put goods_index/_bulk
{"index":{"_id":1}}
{"name":"A","sales_count":10,"view_count":10}
{"index":{"_id":2}}
{"name":"B","sales_count":20,"view_count":20}
{"index":{"_id":3}}
{"name":"C","sales_count":30,"view_count":30}
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/query-dsl-function-score-query.html
知识点:script_score
POST goods_index/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"script_score": {
"script": {
"source": "_score * (doc['sales_count'].value+doc['view_count'].value)"
}
}
}
}
}十五.Search-del Bool复杂检索
官网文档地址:https://www.elastic.co/guide/...
基本语法

编辑切换为居中
添加图片注释,不超过 140 字(可选)
真题演练
写一个查询,要求某个关键字再文档的四个字段中至少包含两个以上
功能点:bool 查询,should / minimum_should_match
1.检索的bool查询
2.细节点 minimum_should_match
注意:minimum_should_match 当有其他子句的时候,默认值为0,当没有其他子句的时候默认值为1
POST test_index/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"filed1": "kr"
}
},
{
"match": {
"filed2": "kr"
}
},
{
"match": {
"filed3": "kr"
}
},
{
"match": {
"filed4": "kr"
}
}
],
"minimum_should_match": 2
}
}
}十六.Search-Aggregations
官网文档地址:https://www.elastic.co/guide/...
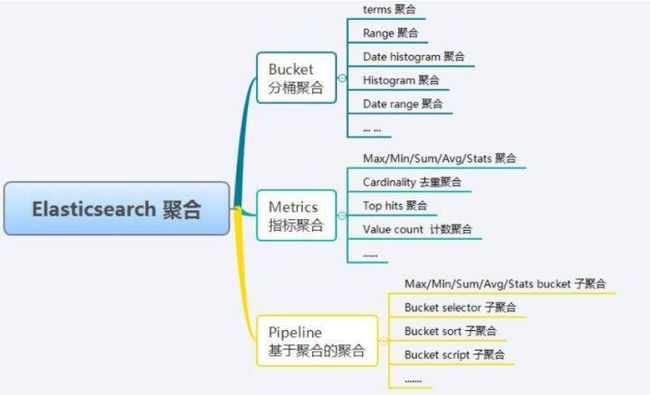
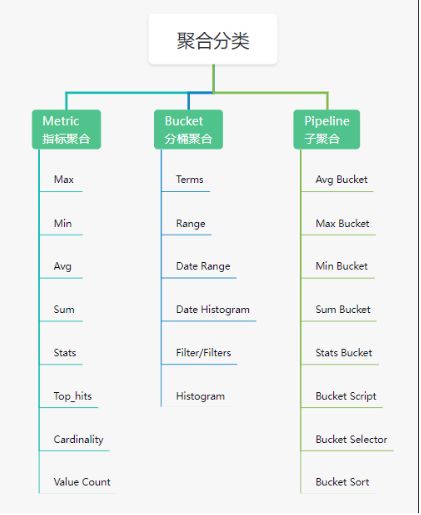
聚合分类
编辑切换为居中
添加图片注释,不超过 140 字(可选)
编辑
添加图片注释,不超过 140 字(可选)
分桶聚合(bucket)
terms
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-bucket-terms-aggregation.html
# 按照作者统计文档数
POST bilili_elasticsearch/_search
{
"size": 0,
"aggs": {
"agg_user": {
"terms": {
"field": "user",
"size": 1
}
}
}
}date_histogram
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-bucket-datehistogram-aggregation.html
# 按照up_time 按月进行统计
POST bilili_elasticsearch/_search
{
"size": 0,
"aggs": {
"agg_up_time": {
"date_histogram": {
"field": "up_time",
"calendar_interval": "month"
}
}
}
}指标聚合 (metrics)
Max
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-metrics-max-aggregation.html
# 获取up_time最大的
POST bilili_elasticsearch/_search
{
"size": 0,
"aggs": {
"agg_max_up_time": {
"max": {
"field": "up_time"
}
}
}
}Top_hits
官网文档地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-metrics-top-hits-aggregation.html
# 根据user聚合只取一个聚合结果,并且获取命中数据的详情前3条,并按照指定字段排序
POST bilili_elasticsearch/_search
{
"size": 0,
"aggs": {
"terms_agg_user": {
"terms": {
"field": "user",
"size": 1
},
"aggs": {
"top_user_hits": {
"top_hits": {
"_source": {
"includes": [
"video_time",
"title",
"see",
"user",
"up_time"
]
},
"sort": [
{
"see":{
"order": "desc"
}
}
],
"size": 3
}
}
}
}
}
}
// 返回结果如下
{
"took" : 91,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1000,
"relation" : "eq"
},
"max_score" : null,
"hits" : [ ]
},
"aggregations" : {
"terms_agg_user" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 975,
"buckets" : [
{
"key" : "Elastic搜索",
"doc_count" : 25,
"top_user_hits" : {
"hits" : {
"total" : {
"value" : 25,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "bilili_elasticsearch",
"_id" : "5ccCVoQBUyqsIDX6wIcm",
"_score" : null,
"_source" : {
"video_time" : "03:45",
"see" : "92",
"up_time" : "2021-03-19",
"title" : "Elastic 社区大会2021: 用加 Gatling 进行Elasticsearch的负载测试,寓教于乐。",
"user" : "Elastic搜索"
},
"sort" : [
"92"
]
},
{
"_index" : "bilili_elasticsearch",
"_id" : "8scCVoQBUyqsIDX6wIgn",
"_score" : null,
"_source" : {
"video_time" : "10:18",
"see" : "79",
"up_time" : "2020-10-20",
"title" : "为Elasticsearch启动htpps访问",
"user" : "Elastic搜索"
},
"sort" : [
"79"
]
},
{
"_index" : "bilili_elasticsearch",
"_id" : "7scCVoQBUyqsIDX6wIcm",
"_score" : null,
"_source" : {
"video_time" : "04:41",
"see" : "71",
"up_time" : "2021-03-19",
"title" : "Elastic 社区大会2021: Elasticsearch作为一个地理空间的数据库",
"user" : "Elastic搜索"
},
"sort" : [
"71"
]
}
]
}
}
}
]
}
}
}子聚合 (Pipeline)
Pipeline:基于聚合的聚合 官网文档地址:https://www.elastic.co/guide/...
bucket_selector
官网文档地址:https://www.elastic.co/guide/...
# 根据order_date按月分组,并且求销售总额大于1000
POST kibana_sample_data_ecommerce/_search
{
"size": 0,
"aggs": {
"date_his_aggs": {
"date_histogram": {
"field": "order_date",
"calendar_interval": "month"
},
"aggs": {
"sum_aggs": {
"sum": {
"field": "total_unique_products"
}
},
"sales_bucket_filter": {
"bucket_selector": {
"buckets_path": {
"totalSales": "sum_aggs"
},
"script": "params.totalSales > 1000"
}
}
}
}
}
}真题演练
earthquakes索引中包含了过去30个月的地震信息,请通过一句查询,获取以下信息
l 过去30个月,每个月的平均 mag
l 过去30个月里,平均mag最高的一个月及其平均mag
l 搜索不能返回任何文档
max_bucket 官网地址:https://www.elastic.co/guide/en/elasticsearch/reference/8.1/search-aggregations-pipeline-max-bucket-aggregation.html
POST earthquakes/_search
{
"size": 0,
"query": {
"range": {
"time": {
"gte": "now-30M/d",
"lte": "now"
}
}
},
"aggs": {
"agg_time_his": {
"date_histogram": {
"field": "time",
"calendar_interval": "month"
},
"aggs": {
"avg_aggs": {
"avg": {
"field": "mag"
}
}
}
},
"max_mag_sales": {
"max_bucket": {
"buckets_path": "agg_time_his>avg_aggs"
}
}
}
}