淘宝用户行为分析
导包 导入数据 查看数据信息
behavior_type :用户行为:
1 浏览 pv
2 收藏 collect
3 加购 cart
4 购买 buy
item_id和item_category 分别是商品id 和 商品类别号
发现"user_geohash"存在缺失值
time列为object类型 无法直接使用
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
import warnings
warnings.filterwarnings("ignore") # 忽略警告data = pd.read_csv("user.csv")
data
data.info()
data.describe() 

查看数据描述及"user_geohash"列发现地址被加密 因为对我们来说没有意义 因此删除
data.describe()
data["user_geohash"]
data.drop("user_geohash",axis=1,inplace=True)
data

替换"behavior_type"的行为类型
dic = {1:"pv",2:"collect",3:"cart",4:"buy"}
data["behavior_type"] = data["behavior_type"].map(dic)
data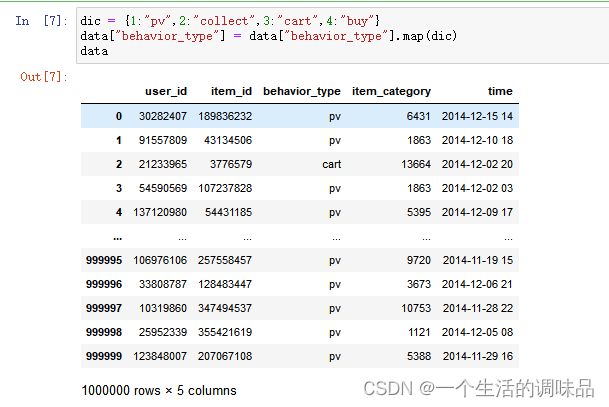
计算跳失率:只点击一次的浏览用户数量/总浏览数量
可见淘宝跳失率只有0.011%且其中可能包括一次浏览就下单购买的客户 所以跳失率非常低 淘宝足够吸引人浏览购买
# 计算跳失率 只点击一次浏览的用户数量/总用户访问量
pv = data[data["behavior_type"]=="pv"]
pv_one = pv["user_id"].value_counts() # 点击次数为1的user_id
one_cut = pv_one[pv_one==1].count() # 点击次数为1的user_id计数
BR = one_cut/pv["user_id"].count() # 跳失率
BR
计算复购率 :购买过一次以上且不在同一天购买的用户数/总用户数
计算得复购率为42% 复购率相当高 一定程度上表名产品质量稳定、性价比高、售前售后服务好,发货速度快,老客户喜欢回购
# 计算复购率
data["date"] = pd.to_datetime(data["time"].apply(lambda x:x.split()[0])) # 添加一个日期字段
data["hour"] = data["time"].apply(lambda x:int(x.split()[1])) # 添加一个小时字段
buy = data[data["behavior_type"]=="buy"] # 购买的用户id
buy_r = buy.groupby("user_id").agg({"date":"nunique"}) # 去重
mask = buy_r>=2
buy_r = buy_r[mask].count() # 购买了两次的人数
Rr = buy_r/buy["user_id"].nunique()
Rr
漏斗分析转化率 :收藏和加购本质上都是购买的中间环节 所以合并为一个环节简化分析
从行为角度来看:顾客收藏加购后的转化率在20%左右,且购买行为占总行为的45%
从用户角度来看:通过浏览直接下单的购买用户数量仅占比15.57%;通过收藏加购下单的购买用户占总用户数量的84.19%
可得知用户的收藏加购行为会增加购买转化率 如何吸引并引导用户产生购买意向收藏加购是保证购买率的关键,通过浏览直接下单的用户较少,也是需要改善和提高的环节。
# 计算转化率
pv_num = pv["behavior_type"].count() # 点击次数
col_num = data[data["behavior_type"]=="collect"]["behavior_type"].count() # 收藏次数
car_num = data[data["behavior_type"]=="cart"]["behavior_type"].count() # 加购次数
buy_num = buy["behavior_type"].count() # 购买次数
mid_num = col_num+car_num
CR = pd.DataFrame({"行为":["buy","mid","pv"],"次数":[buy_num,mid_num,pv_num]})
CR["下一环节转化率"] = [CR["次数"][0]/CR["次数"][1],CR["次数"][1]/CR["次数"][2],1]
CR["转化率"] = buy_num/CR["次数"] # [buy_num/pv_num,buy_num/mid_num,1]
CR
import plotly.express as px
pxt = px.funnel(CR[["行为","转化率"]],x="转化率",y="行为")
pxt.show()
pxt = px.funnel(CR[["行为","下一环节转化率"]],x="下一环节转化率",y="行为")
pxt.show()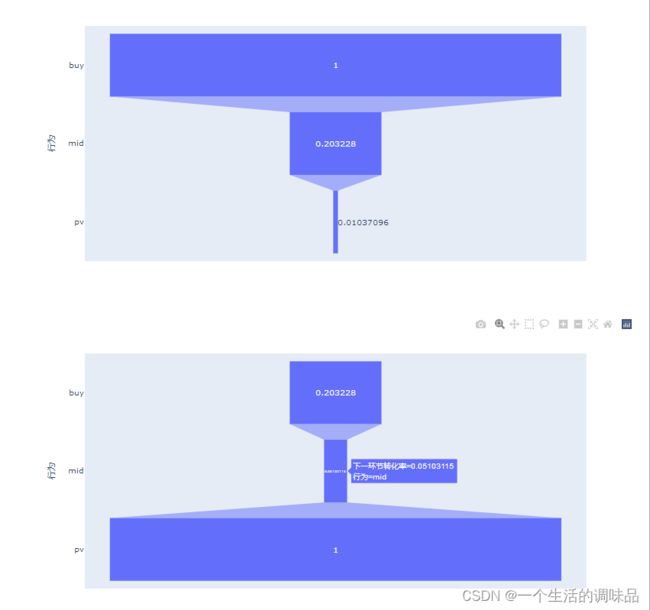
mask1 = data["behavior_type"]=="collect"
mask2 = data["behavior_type"]=="cart"
mask = mask1|mask2
col_cart_user = data[mask] # 收藏和加购的user_id
buy_user = buy["user_id"].drop_duplicates(keep="last") # 购买id去重
col_cart_user = col_cart_user["user_id"].drop_duplicates(keep="last") # 收藏加购id去重
res = pd.merge(buy_user,col_cart_user)["user_id"].nunique() # 联合二表找出收藏加购且购买的人数
res1 = [res,buy_user.nunique()-res] # 收藏加购且购买占总购买人数的比重
# 画图
plt.figure(figsize=(15,10))
plt.subplot(2,1,1)
values = [buy["user_id"].nunique(),data["user_id"].nunique()-buy["user_id"].nunique()]
label = ["购买行为","非购买行为"]
space = [0.05,0.1]
plt.pie(values,labels=label,explode=space,shadow=True,autopct="%.2f%%",colors=["r","salmon"],textprops={'fontsize': 15})
plt.subplot(2,1,2)
label = ["收藏加购且购买人数","仅浏览购买总人数"]
plt.pie(res1,labels=label,explode=space,shadow=True,autopct="%.2f%%",colors=["r","salmon"],textprops={'fontsize': 15})
plt.show()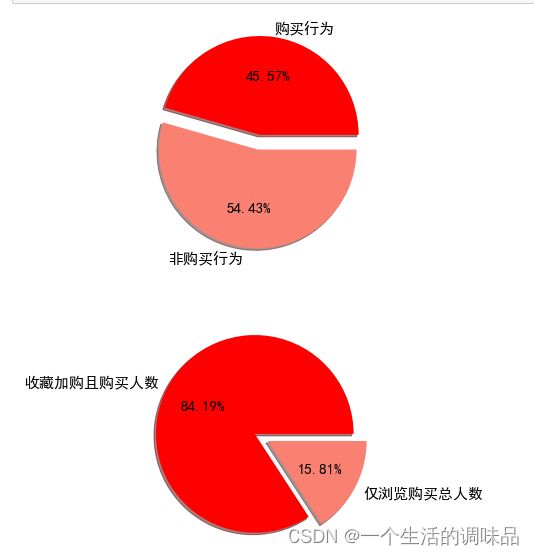
通过RFM模型进行用户类型划分,因数据没有M消费金额的数据,所以仅做RF模型分析
R:最近一次消费距今时长
F:消费次数(频率)
通过R、F的表现,用户类型大致分为四类:
重要保持客户
流失客户(非重要客户)
重要发展客户(新客户)
重要价值客户
因此我们初步使用K均值聚类模型进行用户类型划分
创建购买id及其购买次数、最近消费距今的时长表便于分析
查看描述数据,发现极差较大,影响K均值模型精度,通过seaborn进行异常值确定并处理数据
buy1 = buy.groupby("user_id").agg({"behavior_type":"count"}) # 每个购买id的购买次数
buy2 = buy.groupby("user_id").agg({"date":"max"}) # 每个购买id最近的购买日期
buy_new = pd.merge(buy1,buy2,on="user_id") # 用过id联合两个表
buy_new["date"] = (pd.to_datetime("2014-12-20")-buy_new["date"]).dt.days # 计算距今时间
buy_new.rename(columns={"behavior_type":"frequency"},inplace=True) # 修改列名 得到每个id购买次数和最近一次消费至今的时长
buy_new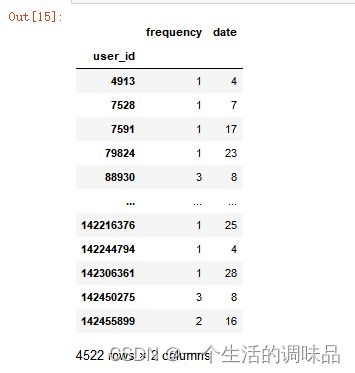
buy_new.describe()
可以看到购买次数大致在1-7次且数据内外限在-2到6之间,且按照逻辑我们留下购买次数为7次及以下的数据
import seaborn as sns
sns.boxplot(buy_new["frequency"])
plt.show()
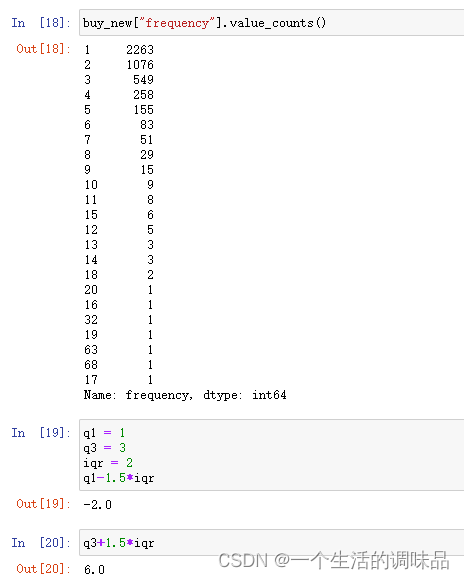
buy_new["frequency"].value_counts()
q1 = 1
q3 = 3
iqr = 2
q1-1.5*iqr
q3+1.5*iqr 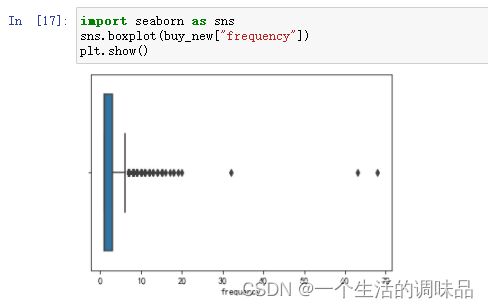
buy_new = buy_new[buy_new["frequency"]<=7]
buy_new.describe() 
同样我们对频率字段也处理一下
可以得知频率字段分布相对平均,根据频率逻辑我们就不进行处理了
sns.boxplot(buy_new["date"])
plt.show()
buy_new["date"].value_counts()
因为两个字段的数值差距比较大,所以我们进行数据标准化处理:
(字段各数据-字段平均值)/字段标准差
buy_new1 = (buy_new-buy_new.mean())/buy_new.std()
buy_new1.describe() 
导入KMeans模型并训练预测获取核心点坐标 通过核心点我们可以用核心点索引将用户进行分类
0 :重要保持客户
1 :流失客户(非重要客户)
2 :重要发展客户(新客户)
3 :重要价值客户
import sklearn.cluster as sc
model = sc.KMeans(n_clusters=4)
model.fit(buy_new1)
res = model.labels_
res
pd.DataFrame(model.labels_).value_counts()
model.cluster_centers_
画图查看分类并保存Excel (这里前期数组使用的格式不对 需要处理一下列标签 有高手可以指导一下更简单的方法)
得到的图像大致这样 (可能是因为数据的原因 聚类有点奇怪?还是我数据用的不对 还需要优化)
cus_0 = buy_new1[res==0]
cus_1 = buy_new1[res==1]
cus_2 = buy_new1[res==2]
cus_3 = buy_new1[res==3]
cus_0["user_id"]=cus_0.index
cus_0.index=[np.arange(0,2005)]
cus_1["user_id"]=cus_1.index
cus_1.index=[np.arange(0,1400)]
cus_2["user_id"]=cus_2.index
cus_2.index=[np.arange(0,741)]
cus_3["user_id"]=cus_3.index
cus_3.index=[np.arange(0,289)]
cus_0 = pd.DataFrame(cus_0["user_id"])
cus_0.columns=["user_id"]
cus_1 = pd.DataFrame(cus_1["user_id"])
cus_1.columns=["user_id"]
cus_2 = pd.DataFrame(cus_2["user_id"])
cus_2.columns=["user_id"]
cus_3 = pd.DataFrame(cus_3["user_id"])
cus_3.columns=["user_id"]
x=buy_new["frequency"]
y=buy_new["date"]
plt.figure(figsize=(10,5),facecolor="white")
plt.scatter(x,y,c=res)
plt.savefig("图片",dpi=500, bbox_inches='tight')
plt.show()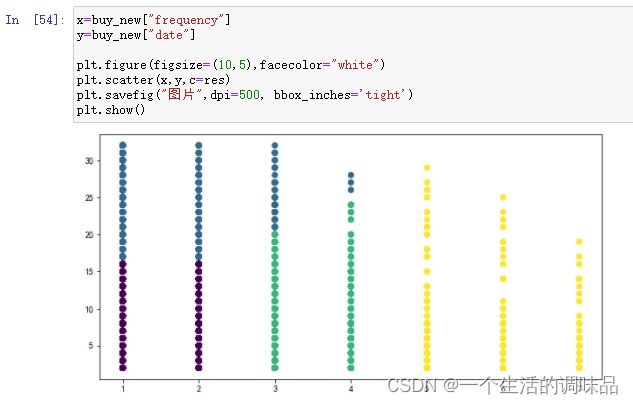
write = pd.ExcelWriter("cus.xlsx")
cus_0.to_excel(write,"0")
cus_1.to_excel(write,"1")
cus_2.to_excel(write,"2")
cus_3.to_excel(write,"3")
write.save()月用户活跃情况分析:
行为和用户活跃趋势大致相同,在双十二附近有一个峰值且用户在十二月明显较十一月更加活跃。
可能是因为双十二的预热,可以看到电商兴起初期,电商平台活动也受到大家的普遍接受,且可以展现出参与电商活动对电商商家的重要性。
sns.set(style='darkgrid',context='notebook') # font_scale=0.5 默认字体大小
plt.rcParams["font.sans-serif"]=["SimHei"] #显示中文标签,防止出现中文不显示的情况
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(16,15)) # figure要在头部
plt.subplot(2,1,1) # 两行一列第一张
res = data.groupby("date").agg({"user_id":"count"}) # 总活跃数
plt.plot(res)
plt.title("用户总活跃数")
plt.xticks(rotation=45)
plt.savefig("图片1",dpi=500, bbox_inches='tight')
plt.subplot(2,1,2) # 两行一列第二张
res = data.groupby("date").agg({"user_id":"nunique"}) # 用户活跃数
plt.plot(res,color="r")
plt.title("用户活跃数")
plt.savefig("图片1",dpi=500, bbox_inches='tight')
plt.xticks(rotation=45)
plt.show() 
周用户活跃情况分析:
用户在周二到周四活跃度比较高,可能用户会通过淘宝调节心情,而在周末,用户可能会外出逛实体店或者出去玩,对电商影响较明显,周一往往刚开始工作心情还不错不选择网上消费来消遣。
因此电商商家可以在周中用户比较活跃的时候加大活动力度,引导顾客消费。
data["weekdays"] = data["date"].apply(lambda x:x.weekday())
res = data.groupby("weekdays").agg({"user_id":"count"})
plt.figure(figsize=(15,5))
plt.plot(res)
plt.title("每周用户活跃情况")
plt.xticks([0,1,2,3,4,5,6],["周一","周二","周三","周四","周五","周六","周日"])
plt.show()
日用户活跃情况分析:
可以看到用户的一天在10时-15时、19-22时较为活跃,符合人们的作息时间,同时商家想安排活动尽量在晚上18点开始准备,这样正好可以赶上19-22时活跃的爆发期。
res = data.groupby("hour").agg({"user_id":"count"})
plt.figure(figsize=(15,5))
plt.plot(res,color="b")
plt.xticks(np.arange(0,24))
plt.grid(axis="y")
plt.show()