参考李航老师的《统计学习方法》第二版
知识点:
- 感知机是二分类的线性分类模型,属于判别模型
- 旨在求出将训练数据进行线性划分的分离超平面,目标求得一个超平面将正负例完全正确分开
- 基于误分类的损失函数:L(w,b) = -∑yi(w·xi+b) 这里xi是误分类的点,损失函数是非负的,对应误分类点到分离超平面的总距离,如果没有误分类的点,损失函数的值为0
- 利用随机梯度下降法对损失函数进行极小化。首先任意选取一个超平面w0,b0,然后采用梯度下降法不断极小化损失函数,极小化过程不是一次使所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降
- 当训练数据集线性可分时,感知机学习算法原始形式迭代是收敛的
- 感知机算法存在无穷多个解,这些解依赖初值的选择、迭代过程中误分类点的选择顺序
原始形式算法:
- 选取初值:w0,b0
- 在训练集中选取一个数据(xi,yi)
- 判断是否误分类,如果误分类即yi(w·xi+b)<=0,则调整参数w和b:w=w+ηyixi b=b+ηyi
- 转至第2步,直到不存在误分类点
原始形式代码实现:
from sklearn.datasets import load_iris
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
'''数据准备'''
# 鸢尾花数据集
iris = load_iris()
data = pd.DataFrame(iris.data, columns=iris.feature_names)
X = np.array(data.iloc[:100, [0, 1]])
y = iris.target[:100]
y = [-1 if i==0 else 1 for i in y]
# 数据集可视化
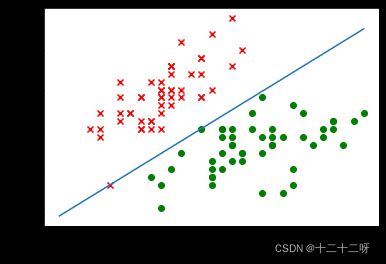
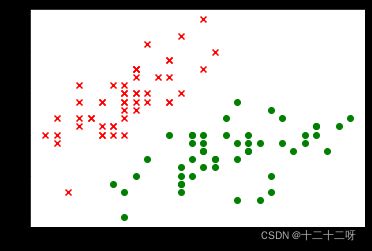
plt.scatter(X[0:50, 0], X[0:50, 1], c="red", marker="x")
plt.scatter(X[50:100, 0], X[50:100, 1], c="green")
'''参数初始化'''
w = np.array([0,0])
b = 0
learning_rate = 1
'''定义损失函数'''
def loss_func(x,y,w,b):
loss = y*(np.dot(w,x)+b)
return loss
'''梯度下降函数'''
def gradient_func(x,y,w,b):
w = w + learning_rate*y*x
b = b + learning_rate*y
return w,b
'''模型训练'''
def train(X,y,w,b):
mistake = []
for i,x in enumerate(X):
loss = loss_func(x,y[i],w,b)
if loss<=0:
w,b=gradient_func(x,y[i],w,b)
mistake.append(1)
return w,b,mistake
sum_mistake = 1
while (sum_mistake>0):
w,b,mistake = train(X,y,w,b)
sum_mistake = np.sum(mistake)
print("finish")
'''可视化结果'''
print("w:",w)
print("b:",b)
x = np.linspace(4, 7, 10)
y = -(w[0] * x + b) / w[1]
plt.plot(x, y)
plt.scatter(X[:50, 0], X[:50, 1])
plt.scatter(X[50:100, 0], X[50:100, 1])
plt.xlabel('feature1')
plt.ylabel('feature2')
w: [ 79.8 -101.4]
b: -126