【深度学习】经典算法解读及代码复现AlexNet-VGG-GoogLeNet-ResNet(二)
链接: 【深度学习】经典算法解读及代码复现AlexNet-VGG-GoogLeNet-ResNet(一)
4.GoogLeNet
4.1.网络模型
GoogLeNet的名字不是GoogleNet,而是GoogLeNet,这是为了致敬LeNet。GoogLeNet和AlexNet/VGGNet这类依靠加深网络结构的深度的思想不完全一样。GoogLeNet在加深度的同时做了结构上的创新,引入了一个叫做Inception的结构来代替之前的卷积加激活的经典组件。
GoogLeNet中的基础卷积块叫作Inception块,得名于同名电影《盗梦空间》(Inception)。Inception块在结构比较复杂,如下图所示:
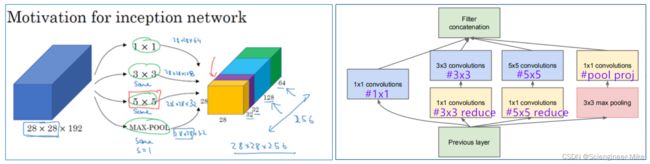
需要说明四点:
1 . 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合;
2 . 之所以卷积核大小采用1、3和5,主要是为了方便对齐。设定卷积步长stride=1之后,只要分别设定pad=0、1、2,那么卷积之后便可以得到相同维度的特征,然后这些特征就可以直接拼接在一起了;
3. 直接max pooling
4. 如果简单的将这些应用到feature map上的话,concat起来的feature map厚度将会很大,所以在googlenet中为了避免这一现象提出的inception具有如下结构,在3x3前,5x5前,max pooling后分别加上了1x1的卷积核起到了降低feature map厚度的作用,如下图所示。

了解完Inception后,我们看看GoogLeNet的整个结构,如下:
4.2.代码复现
代码如下:
# 导入相应的包
import tensorflow as tf
import numpy as np
import cv2
from tensorflow.keras.datasets import mnist
# 定义inception模块
# 定义Inception模块
class Inception(tf.keras.layers.Layer):
# 输入参数为各个卷积的卷积核个数
def __init__(self, c1, c2, c3, c4):
super(Inception,self).__init__()
# 线路1:1 x 1卷积层,激活函数是RELU,padding是same
self.p1_1 = tf.keras.layers.Conv2D(
c1, kernel_size=1, activation='relu', padding='same')
# 线路2,1 x 1卷积层后接3 x 3卷积层,激活函数是RELU,padding是same
self.p2_1 = tf.keras.layers.Conv2D(
c2[0], kernel_size=1, padding='same', activation='relu')
self.p2_2 = tf.keras.layers.Conv2D(c2[1], kernel_size=3, padding='same',
activation='relu')
# 线路3,1 x 1卷积层后接5 x 5卷积层,激活函数是RELU,padding是same
self.p3_1 = tf.keras.layers.Conv2D(
c3[0], kernel_size=1, padding='same', activation='relu')
self.p3_2 = tf.keras.layers.Conv2D(c3[1], kernel_size=5, padding='same',
activation='relu')
# 线路4,3 x 3最大池化层后接1 x 1卷积层,激活函数是RELU,padding是same
self.p4_1 = tf.keras.layers.MaxPool2D(
pool_size=3, padding='same', strides=1)
self.p4_2 = tf.keras.layers.Conv2D(
c4, kernel_size=1, padding='same', activation='relu')
# 完成前向传播过程
def call(self, x):
# 线路1
p1 = self.p1_1(x)
# 线路2
p2 = self.p2_2(self.p2_1(x))
# 线路3
p3 = self.p3_2(self.p3_1(x))
# 线路4
p4 = self.p4_2(self.p4_1(x))
# 在通道维上concat输出
outputs = tf.concat([p1, p2, p3, p4], axis=-1)
return outputs
搭建网络模型
# B1模块
# 第一模块使用一个64通道的7×7卷积层
# 定义模型的输入
inputs = tf.keras.Input(shape=(224,224,1),name = "input")
# b1 模块
# 卷积层7*7的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(64, kernel_size=7, strides=2, padding='same', activation='relu')(inputs)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
# b2 模块
# 第二模块使用2个卷积层:首先是64通道的1×1卷积层,然后是将通道增大3倍的3×3卷积层
# 卷积层1*1的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(64, kernel_size=1, padding='same', activation='relu')(x)
# 卷积层3*3的卷积核,步长为2,pad是same,激活函数RELU
x = tf.keras.layers.Conv2D(192, kernel_size=3, padding='same', activation='relu')(x)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
# B3模块
# 第三模块串联2个完整的Inception块。第一个Inception块的输出通道数为64+128+32+32=256。第二个Inception块输出通道数增至128+192+96+64=480
# Inception
x = Inception(64, (96, 128), (16, 32), 32)(x)
# Inception
x = Inception(128, (128, 192), (32, 96), 64)(x)
# 最大池化:窗口大小为3*3,步长为2,pad是same
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
# B4模块
# 第四模块更加复杂。它串联了5个Inception块,其输出通道数分别是192+208+48+64=512、160+224+64+64=512、128+256+64+64=512、
# 112+288+64+64=528和256+320+128+128=832
def aux_classifier(x, filter_size):
#x:输入数据,filter_size:卷积层卷积核个数,全连接层神经元个数
# 池化层
x = tf.keras.layers.AveragePooling2D(
pool_size=5, strides=3, padding='same')(x)
# 1x1 卷积层
x = tf.keras.layers.Conv2D(filters=filter_size[0], kernel_size=1, strides=1,
padding='valid', activation='relu')(x)
# 展平
x = tf.keras.layers.Flatten()(x)
# 全连接层1
x = tf.keras.layers.Dense(units=filter_size[1], activation='relu')(x)
# softmax输出层
x = tf.keras.layers.Dense(units=10, activation='softmax')(x)
return x
# b4 模块
# Inception
x = Inception(192, (96, 208), (16, 48), 64)(x)
# 辅助输出1
aux_output_1 = aux_classifier(x, [128, 1024])
# Inception
x = Inception(160, (112, 224), (24, 64), 64)(x)
# Inception
x = Inception(128, (128, 256), (24, 64), 64)(x)
# Inception
x = Inception(112, (144, 288), (32, 64), 64)(x)
# 辅助输出2
aux_output_2 = aux_classifier(x, [128, 1024])
# Inception
x = Inception(256, (160, 320), (32, 128), 128)(x)
# 最大池化
x = tf.keras.layers.MaxPool2D(pool_size=3, strides=2, padding='same')(x)
# B5模块
# 第五模块有输出通道数为256+320+128+128=832和384+384+128+128=1024的两个Inception块。后面紧跟输出层,
# 该模块使用全局平均池化层(GAP)来将每个通道的高和宽变成1。最后输出变成二维数组后接输出个数为标签类别数的全连接层
# b5 模块
# Inception
x = Inception(256, (160, 320), (32, 128), 128)(x)
# Inception
x = Inception(384, (192, 384), (48, 128), 128)(x)
# GAP
x = tf.keras.layers.GlobalAvgPool2D()(x)
# 输出层
main_outputs = tf.keras.layers.Dense(10,activation='softmax')(x)
# 使用Model来创建模型,指明输入和输出
model = tf.keras.Model(inputs=inputs, outputs=[main_outputs])
print(model.summary())
# 指定优化器,损失函数和评价指标
optimizer = tf.keras.optimizers.SGD(learning_rate=0.01, momentum=0.0)
model.compile(optimizer=optimizer,
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
数据预处理:将mnist数据转换为GoogLeNet需要的数据,由于笔记本电脑性能有限,挑选部分数据进行训练展示。代码如下:
# 获取手写数字数据集
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images_224 = []
test_images_224 = []
for i in train_images[:1000]:
train_images = cv2.resize(i,(224,224))
train_images_224.append(train_images)
new_train_image = np.expand_dims(np.array(train_images_224),axis=3)
for i in test_images[:200]:
test_images = cv2.resize(i,(224,224))
test_images_224.append(test_images)
new_test_image = np.expand_dims(np.array(test_images_224),axis=3)
print(new_train_image.shape,new_test_image.shape)
![]()
训练模型
# 模型训练:指定训练数据,batchsize,epoch,验证集
model.fit(new_train_image,train_labels[:1000],batch_size=128,epochs=3,verbose=1,validation_split=0.1)

验证模型
model.evaluate(new_test_image,test_labels[:200])
![]()
5.ResNet
5.1.网络模型
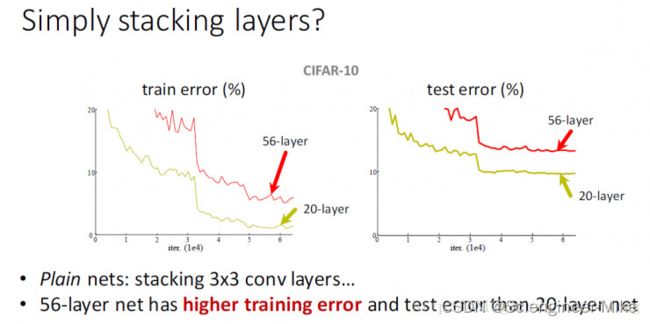
VGGNet和GoogLeNet都显示了网络有足够的深度是模型表现良好的前提,但是在网络达到一定深度之后,简单的网络堆叠反而效果变差了。ResNet指出,在许多的数据库上都显示出一个普遍的现象:增加网络深度到一定程度时,更深的网络意味着更高的训练误差。误差升高的原因是网络越深,梯度消失的现象就越明显,所以在后向传播的时候,无法有效的把梯度更新到前面的网络层,靠前的网络层参数无法更新,导致训练和测试效果变差。所以ResNet面临的问题是怎样在增加网络深度的情况下有可以有效解决梯度消失的问题。
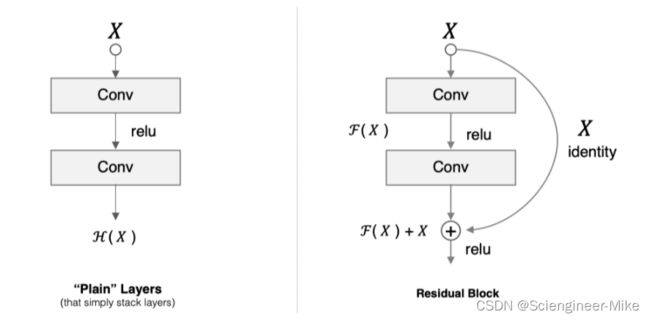
ResNet中解决深层网络梯度消失的问题的核心结构是残差网络。假设 F(x) 代表某个只包含有两层的映射函数, x 是输入, F(x)是输出。假设他们具有相同的维度。在训练的过程中我们希望能够通过修改网络中的 w和b去拟合一个理想的 H(x)(从输入到输出的一个理想的映射函数)。也就是我们的目标是修改F(x) 中的 w和b逼近 H(x) 。如果我们改变思路,用F(x) 来逼近 H(x)-x ,那么我们最终得到的输出就变为 F(x)+x(这里的加指的是对应位置上的元素相加,也就是element-wise addition),这里将直接从输入连接到输出的结构也称为shortcut,那整个结构就是残差块,ResNet的基础模块。
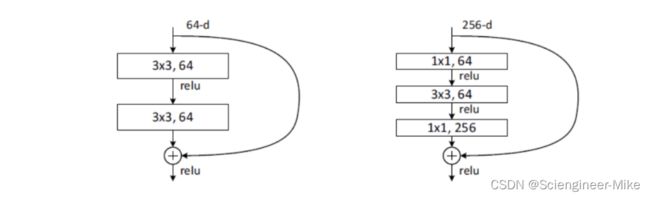
ResNet沿用了VGG全3×3卷积层的设计。残差块里首先有2个有相同输出通道数的3×3卷积层。每个卷积层后接BN层和ReLU激活函数,然后将输入直接加在最后的ReLU激活函数前,这种结构用于层数较少的神经网络中,比如ResNet34。若输入通道数比较多,就需要引入1×1卷积层来调整输入的通道数,这种结构也叫作瓶颈模块,通常用于网络层数较多的结构中。如下图所示:
5.2.代码复现
代码如下:
# 导入相关的工具包
import tensorflow as tf
from tensorflow.keras import layers, activations
# 定义ResNet的残差块
class Residual(tf.keras.Model):
# 指明残差块的通道数,是否使用1*1卷积,步长
def __init__(self, num_channels, use_1x1conv=False, strides=1):
super(Residual, self).__init__()
# 卷积层:指明卷积核个数,padding,卷积核大小,步长
self.conv1 = layers.Conv2D(num_channels,
padding='same',
kernel_size=3,
strides=strides)
# 卷积层:指明卷积核个数,padding,卷积核大小,步长
self.conv2 = layers.Conv2D(num_channels, kernel_size=3, padding='same')
if use_1x1conv:
self.conv3 = layers.Conv2D(num_channels,
kernel_size=1,
strides=strides)
else:
self.conv3 = None
# 指明BN层
self.bn1 = layers.BatchNormalization()
self.bn2 = layers.BatchNormalization()
# 定义前向传播过程
def call(self, X):
# 卷积,BN,激活
Y = activations.relu(self.bn1(self.conv1(X)))
# 卷积,BN
Y = self.bn2(self.conv2(Y))
# 对输入数据进行1*1卷积保证通道数相同
if self.conv3:
X = self.conv3(X)
# 返回与输入相加后激活的结果
return activations.relu(Y + X)
# ResNet网络中模块的构成
class ResnetBlock(tf.keras.layers.Layer):
# 网络层的定义:输出通道数(卷积核个数),模块中包含的残差块个数,是否为第一个模块
def __init__(self,num_channels, num_residuals, first_block=False):
super(ResnetBlock, self).__init__()
# 模块中的网络层
self.listLayers=[]
# 遍历模块中所有的层
for i in range(num_residuals):
# 若为第一个残差块并且不是第一个模块,则使用1*1卷积,步长为2(目的是减小特征图,并增大通道数)
if i == 0 and not first_block:
self.listLayers.append(Residual(num_channels, use_1x1conv=True, strides=2))
# 否则不使用1*1卷积,步长为1
else:
self.listLayers.append(Residual(num_channels))
# 定义前向传播过程
def call(self, X):
# 所有层依次向前传播即可
for layer in self.listLayers.layers:
X = layer(X)
return X
# ResNet的前两层跟之前介绍的GoogLeNet中的一样:在输出通道数为64、步幅为2的7×7卷积层后接步幅为2的3×3的最大池化层。
# 不同之处在于ResNet每个卷积层后增加了BN层,接着是所有残差模块,最后,与GoogLeNet一样,加入全局平均池化层(GAP)后接上全连接层输出。
# 构建ResNet网络
class ResNet(tf.keras.Model):
# 初始化:指定每个模块中的残差快的个数
def __init__(self,num_blocks):
super(ResNet, self).__init__()
# 输入层:7*7卷积,步长为2
self.conv=layers.Conv2D(64, kernel_size=7, strides=2, padding='same')
# BN层
self.bn=layers.BatchNormalization()
# 激活层
self.relu=layers.Activation('relu')
# 最大池化层
self.mp=layers.MaxPool2D(pool_size=3, strides=2, padding='same')
# 第一个block,通道数为64
self.resnet_block1=ResnetBlock(64,num_blocks[0], first_block=True)
# 第二个block,通道数为128
self.resnet_block2=ResnetBlock(128,num_blocks[1])
# 第三个block,通道数为256
self.resnet_block3=ResnetBlock(256,num_blocks[2])
# 第四个block,通道数为512
self.resnet_block4=ResnetBlock(512,num_blocks[3])
# 全局平均池化
self.gap=layers.GlobalAvgPool2D()
# 全连接层:分类
self.fc=layers.Dense(units=10,activation=tf.keras.activations.softmax)
# 前向传播过程
def call(self, x):
# 卷积
x=self.conv(x)
# BN
x=self.bn(x)
# 激活
x=self.relu(x)
# 最大池化
x=self.mp(x)
# 残差模块
x=self.resnet_block1(x)
x=self.resnet_block2(x)
x=self.resnet_block3(x)
x=self.resnet_block4(x)
# 全局平均池化
x=self.gap(x)
# 全链接层
x=self.fc(x)
return x
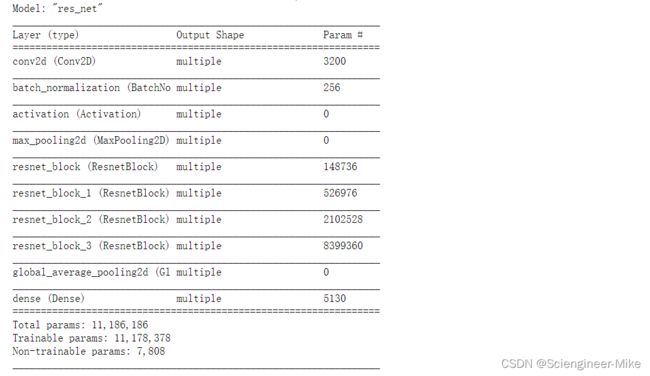
# 模型实例化:指定每个block中的残差块个数
mynet=ResNet([2,2,2,2])
X = tf.random.uniform(shape=(1, 224, 224 , 1))
y = mynet(X)
mynet.summary()
6.总结
到这里,我将经典的深度学习算法AlexNet,VGG,GoogLeNet,ResNet模型进行了原理介绍,以及使用pytorch和tensorflow完成代码的复现,希望对大家有所帮助。