回归随机森林(RandomForestRegression)1:生成折线图与散点图(附代码)
原博地址 https://me.csdn.net/Leaze932822995
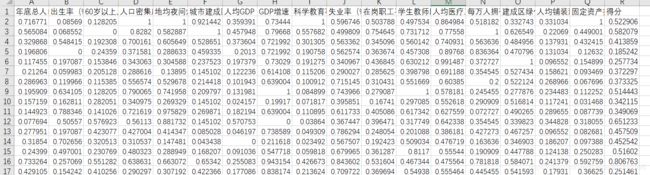
数据
我存为.xlsx格式,可以直接读取。
一行是一个样本,前17个为特征(自变量),最后一个是目标变量(因变量)。
我们进行回归预测通常就是通过一个样本的特征来预测目标变量。
这个数据是我之前写论文的时候用的,事先进行归一化处理。得分是该样本城市的人口增长。
代码
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import xlrd
import xlwt
import random
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import math
import xlrd
import xlwt
import random
###########1.读取数据部分##########
#载入数据并且打乱数据集
def load_data(StartPo,EndPo,TestProportion,FeatureNum,Shuffle,FilePath): #样本起始行数,结束行数,测试集占总样本集比重,特征数,是否打乱样本集 #如果Testproportion为0或1就训练集=测试集
#打开excel文件
workbook = xlrd.open_workbook(str(FilePath)) #excel路径
sheet = workbook.sheet_by_name('Sheet1') #sheet表
Sample = []#总样本集
train = []#训练集
test = []#测试集
TestSetSphere = (EndPo-StartPo+1)*TestProportion #测试集数目
TestSetSphere = int(TestSetSphere)#测试集数目
#获取全部样本集并打乱顺序
for loadi in range(StartPo-1,EndPo):
RowSample = sheet.row_values(loadi)
Sample.append(RowSample)
if Shuffle == 1: #是否打乱样本集
random.shuffle(Sample) #如果shuffle=1,打乱样本集
#如果Testproportion为0就训练集=测试集
if TestProportion == 0 or TestProportion == 1:
TrainSet = np.array(Sample) #变换为array
TestSet = np.array(Sample)
else:
#设置训练集
for loadtraina in Sample[:(EndPo-TestSetSphere)]:
GetTrainValue = loadtraina
train.append(GetTrainValue)
#设置测试集
for loadtesta in range(-TestSetSphere-1,-1):
GetTestValue = Sample[loadtesta]
test.append(GetTestValue)
#变换样本集
TrainSet = np.array(train) #变换为array
TestSet = np.array(test)
#分割特征与目标变量
x1 , y1 = TrainSet[:,:FeatureNum] , TrainSet[:,-1]
x2 , y2 = TestSet[:,:FeatureNum] , TestSet[:,-1]
return x1 , y1 , x2 , y2
###########2.回归部分##########
def regression_method(model):
model.fit(x_train,y_train)
score = model.score(x_test, y_test)
result = model.predict(x_test)
ResidualSquare = (result - y_test)**2 #计算残差平方
RSS = sum(ResidualSquare) #计算残差平方和
MSE = np.mean(ResidualSquare) #计算均方差
num_regress = len(result) #回归样本个数
print(f'n={num_regress}')
print(f'R^2={score}')
print(f'MSE={MSE}')
print(f'RSS={RSS}')
############绘制折线图##########
plt.figure()
plt.plot(np.arange(len(result)), y_test,'go-',label='true value')
plt.plot(np.arange(len(result)),result,'ro-',label='predict value')
plt.title('RandomForestRegression R^2: %f'%score)
plt.legend() # 将样例显示出来
plt.show()
return result
##########3.绘制验证散点图########
def scatter_plot(TureValues,PredictValues):
#设置参考的1:1虚线参数
xxx = [-0.5,1.5]
yyy = [-0.5,1.5]
#绘图
plt.figure()
plt.plot(xxx , yyy , c='0' , linewidth=1 , linestyle=':' , marker='.' , alpha=0.3)#绘制虚线
plt.scatter(TureValues , PredictValues , s=20 , c='r' , edgecolors='k' , marker='o' , alpha=0.8)#绘制散点图,横轴是真实值,竖轴是预测值
plt.xlim((0,1)) #设置坐标轴范围
plt.ylim((0,1))
plt.title('RandomForestRegressionScatterPlot')
plt.show()
###########4.预设回归方法##########
####随机森林回归####
from sklearn import ensemble
model_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=800) #esitimators决策树数量
########5.设置参数与执行部分#############
#设置数据参数部分
x_train , y_train , x_test , y_test = load_data(2,121,1,17,0,'C:\Code\MachineLearning\极差标准化数据集.xlsx') #行数以excel里为准
#起始行数2,结束行数121,训练集=测试集,特征数量17,不打乱样本集
y_pred = regression_method(model_RandomForestRegressor) #括号内填上方法,并获取预测值
scatter_plot(y_test,y_pred) #生成散点图
值得注意的是,这里的起始和结束行数我设置成了以excel表里为准。
**
效果
**
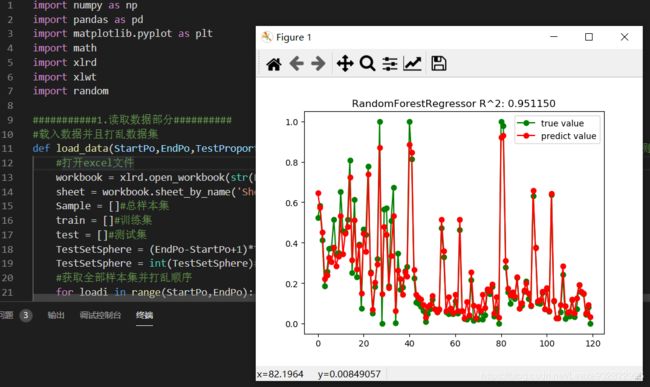
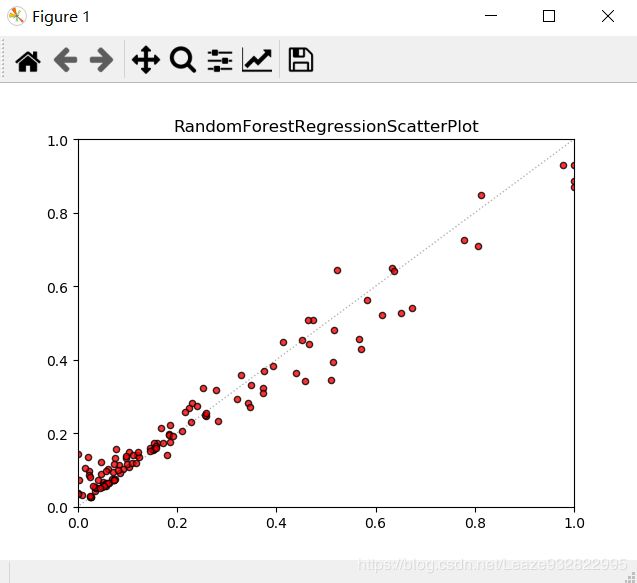
最后会出四个参数和两个图,一个是折线图,另一个是散点图。
折线图展示的测试集样本中的实测值与预测值。
散点图的横轴是实测值,竖轴是随机森林回归后的预测值。
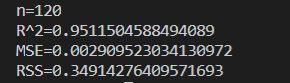
输出的四个指标分别是:
n:测试集的样本数,体现在图上就是折线图的红点或绿点数,散点图的红点数;
R方:拟合优度,模型对数据的拟合程度,取值范围在0~1,越接近1效果越好;
MSE:均方误差,MSE越小模型效果越好;
RSS:残差平方和,RSS越小模型效果越好;
一带而过,不多赘述,MSE还是RSS什么的不懂自己百度或者看代码就知道是什么意思了。
拓展
如果要计算各因变量对自变量的影响程度,可以看我下一篇文章:基于python的回归随机森林(RandomForestRegression)2:计算各特征指标的权重(IncMSE)(附代码)
另外如果要做其他的回归方法,可以参考这篇博客:使用sklearn做各种回归