基于物品的协同过滤算法
目录
- 1 相似度
-
- 1.1 Correlation-based Similarity
- 1.2 Adjusted Cosine Similarity
- 2 评分预测
- 3 代码
- 4 效果
- 5 总结
数据:数据及代码资源
1 相似度
俗话说,物以类聚人以群分。因此相距越近的个体越相似
比如距离越近越相似,两个物体的夹角越小越相似。

1.1 Correlation-based Similarity
公式

1.2 Adjusted Cosine Similarity
公式

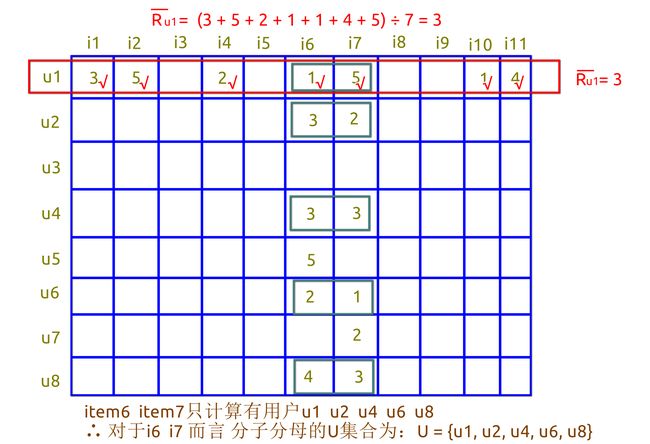
2 评分预测
根据相似度矩阵和评分矩阵推测用户的评分可能性
公式


3 代码
import numpy as np
import torch
from sklearn.model_selection import KFold
'''
nu = 943
ni = 1682
'''
def data_process(data, nu, ni):
n_data = len(data)
user_item = np.zeros((nu, ni), dtype='f4')
for i in range(n_data):
user_item[data[i,0] - 1, data[i,1] - 1] = data[i, 2]
return user_item
def pearsonSimilarity(data):
data_torch = torch.tensor(data)
nu, ni = data.shape
item_similarity = np.zeros((ni, ni))
for i in range(ni):
if i == ni - 1: continue
for j in range(i + 1, ni):
i_rating= data_torch[:, i]
j_rating= data_torch[:, j]
co_rating = torch.multiply(i_rating, j_rating)
co_index = torch.nonzero(co_rating, as_tuple=True)
# 没有共同评价的user
if len(co_index[0]) == 0: continue
i_rating = torch.index_select(i_rating, dim = 0, index=co_index[0])
j_rating = torch.index_select(j_rating, dim = 0, index=co_index[0])
i_average = torch.mean((i_rating))
j_average = torch.mean((j_rating))
i_sub_rating = i_rating - i_average
j_sub_rating = j_rating - j_average
molecule = torch.dot(i_sub_rating, j_sub_rating)
denominator1 = np.sqrt(torch.dot(i_sub_rating, i_sub_rating))
denominator2 = np.sqrt(torch.dot(j_sub_rating, j_sub_rating))
if denominator1 * denominator2 == 0: continue
item_similarity[i, j] = item_similarity[j, i] = molecule / (denominator1 * denominator2)
return item_similarity
def adjustedCosineSimilarity(data):
data_torch = torch.tensor(data)
nu, ni = data.shape
u_average = torch.sum(data_torch, axis = 1) / torch.sum(data_torch > 0, axis=1)
item_similarity = np.zeros((ni, ni))
for i in range(ni):
if i == ni - 1: continue
for j in range(i + 1, ni):
i_rating= data_torch[:, i]
j_rating= data_torch[:, j]
co_rating = torch.multiply(i_rating, j_rating)
co_index = torch.nonzero(co_rating, as_tuple=True)
# 没有共同评价的user
if len(co_index[0]) == 0: continue
i_rating = torch.index_select(i_rating, dim = 0, index=co_index[0])
j_rating = torch.index_select(j_rating, dim = 0, index=co_index[0])
aver_rating = torch.index_select(u_average, dim = 0, index=co_index[0])
i_sub_rating = i_rating - aver_rating
j_sub_rating = j_rating - aver_rating
molecule = torch.dot(i_sub_rating, j_sub_rating)
denominator1 = np.sqrt(torch.dot(i_sub_rating, i_sub_rating))
denominator2 = np.sqrt(torch.dot(j_sub_rating, j_sub_rating))
if denominator1 * denominator2 == 0: continue
item_similarity[i, j] = item_similarity[j, i] = molecule / (denominator1 * denominator2)
return item_similarity
def weighted_sum(data, similarity):
nu, ni = data.shape
data_torch = torch.tensor(data)
similarity_torch = torch.tensor(similarity)
predict_data = np.zeros((nu, ni))
for u in range(nu):
for i in range(ni):
i_similary = similarity_torch[:,i]
u_rating = data_torch[u,:]
i_similary = torch.where(i_similary <= 0, 0, i_similary)
co_user_item = torch.multiply(u_rating, i_similary)
co_index = torch.nonzero(co_user_item, as_tuple=True)
# 没有共同评价的索引
if len(co_index[0]) == 0: continue
u_rating = torch.index_select(u_rating, dim=0, index=co_index[0])
i_similary = torch.index_select(i_similary, dim=0, index=co_index[0])
molecule = torch.sum(u_rating * i_similary)
denominator = torch.sum(torch.abs(i_similary))
predict_data[u, i] = molecule / denominator
return predict_data
if __name__ == '__main__':
# user_id, item_id, rating: 943, 1682; 1408 2000; 943 50; 943 198
nu = 943
ni = 150
# raw_data = np.loadtxt('F:/课题组学习/数据/198item.data', dtype=int)
raw_data = np.loadtxt('F:/课题组学习/数据/1.csv', delimiter=",", dtype=int)
n_fold = 5
proceed_data = torch.tensor(raw_data[:, 0: 3])
kf = KFold(n_splits=n_fold, shuffle=False) # K重交叉验证,5折验证
all_data = data_process(raw_data[:, 0: 3], nu, ni)
similary = adjustedCosineSimilarity(all_data)
# similary = pearsonSimilarity(all_data)
for i in range(1, n_fold + 1):
print(" " * 8,"Fold",i, end="")
print("\n", "-" * (16 * n_fold), "\n MAE ", end="")
for train, test in kf.split(proceed_data):
# 训练集
train = data_process(np.array(proceed_data)[train], nu, ni)
# 测试集
n_test = len(test)
test = data_process(np.array(proceed_data)[test], nu, ni)
predict_data = weighted_sum(train, similary)
sum = 0
for u in range(nu):
for i in range(ni):
if test[u, i] > 0:
sum = sum + abs(predict_data[u, i] - test[u, i])
print(format(sum / n_test, '.6f'),6 * " ", end="")
print("\n*********************** run end **************************")
4 效果

5 总结
- 基于物品的协同过滤适合实时系统,因为可以提前计算相似度矩阵
- 基于物品的协同过滤适合稀疏的user-item矩阵