颜色和移动物体识别系统
颜色和移动物体识别系统
1.开发工具
Python版本:Anaconda 的python环境3.8版本
开发软件:Pycharm社区版
识别模型:深度学习模型,普通学习模型
相关模块:opencv-python=3.4.8.29模块
2.环境搭建
安装Anaconda并将路径添加到环境变量,安装Pycharm并将路径添加到环境变量,使用pip安装需要的相关模块即可。
3.程序流程
一、颜色识别系统
1)打开pycharm,创建一个文件夹和一个.py文件

2)导入两个库,cv2和numpy库
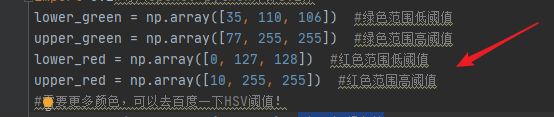
3)设置绿色和红色的高低阈值
4)判断是否正常打开视频
![]()
5)读取每一帧与当读取帧正常时
![]()
6)将图片转为灰色
![]()
7)根据颜色范围筛选红色和绿色
![]()
8)中值滤波处理
![]()
9)对两种颜色进行处理,寻找绿色和红色范围
![]()
10)在绿色区域画正方形并显示“Green”

11)在红色区域画正方形并显示“Red”

12)显示每一帧,等待播放,按“q”中断

13)如果视频播放完,自动跳出循环,窗口关闭
![]()
14)释放视频以及销毁所有创建的窗口

15)运行时示例截图

源码展示
import numpy as np # 导入numpy库
import cv2 # 导入opencv-python库即cv2库
lower_green = np.array([35, 110, 106]) # 绿色范围低阈值
upper_green = np.array([77, 255, 255]) # 绿色范围高阈值
lower_red = np.array([0, 127, 128]) # 红色范围低阈值
upper_red = np.array([10, 255, 255]) # 红色范围高阈值
# 需要更多颜色,可以去百度一下HSV阈值!
cap = cv2.VideoCapture("2.mp4") # 打开视频文件
num = 0
while (cap.isOpened()): # 是否正常打开视频
ret, frame = cap.read() # 读取每一帧
if ret == True: # 判断读取帧正确时
hsv_img = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV) # 将图片转为灰色以便后面处理
mask_green = cv2.inRange(hsv_img, lower_green, upper_green) # 根据颜色范围筛选绿色
mask_red = cv2.inRange(hsv_img, lower_red, upper_red) # 根据颜色范围筛选红色
mask_green = cv2.medianBlur(mask_green, 7) # 中值滤波
mask_red = cv2.medianBlur(mask_red, 7) # 中值滤波
mask = cv2.bitwise_or(mask_green, mask_red) # 对两种颜色进行处理
mask_green, contours, hierarchy = cv2.findContours(mask_green, cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_NONE) # 寻找绿色范围
mask_red, contours2, hierarchy2 = cv2.findContours(mask_red, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_NONE) # 寻找红色范围
for cnt in contours:
(x, y, w, h) = cv2.boundingRect(cnt)
cv2.rectangle(frame, (x, y), (x + w, y + h), (0, 255, 255), 2)
cv2.putText(frame, "Green", (x, y - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 255, 0), 2)
# 在绿色区域画正方形并显示Green
for cnt2 in contours2:
(x2, y2, w2, h2) = cv2.boundingRect(cnt2)
cv2.rectangle(frame, (x2, y2), (x2 + w2, y2 + h2), (0, 255, 255), 2)
cv2.putText(frame, "Red", (x2, y2 - 5), cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
# 在红色区域画正方形并显示Green
cv2.imshow("dection", frame) # 显示每一帧
if cv2.waitKey(20) & 0xFF == ord("q"): # 类似中断播放的按键,按q跳出循环终止播放
break
else:
break
cap.release() # 释放视频
cv2.destroyAllWindows() # 将创建的所有的窗口毁灭
二、移动物体识别系统
1)打开pycharm,创建一个文件夹和一个.py文件

2)导入cv2库,该系统只需要一个cv2库

3)读取视频的路径
![]()
4)找出视频的长和宽,并且输出
![]()
5)给椭圆形描点并赋值给变量,并给background赋值
![]()
6)判断能否正确读取视频流
![]()
7)读取视频并判断视频是否结束
![]()
8)对帧进行预处理,先转灰度,再进行高斯滤波
![]()
9)将第一帧设置为整个输入的背景

10)对于每个从背景之后读取的帧都会计算其与背景之间的差异,并得到一个差分图
![]()
11)应用阈值来得到一幅黑白图像,并通过下面代码来膨胀图像,从而对孔和缺陷进行归一化处理

12)对移动的物体显示矩形框

13)播放视频并且按“q”退出视频

14)如果视频播放结束。跳出循环并关闭窗口

15)释放视频和销毁所有创造的窗口

16)运行示例截图

源码展示
import cv2 # 导入opencv-python库即cv2库
camera = cv2.VideoCapture("5.mp4") # 读取视频路径
size = (int(camera.get(cv2.CAP_PROP_FRAME_WIDTH)), int(camera.get(cv2.CAP_PROP_FRAME_HEIGHT))) # 找出视频的长和宽并赋给变量
print('size:' + repr(size)) # 输出图片的长和宽
es = cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (9, 4)) # 以椭圆形描点并赋值给变量
background = None # 给background赋予初始值None
while (camera.isOpened()): # 能否正确读取视频流
grabbed, frame_lwpCV = camera.read()
if grabbed == True:
gray_lwpCV = cv2.cvtColor(frame_lwpCV, cv2.COLOR_BGR2GRAY) # 对帧进行预处理,先转灰度图,再进行高斯滤波。
gray_lwpCV = cv2.GaussianBlur(gray_lwpCV, (21, 21),0) # 用高斯滤波进行模糊处理,进行处理的原因:每个输入的视频都会因自然震动、光照变化或者摄像头本身等原因而产生噪声。对噪声进行平滑是为了避免在运动和跟踪时将其检测出来。
# 将第一帧设置为整个输入的背景
if background is None:
background = gray_lwpCV
continue
# 对于每个从背景之后读取的帧都会计算其与背景之间的差异,并得到一个差分图(different map)。
# 还需要应用阈值来得到一幅黑白图像,并通过下面代码来膨胀(dilate)图像,从而对孔(hole)和缺陷(imperfection)进行归一化处理
diff = cv2.absdiff(background, gray_lwpCV)
diff = cv2.threshold(diff, 148, 255, cv2.THRESH_BINARY)[1] # 二值化阈值处理
diff = cv2.dilate(diff, es, iterations=2) # 形态学膨胀
image, contours, hierarchy = cv2.findContours(diff.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE) # 该函数计算一幅图像中目标的轮廓
# 显示矩形框
for c in contours:
if cv2.contourArea(c) < 15: # 对于矩形区域,只显示大于给定阈值的轮廓,所以一些微小的变化不会显示。对于光照不变和噪声低的摄像头可不设定轮廓最小尺寸的阈值
continue
(x, y, w, h) = cv2.boundingRect(c) # 该函数计算矩形的边界框
cv2.rectangle(frame_lwpCV, (x, y), (x + w, y + h), (0, 255, 0), 2) # 画出有移动物体的矩形
cv2.imshow('contours', frame_lwpCV) # 播放视频
key = cv2.waitKey(20) & 0xFF
# 按'q'健退出循环
if key == ord('q'):
break
else:
break
camera.release() # 释放视频
cv2.destroyAllWindows() # 将创建的所有的窗口毁灭