ShuffleNet V1——总结
版权声明:本文为博主原创文章,未经博主允许不得转载
论文:ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
链接:https://arxiv.org/abs/1707.01083
第三方代码:https://github.com/jaxony/ShuffleNet pytorch
2017CVPR的文章(旷世科技,Face++)
创新点:
稀疏连接是提高卷积运算效率的有效途径,当前不少优秀的卷积模型均沿用了这一思路。
The new architecture utilizes two new operations, pointwise group convolution and channel shuffle, to greatly reduce computation cost while maintaining accuracy.
We notice that state-of-the-art basic architectures such as Xception [3] and ResNeXt [40] become less efficient in extremely small networks because of the costly dense 1 * 1convolutions.
In tiny networks, expensive pointwise convolutions result in limited number of channels to meet the complexity
To overcome the side effects brought by group convolutions,we come up with a novel channel shuffle operation to help the information flowing across feature channels.
作者指出1*1卷积在小型网络中成为了瓶颈,占据了大量的计算量,于是提出了 pointwise group convolution来减少计算量,但是带来了副作用,也就是信息隔离了,不同组之间的信息无法交流,接着就提出channel shuffle来使得信息在通道中流通。
论文详解:
Xception [3] and ResNeXt [40] introduce efficient depthwise separable convolutions or group convolutions
into the building blocks to strike an excellent trade-off between representation capability and computational cost
In tiny networks, expensive pointwise convolutions result in limited number of channels to meet the complexity constraint, which might significantly damage the accuracy.
To address the issue, a straightforward solution is to apply channel sparse connections, for example group convolutions,also on 1*1 layers.
However, if multiple group convolutions stack together, there is one side effect: outputs from a certain channel are only derived from a small fraction of input channels.
This property blocks information flow between channel groups and weakens representation.
作者在文中提到Xception和ResNeXt已经以depthwise separable convolutions or group convolutions在表示能力和计算成本之间取得了很好的平衡,但是分析之后,认为1*1卷积成为了小型网络性能的瓶颈,为了解决这个问题,一个直接的想法就是通道稀疏链接,比如1*1卷积也进行分组,但是,这样就会带来one side effect,输出仅仅来自输入channel的一小部分,隔离了不同group之间的交流,学出来的特征也会非常局限,接着又引入了channel shuffle,对每组输出的feature map进行重排,使得GConv2的每一个group都能卷积输入的所有feature map。
如下图所示:图a只有group convolution堆叠在一起,输出只由特定的一部分输入决定,b和c都对第一次卷积后的结果进行了重排,输出由所有的输入决定。

接着作者谈到到ShuffleNet Unit,如下图所示:
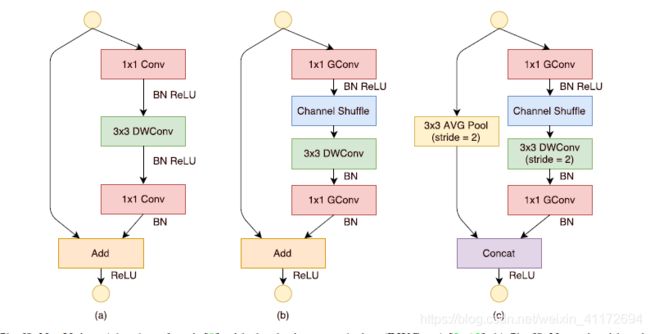
Fig (a):ResNet 中的bottleneck unit,只不过把3*3 Conv改成了 3*3DWConv
Fig (b): ShuffleNet结构,首先Group的1*1 Conv替代了原来的1*1卷积,同时跟channel shuffle,然后是3*3DWConv,没有Relu操作,最后经过Group 1*1Conv。
Fig (c): ShuffleNet降维结构,作者做了2处改动,shoutcut path处增加了3*3 avg Pool ;concat替代了add操作,在少量计算下扩大了通道。
基本单元堆叠,ShuffleNet结构如下图所示:

complexity计算:c*h*w
Shuffle: GConv1:g*(1*1*c/g*h*w*m/g) DWConv :3*3*h*w*m GConv2:g*(1*1*m/g*h*w*c/g) =h*w*(9m+2cm/g)
ResNeXt: 1*1Conv:1*1*c*h*w*m 3*3 group Conv :g*(3*3*m/g*h*w*m/g) 1*1Conv:1*1*m*h*w*c =h*w(2cm+9m*m/g)
ResNeXt complexity 大于Shuffle,换句话说,在有限的计算下,ShuffleNet可以用更宽的feature map。
上图在限定complexity下,通过改变group来改变输出通道数,一般来说,更多的通道数能提取更多的特征,虽然可能会导致单个filter性能下架(由于相应的输入通道有限,每个filter卷积的输入通道数下降)
类似MobileNet,通过超参数控制每一层的通道数,如下图所示,

”ShuffleNet sx” means scaling the number of filters in ShuffleNet 1x by s times thus overall complexity will be roughly s2 times of ShuffleNet 1x.

作者指出更小的模型更受益于group Conv,在限定的计算下,group Conv允许更宽的feature map,小的网络本身feature map thinner,更受益于大的feature maps。作者还指出0.5x,当g=8时,分类得分达到饱和甚至下降。随着g的增加,输入通道对于每个conv filter变少了,可能会损害到表示能力。
最后作者做了很多实验:

Tab3表明了shuffle的重要性。

Tab4几个流行网络的对比。

Tab5 ShuffleNet和MobileNet的对比。
shallow:裁剪掉了stage2-4的部分blocks,也就是降低了深度,不过在相同深度下,ShuffleNet比MobileNet误差更低,表明ShuffleNet 主要源于高效的structure,而不是depth。

Tab7 泛化能力的比较。
参考:https://blog.csdn.net/weixin_41172694/article/details/84989276