NAS-FPN论文解析
物体检测也是深度学习视觉领域内一个非常重要的应用场景,物体检测的主要方法目前有Faster R-CNN、SSD、YOLO等系列算法,以及近年涌现的FPN等改进方法。下面我们以NAS-FPN为例,介绍NAS在深度学习物体检测中的应用。
NAS-FPN论文的全名是NAS-FPN: Learning Scalable Feature Pyramid Architecture for Object Detection。这是一篇由谷歌大脑团队提出来的针对FPN特征图的NAS方法,不同于前面博客介绍的方法,这篇论文并不是把NAS用来搜索整个网络或者单元结构,而是用来重新组合和融合神经网络已经提取的特征图。换句话说,网络的backbone是不变的,还是采用RetinaNet,在此基础上设计了额外的NAS方法对RetinaNet提取的特征图进行组合和更新,以获得更好的检测精度。
图1. FPN和NAS-FPN的网络结构图
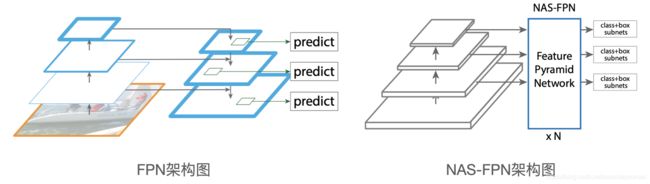
首先对比一下FPN和NAS-FPN的网络架构图。图1中左边是FPN的架构图,FPN左侧的网络负责提取不同scale的特征图,右侧的网络将低分辨率的特征图经过放大后融合到高分辨率的特征图中,然后对不同scale的特征图去预测物体的位置和类别。图1右边的NAS-FPN代替了FPN中右侧的方法,论文提出了一种Merging cell的概念,对网络提取的特征重新进行融合,得到新的不同scale的特征图,然后用于物体检测最后阶段的位置和类别预测。
NAS-FPN对5个scale尺度上的特征图进行重组,5个scale的特征图分别表示为:{C3, C4, C5, C6, C7},相对输入图片的步长(缩放倍数)分别为{8, 16, 32, 64, 128},其中C3、C4、C5是RetinaNet提取的三个scale上的特征层,C6和C7是把C5特征层池化后得到的。
Merging cell是NAS-FPN的核心设计,它负责搜索、抽取输入特征图以及经过Binary操作得到输出特征图。具体步骤如下:
- 从候选特征层中选取2个作为输入特征层
- 选择输出特征的分辨率
- 选择一个Binary操作将两个输入特征层整成新的输出特征,加入候选特征层中
上述步骤重复循环进行,初代的候选特征层就是5个scale的特征图,最后5个循环分别生成最终输出特征层{P3, P4, P5, P6, P7},这5个特征层的分辨率分别与最初的5个候选特征层相对应。Merging cell通常会叠加多个,上一个Merging cell的5个输出特征层作为下一个Merging cell的5个最初候选特征层。
Merging cell的操作过程和Binary操作如下图所示。
图2. Merging cell的操作过程和Binary操作图
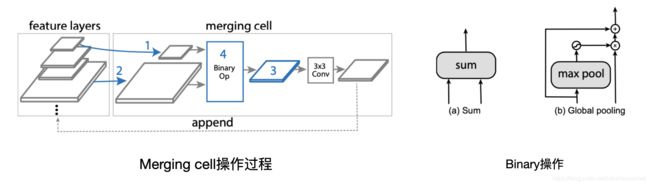
步骤3中的Binary操作有两种选择,一种是直接求和;还有一种是把第一个特征层进行max池化和sigmoid后按像素点乘以第二个特征层,再加上第一个特征层。
Merging cell中如果选取的两个输入特征层先不一样,则先池化到步骤2中选择的输出分辨率,再进行Binary操作。
Merging cell中的步骤采用的是NASNet中Controller RNN的方法,用强化学习去更新RNN的参数。
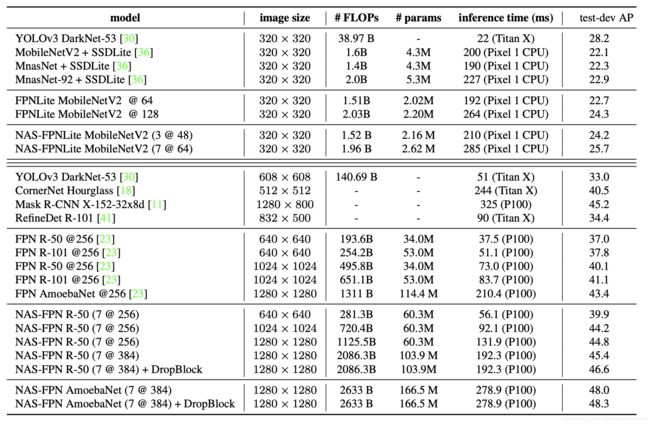
作者在COCO数据集上做实验,先在小网络(ResNet-10)上训练Controller RNN,再换成大网络(RetinaNet)继续训练。使用100个TPU,每个模型训练50个epoch后的检测精度AP作为reward,训练8000个模型。
论文给出了搜索出来的FPN选择方案,如下图所示。
图3. NAS-FPN Merging cell搜索结果
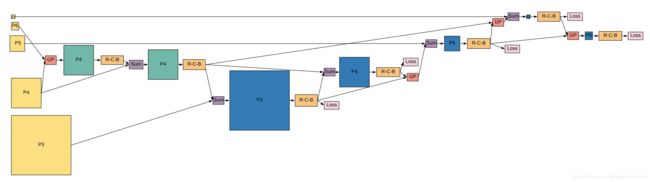
图3中的左侧黄色方形框是输入特征层,中间和右边的蓝色方框是输出特征层。
论文在COCO数据集上对比了NAS-FPN和人工设计目标检测算法,可以看出在相同输入分辨率、同等模型参数量的条件下,NAS-FPN超过了传统人工设计的物体检测网络。如果再加上以AmoebaNet为backbone,检测精度则会进一步提高。
图4. NAS-FPN在COCO数据集上的实验性能