基于深度学习的轻量级行人检测
文章目录
- 前言
- 一、Yolo-fastest是什么?
- 二、训练过程
-
- 1.数据处理
- 2.模型训练
- 总结
前言
最近在研究一些轻量级的模型,顺手复现了一个轻量级行人检测模型,数据集用的是WiderPerson数据集,下载地址:http://www.cbsr.ia.ac.cn/users/sfzhang/WiderPerson/。用的是Yolo-fastest模型,这个模型最小的只有1.3M,单核每秒148帧,太强了;里面有个xl版本3.5M精度也很高。代码地址:https://github.com/dog-qiuqiu/Yolo-Fastest
这个作者各种过程写得比较简单,很多东西要自己摸索。训练过程什么的另一个作者写的比较详细:https://github.com/AlexeyAB/darknet
一、Yolo-fastest是什么?
全网最最最轻量级检测网络yolo-fastest,这个模型非常小,号称目前最快的yolo算法——大小只有1.3M,单核每秒148帧,移动设备上也可以轻易部署。
二、训练过程
1.数据处理
这个数据集标签文件是这样的,
第一行是目标个数,第二行开始就是标签信息,第一列为种类,后面就是最标注点坐标。

这里总共有5类,其中有2类是我不需要的,所以我给他们做了数据清洗。接下来就是将其数据类型转为VOC格式,代码如下:
import os
import numpy as np
import scipy.io as sio
import shutil
from lxml.etree import Element, SubElement, tostring
from xml.dom.minidom import parseString
import cv2
def make_voc_dir():
# labels 目录若不存在,创建labels目录。若存在,则清空目录
if not os.path.exists('../VOC2007/Annotations'):
os.makedirs('../VOC2007/Annotations')
if not os.path.exists('../VOC2007/ImageSets'):
os.makedirs('../VOC2007/ImageSets')
os.makedirs('../VOC2007/ImageSets/Main')
if not os.path.exists('../VOC2007/JPEGImages'):
os.makedirs('../VOC2007/JPEGImages')
if __name__ == '__main__':
classes = {'1': 'pedestrians',
'2': 'riders',
'3': 'partially'}
VOCRoot = '../VOC2007'
widerDir = 'WiderPerson' # 数据集所在的路径
wider_path = 'WiderPerson/trainval.txt'
make_voc_dir()
with open(wider_path, 'r') as f:
imgIds = [x for x in f.read().splitlines()]
for imgId in imgIds:
objCount = 0 # 一个标志位,用来判断该img是否包含我们需要的标注
filename = imgId + '.jpg'
img_path = '../WiderPerson/images/' + filename
print('Img :%s' % img_path)
img = cv2.imread(img_path)
width = img.shape[1] # 获取图片尺寸
height = img.shape[0] # 获取图片尺寸 360
node_root = Element('annotation')
node_folder = SubElement(node_root, 'folder')
node_folder.text = 'JPEGImages'
node_filename = SubElement(node_root, 'filename')
node_filename.text = 'VOC2007/JPEGImages/%s' % filename
node_size = SubElement(node_root, 'size')
node_width = SubElement(node_size, 'width')
node_width.text = '%s' % width
node_height = SubElement(node_size, 'height')
node_height.text = '%s' % height
node_depth = SubElement(node_size, 'depth')
node_depth.text = '3'
label_path = img_path.replace('images', 'Annotations') + '.txt'
with open(label_path) as file:
line = file.readline()
count = int(line.split('\n')[0]) # 里面行人个数
line = file.readline()
while line:
cls_id = line.split(' ')[0]
xmin = int(line.split(' ')[1]) + 1
ymin = int(line.split(' ')[2]) + 1
xmax = int(line.split(' ')[3]) + 1
ymax = int(line.split(' ')[4].split('\n')[0]) + 1
line = file.readline()
cls_name = classes[cls_id]
obj_width = xmax - xmin
obj_height = ymax - ymin
difficult = 0
if obj_height <= 6 or obj_width <= 6:
difficult = 1
node_object = SubElement(node_root, 'object')
node_name = SubElement(node_object, 'name')
node_name.text = cls_name
node_difficult = SubElement(node_object, 'difficult')
node_difficult.text = '%s' % difficult
node_bndbox = SubElement(node_object, 'bndbox')
node_xmin = SubElement(node_bndbox, 'xmin')
node_xmin.text = '%s' % xmin
node_ymin = SubElement(node_bndbox, 'ymin')
node_ymin.text = '%s' % ymin
node_xmax = SubElement(node_bndbox, 'xmax')
node_xmax.text = '%s' % xmax
node_ymax = SubElement(node_bndbox, 'ymax')
node_ymax.text = '%s' % ymax
node_name = SubElement(node_object, 'pose')
node_name.text = 'Unspecified'
node_name = SubElement(node_object, 'truncated')
node_name.text = '0'
image_path = VOCRoot + '/JPEGImages/' + filename
xml = tostring(node_root, pretty_print=True) # 'annotation'
dom = parseString(xml)
xml_name = filename.replace('.jpg', '.xml')
xml_path = VOCRoot + '/Annotations/' + xml_name
with open(xml_path, 'wb') as f:
f.write(xml)
# widerDir = '../WiderPerson' # 数据集所在的路径
shutil.copy(img_path, '../VOC2007/JPEGImages/' + filename)
由于是用的yolo模型,所以还要将转出来的标签转为yolo格式,下面是xml文件转yolo训练时所需要的txt格式,代码入下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'valid']
classes = ["person"] # 自己训练的类别
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('WiderPerson/Annotations/%s.xml' % (image_id))
out_file = open('WiderPerson/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls == 'you':
cls = 0
else:
# Dontla 20200523
# origin:cls = 1
cls = 0
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
# Dontla 20200523
# origin:out_file.write(str(cls) + " " + " ".join([str(a) for a in bb]) + '\n')
out_file.write(str(cls) + " " + " ".join([str('{:6f}'.format(a)) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('WiderPerson/labels/'):
os.makedirs('WiderPerson/labels/')
image_ids = open('WiderPerson/ImageSets/Main/%s.txt' % (image_set)).read().strip().split()
list_file = open('WiderPerson/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('WiderPerson/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
转好之后数据集就制作完成了,下面是yolo训练时所需要的标签格式:
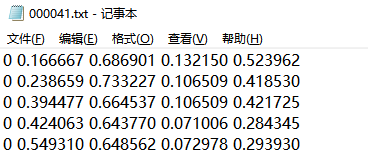
第一列是种类,后面四个是归一化处理后的标签位置信息
2.模型训练
由于自己的电脑性能不太好,所以用的是实验室的服务器。不过有一台好的服务器被占着,所以自己用的是差一点的,1070的显卡,勉强能用,就是训练速度慢了一点。
环境配置
1.ubuntu18.04
2.Cuda10.2+cudnn7.6.5
3.Opencv4.5.2
安装教程网上很多比较详细,我们直接进入yolo的编译。
将前面给的代码从github下载下来,然后解压好,进入文件夹编译。输入下面指令进行编译:
make -j8
要是出现下列情况就是编译成功:
编译好之后可以用作者的模型测试一下图片和视频:
./darknet detector test ModelZoo/yolo-fastest-1.1_coco/coco.data ModelZoo/yolo-fastest-1.1_coco/yolo-fastest-1.1.cfg ModelZoo/yolo-fastest-1.1_coco/yolo-fastest-1.1.weights data/dog.jpg
出错的话自己注意一下路径。
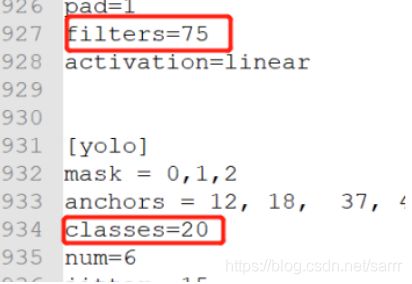
还要调一下文件种cfg的一些参数,例如我只要训练一种类型,859行的filters和866行的classes分别改为18和1,还有就是927行的filters和934行的classes也是改为18和1。classes就是识别的种类,filters=(classes+5)*3。
下面开始正式训练。
./darknet detector train data/WiderPerson/person.data data/WiderPerson/person.cfg -map
我没用作者的预训练模型,直接开始训练的,因为做的这个要求就不能用与预练模型。
有需求要预训练模型的可以自己生成:
./darknet partial yolo‐fastest‐1.1.cfg yolo‐fastest‐1.1.weights yolo‐fastest‐1.1.con
v.109 109
然后训练的时候加上就好了,训练的时候会出现一个大表格,里面会有loss值和mAP的i情况。下面是我训练好的图表:

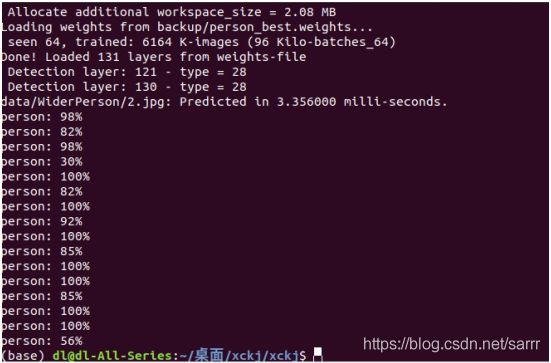
然后输入代码测试了一下这个模型:
./darknet detector test data/WiderPerson/person.data data/WiderPerson/person.cfg backup/person_best.weights data/WiderPerson/1.jpg

速度真是非常快,只用了3.35毫秒。
后续还可以在各种的移动设备上部署,现在很多设备运算速度很快,延迟又低,所以都想往设备上部署,要用到轻量级模型。
总结
复现过程种遇到不少小问题,因为之前用yolov5做过目标检测,现在用这个yolo-fastest做差异还是有一点的。当时被数据集路径困扰了好一会,就是这个模型要求train和valid的txt文件中要有图像路径,比如下面这样:

当时用的是下载的数据集的train.txt文件,一直报错,后面研究了好一会才发现必须得这样,还有就是标签文件labels要和images文件放在一个路径。这个是在ubuntu上跑的,下面这个作者是在windows下面跑的,都可以实现。
https://blog.csdn.net/weixin_41868104/article/details/115748281?spm=1001.2014.3001.5501