论文阅读笔记:2020 CVPR Human Object Interactions (HOI) 论文 VSGNet
论文题目:VSGNet: Spatial Attention Network for Detecting Human Object Interactions Using Graph Convolutions
会议:2020 CVPR
机构:加州大学 圣巴巴拉分校 电子与计算机工程系
论文:https://arxiv.org/abs/2003.05541
代码:https://github.com/ASMIftekhar/VSGNet (pytorch)
human-object interactions (HOI) 检测任务:
对于每一个image,检测出 human 和 object 的 bounding box,以及他们之间的交互(interactions)标签;
每个human-object对可以有多个交互标签,每个场景可以有多个human和object。
作者思路
起源 - 简单的HOI办法:
1. 分别从 human 和 object 上提取特征并分析:忽略了context信息和 人-物对 的空间信息;
2. 用union boxes建模空间关系:没有对交互显式地建模
因此,作者提出多分支网络:
视觉分支Visual Branch:分别从人、物和周围环境中提取视觉特征;
空间注意分支Spatial Attention Branch:建模人-物对之间的空间关系;
图卷积分支Graph Convolutional Branch:将场景视为一个图,人与对象作为节点,并对结构交互(structural interactions)进行建模。
网络结构
1.Overview
模型输入:图像特征 F 和 人的bbox ![]() (1到H之间)和 物的bbox
(1到H之间)和 物的bbox ![]() (1到O之间),H和O分别是该场景中人和物的数量
(1到O之间),H和O分别是该场景中人和物的数量
模型目的:
1. 检测人h是否与物体o交互,并给出交互建议值![]()
2. 预测动作类别概率向量![]() ,其大小为类别数
,其大小为类别数
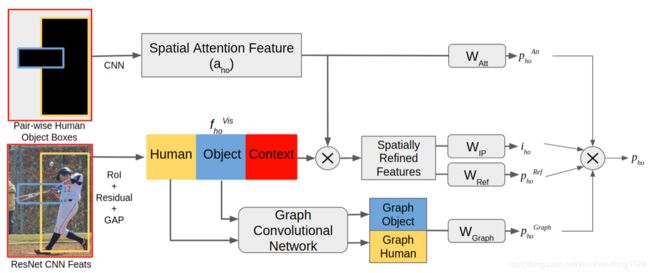 模型结构
模型结构
圆角矩形是运算,尖角矩形是特征提取,⊗是元素乘。
该模型由三个主要分支组成。
视觉分支提取人、对象和上下文特征。
空间注意分支通过利用人-物对的空间配置来细化视觉特征。
Graph Convolutional branch将人/对象看作节点,将人/对象之间的交互视为边缘,提取交互特征。
每个分支的动作类别概率和交互建议得分相乘,以汇总最终预测。
这些操作对每个人-对象对重复。
2. Visual Branch
人 和 物 的视觉特征提取:
使用人/对象区域上的region of interest(RoI)池来提取特征,再分别对其进行 Res残差块 和 全局平均池化(GAP) 操作,随后输出大小为R的视觉特征向量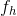 和
和 ![]()
context 的视觉特征提取:
context在HOI的检测中起着重要的作用。周围的物体,背景和其他的人可以帮助检测相互作用。
从整个输入图像中提取特征,然后通过剩余块和全局平均池,得到大小为R的context的视觉特征向量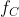
整合
将所有的视觉特征向量连接起来,并通过一个全连接层进行投影
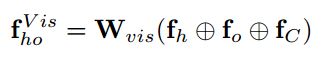
⊕ 是 concatenation operation![]() 是 the projection matrix
是 the projection matrix![]() 是 human-object对ho 的D维视觉特征向量
是 human-object对ho 的D维视觉特征向量
(![]() 直接用于动作分类,但在本文只是基础模型)
直接用于动作分类,但在本文只是基础模型)
3. Spatial Attention Branch
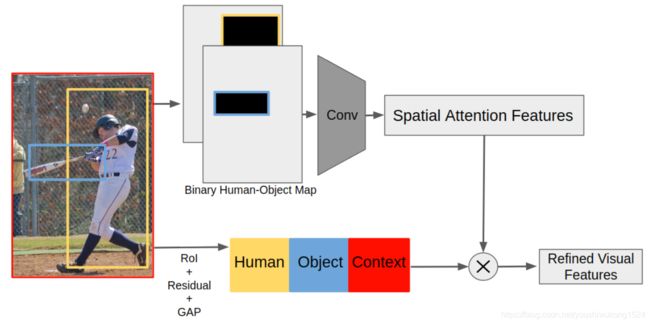
该分支主要任务:学习人与物体之间的空间交互模式,通过放大具有高空间相关性的对来细化视觉特征,生成注意特征。
 空间注意分支
空间注意分支
首先利用RoI池技术从图像中提取人、物体和背景的视觉特征。
利用人体和物体位置的二进制映射,卷积提取空间注意力特征。
这些注意力特征编码了人-物对的空间配置。
注意特征通过放大具有高空间相关性的对来细化视觉特征。
对于给定的 人的bbox ![]() 和 物的bbox
和 物的bbox ![]() ,生成两个二进制映射,这个二进制映射除了对应的人或物体的地方是1,其他都是0。 这将生成一个2通道的二进制空间配置映射(binary spatial configuration map)
,生成两个二进制映射,这个二进制映射除了对应的人或物体的地方是1,其他都是0。 这将生成一个2通道的二进制空间配置映射(binary spatial configuration map)![]() 。
。
用2层卷积分析二进制空间配置映射,然后GAP。
![]()
![]() 是 大小为D的注意特征向量(上面视觉特征大小也是D),表示人-对象对ho的空间配置
是 大小为D的注意特征向量(上面视觉特征大小也是D),表示人-对象对ho的空间配置
由于对象和人员是在不同的通道中定义的,因此在![]() 上使用了卷积来允许模型学习人与物体之间可能的空间关系。
上使用了卷积来允许模型学习人与物体之间可能的空间关系。
因为![]() 编码了空间配置,所以它可以直接用于分类HOIs。作者将此分类作为辅助预测,但主要使用
编码了空间配置,所以它可以直接用于分类HOIs。作者将此分类作为辅助预测,但主要使用![]() 作为细化视觉特征的注意力机制。
作为细化视觉特征的注意力机制。
辅助预测定义为:
![]()
![]() 是 大小为A的动作分类概率 ,σ 是sigmoid函数。
是 大小为A的动作分类概率 ,σ 是sigmoid函数。
将 ![]() 和
和 ![]() 两个向量元素乘,从而细化具有空间配置的视觉特征(
两个向量元素乘,从而细化具有空间配置的视觉特征(![]() 作为注意力函数)
作为注意力函数)

![]() 是 大小为D的 经过空间细化的 特征向量。
是 大小为D的 经过空间细化的 特征向量。
然后利用改进后的特征向量![]() 预测人-物对的交互建议得分
预测人-物对的交互建议得分![]() (大小1),预测动作类的概率
(大小1),预测动作类的概率![]() (大小A)。
(大小A)。
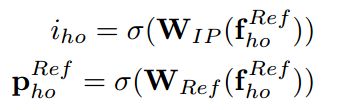
4. Graph Convolutional Interaction Branch
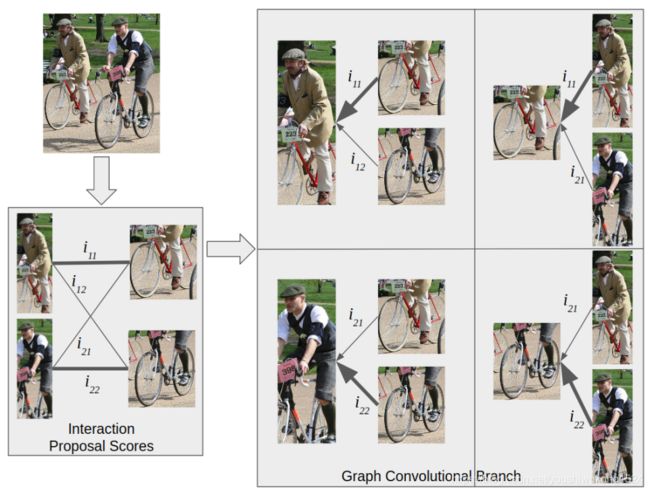
这个分支使用一个图卷积网络来为人和对象生成有效的特征。图卷积网络提取节点间结构关系的特征。这是通过使用 边 遍历和更新 图中的节点来实现的。在这种情况下,我们建议使用人和对象作为节点,他们的关系作为边缘。
我们没有一个完全连通的图,而是把每个人和每个对象连接起来,每个对象和每个人连接起来。然而,没有这种简化,所提出的模型也可以扩展到全连接。
 图卷积的分支
图卷积的分支
这个模型学习人与物体之间的结构联系。
对于这个任务,我们将人和对象定义为节点,并且只连接人-对象对之间的边。
我们不使用视觉相似度作为边缘邻接,而是使用交互建议评分。这使得边缘能够利用人-对象对之间的交互并生成更好的特性。
给定视觉特征 、 ![]() 以及人与物体之间的连接边,定义图形特征和'、
以及人与物体之间的连接边,定义图形特征和'、 ![]() '如下:
'如下:
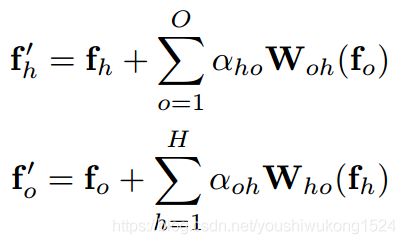
![]()
![]() 是 h 和 o 之间的邻接,
是 h 和 o 之间的邻接,![]() 是将对象特征映射到人类特征空间的函数。
是将对象特征映射到人类特征空间的函数。
文献[14,21]将邻接定义为视觉相似。但是,在本文中,邻接定义为视觉上不相似的事物(人和物)的节点之间的交互。
因此,h和o对 之间的邻接的值被定义为![]() ,
,![]() 是由空间细化的视觉特征生成的交互建议评分,用以衡量人-物对之间的交互作用。
是由空间细化的视觉特征生成的交互建议评分,用以衡量人-物对之间的交互作用。
将图的特征配对,动作分类预测(大小为A)计算为 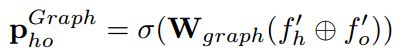
最后,通过与之前工作相似的概率相乘,我们将动作预测和交互建议得分结合起来。

![]() 是大小A的最终预测向量。
是大小A的最终预测向量。
试验
数据集:V-COCO 和 HICO-DET
度量:使用两种类型的平均精度(AP)度量来评估我们的性能:场景1和场景2
在这两个度量的AP计算过程中,对于人-对象对的预测被认为是正确的:
(1) 如果人和对象边界框的ground-truth框的IoU大于0.5,
并且(2) 对于人-对象对的预测的交互类标签是正确的。
对于没有对象(仅人为对象)的情况,在场景1中,如果对象对应的边界框是空的,并且在场景2中没有考虑对象的边界框,则预测是正确的。这使得场景1比场景2更加严酷。在HICO-DET中,我们的评估指标类似于场景1中的V-COCO.(好复杂,明天再看)