使用超体素上下文和基于图的优化从MLS点云对城市地区的树木进行实例分割
Abstract
在本文中,开发了一种用于从城市场景中的 MLS 数据集中提取树木的实例分割方法。所提出的方法利用超体素结构来组织点云,然后从超体素的局部上下文中提取去除趋势的几何特征。结合局部上下文的去趋势特征,将采用随机森林(RF)分类器从点云中获得树木的初始语义标记结果。之后,迭代执行基于局部上下文的正则化以在全局图形模型上实现全局最优,以便在空间上平滑语义标记结果。最后,根据语义标记结果进行基于图的分割以分离个体树。超体素结构的使用可以保留场景中物体的几何边界,与基于点的解决方案相比,基于超体素的方法可以大大减少处理过程中的基本元素数量。此外,超体素上下文的引入可以提取对象的局部信息,使特征提取更具鲁棒性和代表性。去除趋势的几何特征可以克服局部上下文中冗余和不显着的信息,从而获得判别特征。受益于正则化过程,空间平滑是基于经典分类(如 RF 分类)的初始标记结果获得的。结果,在很大程度上消除了误分类错误,从而平滑了语义标记结果。基于在空间平滑过程中构建的全局图形模型,应用基于图形的分割来划分图形模型以对树实例进行聚类。在两个测试数据集上的实验都显示出可喜的结果,树木语义标记的准确率达到了 0.9 左右。使用基于图的算法对树木进行分割也显示出可接受的结果,具有简单结构和稀疏分布的树木正确分离,但对于那些具有复杂结构的狭窄树木,点被分割过度或分割不足。
Keywords—Instance segmentation; MLS; trees; urban areas; supervoxels; local context; graph-based segmentation
I. INTRODUCTION
树木在城市环境清单中起着至关重要的作用,提供了许多好处,例如节能、减少空气污染和释放热岛效应。因此,出于规划和管理目的,通常需要对城市树木进行调查。然而,与林区不同,城市地区的场景通常更为复杂,包括行人、车辆和建筑物等种类繁多的物体,这使得树木调查成为一项耗时耗力的工作。
为了找到解决这个问题的可能方法,光探测和测距 (LiDAR) 技术已被证明是一种有前途的解决方案。激光雷达有利于直接获取树冠和树干的三维几何信息(即三维位置和结构),可进一步用于树木数量统计和树种识别。然而,在城市地区,通过 LiDAR 获取的 3D 点云不仅是树木结构,还包括城市地区所有其他干扰树木调查的物体。因此,点云的语义解释通常是必要的。近年来,已经报道了大量关于点云语义解释的优秀研究[4][6][12],显示出在 3D 场景的语义标记方面的出色性能。然而,对于树木的调查,仅点的语义标记结果是不够的。我们需要的是每棵树的信息(即位置、大小和高度)。因此,基于语义标记结果进一步提供聚类或分割的实例分割正在成为一个热门话题,以获得带有语义标签的个体树。在图 1 中,我们提供了树实例分割的说明。
在这项工作中,开发了一种用于从城市场景中的 MLS 数据集中提取树木的实例分割方法。这项工作的具体贡献包括:1)一种新颖的几何特征提取方法,去除局部区域中冗余和不显着信息的趋势上下文,应用于树点分类,这对于从3D场景中提取局部几何特征是有效的; 2) 以基于超体素的局部上下文而非单个点作为基本元素,封装点的几何特征,为特征提取提供了灵活稳健的解决方案; 3)迭代执行基于局部上下文的空间平滑以在全局图上实现全局最优; 4) 基于具有超体素结构的全局图模型,应用基于图的分割算法从标记的点云中分割单棵树。分析了所提出方法的性能,显示出在测试数据集上的显着能力。

图 1 (a) 原始点云。 (b) 树的语义标注结果(绿色渲染)。 © 树的预期实例分割。
II. METHODOLOGY
所提出的方法利用超体素结构来组织点云,然后从超体素的局部上下文中提取去趋势几何特征。结合局部上下文的去趋势特征,将采用RF分类器来获得树的初始语义标记结果从点云。然后,迭代地执行基于局部上下文的正则化以在全局图模型上实现全局最优,以便在空间上平滑语义标记结果。最后,进行基于图的分割以根据语义标记分离个体树结果。超体素结构的使用可以保留场景中物体的几何边界,与基于点的解决方案相比,基于超体素的方法可以大大减少处理过程中的基本元素数量。此外,超体素上下文的引入可以提取对象的局部信息使特征提取更具鲁棒性和代表性,去趋势几何特征可以克服局部上下文中冗余和不显着的信息,从而获得判别特征。受益于正则化过程,空间平滑是基于经典分类(如 RF 分类)的初始标记结果获得的。结果,在很大程度上消除了误分类错误,从而平滑了语义标记结果。基于在空间平滑过程中构建的全局图模型,应用基于图的分割来划分图模型以聚类树实例。在图 2 中,我们提供了工作流程的草图,其中包含命名的算法和说明的中间结果。
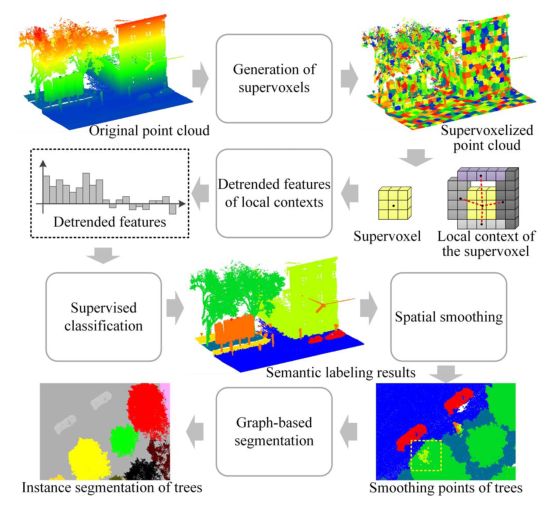
图 2. 目的方法的一般工作流程
与图像中的像素一样,体素是 3D 空间中组织和表示规则立方网格上的 3D 位置的基本单位。体素化是指点云,将点云转换为体素网格,并以一定的空间分辨率近似物体的几何形状。超体素是体素结构的进一步发展,根据几何同质性对体素进行聚类。体素云连接分割 (VCCS) 是最新的超体素方法之一,可生成 3D 点云的体积过分割。如 [8] 所述,VCCS 的超体素将比其他最先进的方法更好地遵守对象边界。同时,VCCS可以保持高效,也可以用于在线应用。具体来说,VCCS 结合了区域增长策略和局部 k 均值聚类,我们最终可以获得具有边界的过分割点块。在图 3 中,我们提供了车辆的超体素化点云的图示。很明显,车辆的边界是由过分割块的边缘发现的。

图 3. 车辆的超体素化点云
尽管超体素结构已经在较低层次上预先聚集了体素,但超体素倾向于将对象过度分割成碎片,这导致属于相同对象的不同块的特征之间存在差异。因此,决策树在后期的训练阶段可能没有得到很好的训练。为了解决这个问题,[11] 利用围绕单个超体素的一阶图并将该图概括为局部参考系 (LRF),这在汽车检测方面表现出了令人印象深刻的性能。然而,对于复杂的3D场景的解释,通常需要检测各种各样的物体,同时需要识别物体之间的准确边界。此外,根据[3]中进行的分析,对于局部描述符,即使对于同一类对象,生成的特征直方图中每个向量的贡献也是不同的。因此,对于两种不同类型的物体,生成的特征出现了模糊性。具体来说,自然地表和人造地表只是局部表面粗糙度不同,而几何特征等特征具有很高的相似性。 (例如,线性度、平面度和法向量)。因此,通过获得的特征直方图,需要一种增强派生特征向量的过程,使其具有更好的显着性并抑制平凡的特征向量。
为了实现有区别的特征,我们采用基于超体素的局部上下文的去趋势特征,如我们以前的工作[10]中所报告的。所获得的去趋势特征可以被视为一种基于残差的特征,它是局部上下文信息和其附近对象的显著性的结合。特征向量编码基于特征值的特征[1][12]、高度特征(即点高度的平均值和差值)[7]和空间特征(即法向向量)[9]。在图4中,给出了超体素的局部上下文的图示。

图 4. 基于超体素的局部上下文和单个超体素的连通性
在监督分类之后,可以获得给定数据集的语义标签。然而,由于在训练和分类过程中出现错误,有时很难对场景的解释结果充满信心。换句话说,分类结果仍然有问题,因为它被错误地标记,因此需要当前标记的正确性。此外,错误的标签也很明显可以通过其局部上下文进行修改。因此,为了保持建模分类器的当前精度并修复性能中的过度拟合错误,引入了空间平滑方法来解决该问题.空间平滑包括两个步骤。第一步是基于局部上下文的正则化,这将纠正可能由于训练期间的过度拟合问题或解释场景的复杂性而产生的不连续性或碎片标签。第二步是全局基于图的优化,其灵感来自 [4]。在这里,在全局范围内的图形模型上定义了正则化器 Ψ ( L ) \Psi(\mathrm{L}) Ψ(L),以指导平滑段边界的正则化过程。最后,一旦空间平滑完成,基于图的分割 [2] 将应用于优化的全局图的树木。这个全局图的节点代表超体素,它可能是树的潜在组成部分。一旦图被划分,每个子图中聚集的超体素的点最终将形成每棵树的点云。
III. EXPERIMENTS
A. Datasets
我们的测试区域位于慕尼黑工业大学 (TUM) 城市校区正门沿线的 Arcisstrasse,占地面积约为 29000 平方米,如图 5a 所示。 TUM 块的整个数据集(图 5b)最初由弗劳恩霍夫光电、系统技术和图像开发研究所(IOSB)[5] 获取。所使用的点云由两个以35° 在车辆的前车顶上。值得一提的是,Arcisstrasse 的场景是一个经典的复杂城市场景,包括数量众多且种类繁多的物体,将物体分为八个语义类别,即人造地形、自然地形、高植被、低植被、建筑物、硬景观、扫描工件和车辆。因此,它是在训练阶段学习分类器的理想选择。

图 5. (a) TUM 街区场景鸟瞰图。 (b) 用高度值渲染的整个 TUM 城市校园的 MLS 点云。
B. Preliminary results of semantic labeling
在图 6 中,给出了原始分类结果和树木的空间平滑结果(以绿色呈现)之间的比较。很明显,在空间平滑之后,不正确的分类超体素可以进一步修改并重新分配正确的标签(看到用黄色渲染的点错误标签被纠正为正确的树标签)。
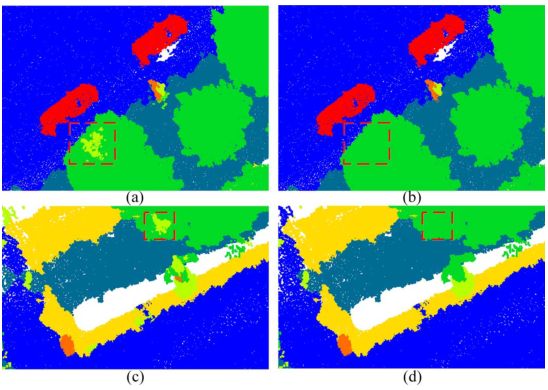
图 6. (a) 和 (b) 树的原始分类结果。 © 和 (d) 空间平滑后的分类结果。
在图 7 中,显示了整个 TUM 城市校园点云的语义标记结果。从图 7a 可以看出,获得了对实验场景的一般解释,例如人造地形和高延伸的高植被(树木)是公认的。此外,这种有目的的方法在定位静止汽车方面显示出极好的潜力。然而,由于如此大的场景的复杂性,存在诸如“闪光效应”之类的错误分类错误,其中建筑物立面内部的区域通常不完整且过于复杂而无法分类。因此,建筑物的一部分内部结构被错误地识别为其他物体,尤其是树冠。虽然部分零碎的错误标签被正则化了,但仍然存在标签错误的区域。另外值得注意的是,位于校园中心的区域,有一种被认为是自然地形和建筑物的倾向,而应该是大面积的人工地形。造成这种大面积错误分类的可能原因是:1)类人工地形主要由TUM校园周围的街道训练,街道和校园的地形表面被抽象为具有不同的上下文; 2)校园内部复杂性较高导致地形表面粗糙度增加。
C. Graph-based segmentation of trees
一旦树的点被分类,然后进行基于图的分割以实现个体树的分割。在图 8 中,我们提供了 TUM City 校园区域树木的实例分割结果。为了便于结果分析,我们将测试区域划分为两个区域,即 Area I 和 Area II。从图中可以看出,树的点被大致分割成单个树。然而,同样明显的是,当来自不同树的分支点具有大比例的重叠区域时,经常发生过分割和分割不足。尤其是区域II所示的结果,由于该区域树木茂密,交错的枝条点重叠,形成一个连续的面,局部几何变化不大,难以分割。相比之下,对于区域 I 中的点,由于该区域的树木分布与区域 II 中的树木分布相比更稀疏,因此大多数树木点都被正确地划分为单个树木。对于两个区域中的那些孤立的树,它们被完美地分割。

图 7. (a) TUM City 校园按类别着色的语义标记结果。(b) 树木(高植被)的分类点。
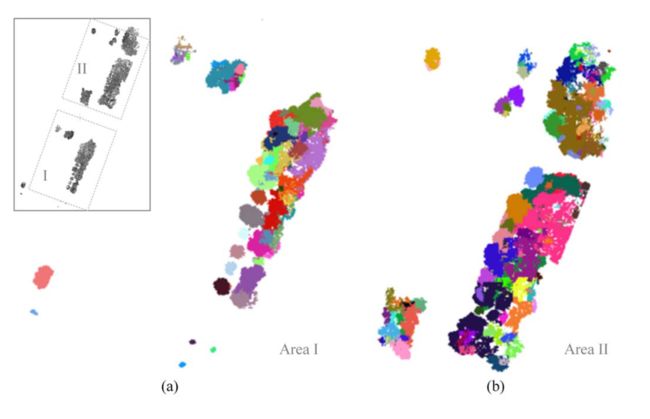
图 8.(a) I区树木实例分割。(b) II区树木实例分割。
此外,从方法论的角度来看,我们的分割方法的设计也存在一个缺点,它是一种基于聚类的分割算法。分割前段数未知。与需要选择种子的基于区域生长的分割方法相比,基于聚类的方法更容易产生过分割或欠分割结果。因此,为了提高分割质量,解决方案之一是提供有关冠或茎位置的先验知识,这可以在图优化过程中限制分割的数量。为了进一步测试基于图的分割方法的性能,我们使用了慕尼黑 Kronepark 的另一个 MLS 点云数据集,该数据集是由 Hochschule München 地理信息学系获得的。在图 8 中,我们展示了原始数据集和树木的分割结果。从图中可以看出,该数据集的点比TUM数据集更密集,树结构也比TUM数据集复杂得多,物种不同,遮挡较多。因此,在分割结果中,对于那些没有遮挡和重叠的树,它们可以很容易地分割成单个对象,但对于其他局促的树,点经常被过度分割和欠分割。

图 9. (a) Kronenpark 的原始 MLS 点云。 (b) 树木的提取点(用绿色渲染的植被)。 © 树的分割结果。保持规范的完整性。
IV. CONCLUSION
在本文中,我们开发了一种实例分割方法,用于从城市场景中的 MLS 数据集中提取树木。所提出的方法利用超体素结构来组织点云,然后从超体素的局部上下文中提取去除趋势的几何特征。结合局部上下文的去趋势特征,将采用随机森林(RF)分类器从点云中获得树木的初始语义标记结果。之后,迭代执行基于局部上下文的正则化以在全局图形模型上实现全局最优,以便在空间上平滑语义标记结果。最后,根据语义标记结果进行基于图的分割以分离个体树。超体素结构的使用可以保留场景中物体的几何边界,与基于点的解决方案相比,基于超体素的方法可以大大减少处理过程中的基本元素数量。此外,超体素上下文的引入可以提取对象的局部信息,使特征提取更具鲁棒性和代表性,去趋势几何特征可以克服局部上下文中冗余和不显着的信息,从而获得判别特征。受益于正则化过程,空间平滑是在经典分类(如 RF 分类)的初始标记结果的基础上获得的。结果,在很大程度上消除了误分类错误,从而平滑了语义标记结果。基于在空间平滑过程中构建的全局图模型,应用基于图的分割来划分图模型以聚类树实例。在两个测试数据集上的实验都显示出可喜的结果,树木语义标记的准确率达到了 0.9 左右。使用基于图的算法对树木进行分割也显示出可接受的结果,树木具有简单的结构和稀疏分布,可以正确分离。然而,对于那些结构复杂的局促树,点被过度分割或分割不足,这应该在我们未来的工作中得到改进。