python相关知识的巩固-《python与量化投资从基础到实战》的python基础部分
python与量化投资从基础到实战
-
- 数据格式
- numpy
- pandas
- SciPy 插值 积分 优化 图像处理 特殊函数
-
- OLS 回归分析
- 插值
- 正态性检验
- 凸优化
- matplotlib 绘图的始祖,适合绘制简单的统计图表。
- Seaborn 绘制美观的图表
- Scikit-Learn 机器学习常用的第三方模块
-
- 决策树
- 支持向量机
- 朴素贝叶斯分类器
- 神经网络
- 模型评价方法-metric模块
- 深度学习
- 连接数据库
数据格式
字符串不可更改
列表中的元素可以修改,元组【更安全】中的元素不可修改
集合:1.进行集合操作【交集、差集、补集】2.消除重复元素
‘’’ ‘’'三引号可以换行输入输出
str='''fish
cat
fish
'''
print(str)

python中数的类型:整数型(int)长整型(long)浮点型(float)布尔型(bool)复数型(complex)
数据类:列表list【可以是不同的类型】 元组tuple 集合set 字典dict
numpy
numpy的主要对象ndarray的数据类型:整数型(np.int32)浮点型(np.float64)布尔型(bool)字符串(string) unicode(np.unicode__)
array【只允许储存相同的数据类型】
arr=np.array(['量','化'])
arr.dtype
dtype('pandas
pandas的数据对象:series一维数组【只允许储存相同的数据类型】 dataframe二维的表格型数据结构 panel三维数组
df.describe()会统计出各列的计数、平均数、方差、最小值、最大值及quantile数值
df.info()会展示数据类型。行列数和DataFrame占用的内存
map函数映射一个字典,可以实现根据已有的列建立新列。
df.drop_duplicates(subset=‘k1’,keep=‘first’)去重
df.drop([‘Unnamed:0’,axis=1])删除已有的列
df.rename(columns={‘Unnamed:0’:‘id’])重命名某些列
df.loc第一个参数是行标签,第二个参数是列标签
df.iloc第一个参数是行的位置,第二个参数是列的位置
df.ix自动根据我们给出的索引类型判断是使用位置还是标签进行切片
pd.cut(a.closeprice,bins,lables)分组,bins分组标准,lables分组名称
agg apply 用于分组聚合
SciPy 插值 积分 优化 图像处理 特殊函数
OLS 回归分析
import statsmodels.api as sm
model=sm.OLS(y,x)
插值
import scipy.interpolate as spi
ipo=spi.splrep(X,Y,k=1) #线性插值 k样条拟合顺序
iy=spi.splev(x,ipo) #三次样条插值
正态性检验
statsmodel.api 中的qqplot通过QQ图检验
凸优化
import scipy.optimize as sco
opts=sco.minimize()
min_sharpe 夏普最大化
min_volatility 收益最大化
min_return 风险最小化
matplotlib 绘图的始祖,适合绘制简单的统计图表。
import matplotlib.pyplot as plt
%matplotlib inline #更改字体以便正常显示中文
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]#用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus’]=False#用来正常显示负号
Seaborn 绘制美观的图表
import matplotlib as mpl
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#更改字体以便正常显示中文
plt.rcParams[‘font.sans-serif’]=[‘SimHei’]#用来正常显示中文标签
plt.rcParams[‘axes.unicode_minus’]=False#用来正常显示负号
sns.set_style({“font.sans-serif”:[‘Microsoft YaHei’,‘SimHei’]})#显示中文
plt.figure(figsize=(12,8))
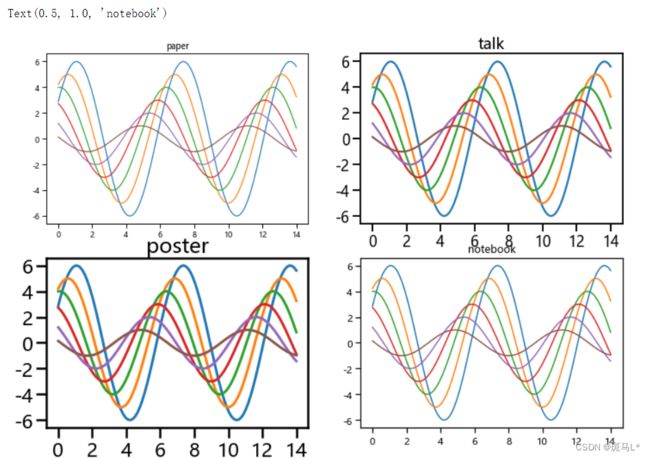
sns.set_context('paper')
plt.subplot(221)
plt.title('paper')
sinplot()
sns.set_context('talk')
plt.subplot(222)
sinplot()
plt.title('talk')
sns.set_context('poster')
plt.subplot(223)
sinplot()
plt.title('poster')
sns.set_context('notebook')
plt.subplot(224)
sinplot()
plt.title('notebook')
plt.figure(figsize=(12,8))
sns.set_palette('muted')
plt.subplot(221)
plt.title('循环')
sinplot()
sns.set_palette('Blues_r')
plt.subplot(222)
sinplot()
plt.title('渐变(深-浅)')
sns.set_palette('Blues')
plt.subplot(223)
sinplot()
plt.title('渐变(浅-深)')
sns.set_palette('RdBu')
plt.subplot(224)
sinplot()
plt.title('混合(红-蓝)')

Python可视化18|seborn-seaborn调色盘(六) - 知乎 (zhihu.com): https://zhuanlan.zhihu.com/p/180551053
Scikit-Learn 机器学习常用的第三方模块
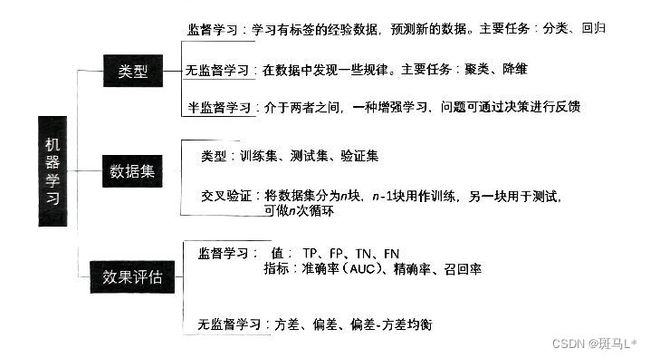
机器学习的功能主要包括分类、回归、降维和聚类。
-
分类:决策树Decision Trees 贝叶斯分类Naive Bayes 支持向量机Support Vector Machines
随机森林random forest -
回归:SVR Lasso
-
降维:主成分分析PCA 主题模型LDA
-
聚类:K-Means Gaussian
Scikit-Learn还包括特征提取、数据处理和模型评估三大模块
Scikit-Learn的模块列表
- 关于数据集的模块有sklearn. datasets。
- 关于特征预处理的模块有 sklearn. feture_extraction(特征抽取)、 sklearn.
feature_selection(特征选择)、 sklearn. preprocessing(特征预处理)和 sklearn.
random_projection(数据集合)。 - 关于模型训练的模块有 sklearn. cluster 、 sklearn. cluster. bicluste 、
sklearn. linear_model 、 sklearn. naive_bayes 、 sklearn.
naural_network 、 sklearn. svm 和 sklearn. tree 。 - 关于模型评估的模块有 sklearn. metrics 和 sklearn. cross_validation 。
- 关于其他功能的模块有sklearn. covariance和sklearn. mixture等。
决策树
对训练集进行训练
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
import sklearn
import re
from sklearn import cross_validation
import sklearn.tree as tree
data=pd.read_excel('loan.xlsx')
target=data['type']
data.drop('type',axis='columns',inplace=True)
train_data,test_data,train_target,test_target=cross_validation.train_test_split(data,target,test_size=0.4,train_size=0.6,random_state=12345)
clf_1=tree.DecisionTreeClassifier(criterion='entropy')
clf_1.fit(train_data,train_target)
train_est=clf_1.predict(train_data)
train_est_p=clf_1.predict_proba(train_data)[:,1]
将模型应用于测试集
test_est=clf_1.predict(test_data)
将模型适用于新样本的能力称为 泛化能力
我们希望一个模型的训练误差和泛化误差都很低,其中,泛化误差低是我们首要考虑的因素:
from sklearn import metrics
metrics.accuracy_score(test_target,test_est)
混淆矩阵:
metrics.confusion_matrix(test_target,test_est)
决策树算法易于理解,计算简单,能够处理有缺失属性的样本及不相关的特征,在短时间内可对较大的数据做出可行且效果良好的判断。存在问题:忽略数据之间的相关性,容易出现过拟合。
支持向量机
训练及预测
import sklearn.svm as svm
clf_2=svm.SVC()
clf_2.fit(train_data,train_target)
train_est=clf_2.predict(train_data)
test_est=clf_2.predict(test_data)
查看模型效果
from sklearn import metrics
metrics.accuracy_score(test_target,test_est)
metrics.confusion_matrix(test_target,test_est)
SUV算法具有较高的准确率,可解决高维问题,能够处理非线性特征的相互作用。但高维问题比较消耗内存,调参也有一定难度,对于非线性问题没有通用的解决方案,有时很难找到合适的核函数。
朴素贝叶斯分类器
from sklearn.naive_bayes import GaussianNB
clf_3=GaussianNB()
clf_3.fit(train_data,train_target)
train_est=clf_3.predict(train_data)
test_est=clf_3.predict(test_data)
from sklearn import metrics
metrics.accuracy_score(test_target,test_est)
metrics.confusion_matrix(test_target,test_est)
朴素贝叶斯算法有着坚实的数学基础及稳定的分类效率,常用于文本分类,在小规模数据上表现较好。存在缺点:需要计算先验概率,对数据的输入性比较敏感。
神经网络
from sklearn.neural_network import MLPClassifier
clf_4=MLPClassifier()
clf_4.fit(train_data,train_target)
train_est=clf_4.predict(train_data)
test_est=clf_4.predict(test_data)
from sklearn import metrics
metrics.accuracy_score(test_target,test_est)
metrics.confusion_matrix(test_target,test_est)
人工神经网络具有分类准确性高,可进行并行处理和分布式存储及学习能力强等众多优点,同时能充分逼近复杂的非线性网络。但学习时间过长,参数过多,输出结果难以解释。
模型评价方法-metric模块
#accuracy_score分类准确率
metrics.accuracy_score(y_true,y_pred)#返回正确分类的比例
metrics.accuracy_score(y_true,y_pred,normalize=False)#返回正确分类的样本数
#confusion_matrix混淆矩阵
metrics.confusion_matrix(y_true,y_pred)
#对角线表示被正确分类的样本数,其余位置均代表被错误分类的样本数
#roc_curve(ROC曲线)
metrics.roc_curve(y_true,y_score,pos_label=None)#y_score测试集属于正值样本的概率
#recall_score(召回率)
metrics.recall_score(y_true,y_pred)#提取正确的样本条数除以样本总信息条数
深度学习
卷积神经网络Convolutional neural networks,CNN
深度置信网络Deep Belief Bets,DBNs
[后续单独补充]
连接数据库
from sqlalchemy import create_engine
from sqlalchemy.ext.automap import automap_base
import pandas as pd
import numpy as np
engine=create_engine('mysql://root:[email protected]:3306/test?charset=utf8')
#root用户名 123密码 127.0.0.1:3306IP地址及端口号 test数据库名
#读取数据
pd.read_sql('select * from data',engine)#传入sql语句
pd.read_sql('data',engine)#直接传入表名
#存储数据
df=pd.DataFrame([[5,'apple',22],[6,'orange',23]],columns=['ID','name','price'],index=range(2))
df.to_sql('data',engine,index=False,if_exists='append')
#if_exists 'fail':原表存在不执行 'append':原表存在插入,不存在新建插入 'replace':原表存在清空重新插入
#to_sql十分便捷但有局限性,只针对DataFrame存储,不能应用于dict
df1=pd.DataFrame(np.arange(2000).reshape(1000,2),index=range(1000),columns=['key','value'])
r=df1.to_dict('records')
df1.to_sql('f_data',engine,index=False,if_exists='append')
pd.read_sql('f_data',engine).tail()
#使用SQLALchemy的方法,将数据实例化为SQLALchemy支持的类型
#ORM映射 Base.metadata.XXXX就是映射的类
Base=automap_base()
Base.prepare(engine,reflact=True)
f_data=Base.metadata.tables('f_data')
#再对实例化后的f_data执行insert,也能快速、批量的插入数据。
engine.execute(f_data.insert(),r)
pd.read_sql('f_data',engine).tail()
后面是量化数据获取和策略的知识,今天摸鱼还整不出来,下次继续。