Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval (CVPR 2020 Oral)
Author :Horizon Max
✨ 编程技巧篇:各种操作小结
神经网络篇:经典网络模型
Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
- Abstract
-
- Contributions
- Introduction
-
- Related Works
-
- Category-level SBIR
- Fine-grained SBIR
- Partial Sketch
- Reinforcement Learning in Vision
- Methodology
-
- Base Models
- On-The-Fly FG-SBIR
- Experiments
-
- Datasets
- Implementation Details
- Evaluation Metric
- Baseline Methods
- Code
Abstract
Fine-grained sketch-based image retrieval (FG-SBIR) :基于细粒度草图的图像检索 ;
作者重新制定了传统的 FG-SBIR 框架来解决现有的两个挑战:草图绘制需要大量的时间,大多数人很难画出一副完整和真实的草图 ;
最终目标:用尽可能少的笔画数检索目标图像 ;
作者提出了一个动态的设计(on-the-fly design):
- 设计了一个基于强化学习的跨模态检索框架从用户一开始绘图就开始检索 ;
- 引入了一个新颖的奖励机制,避免了与素描无关的问题 ;

Publication :CVPR 2020 [Oral Presentation]
Paper :Sketch Less for More: On-the-Fly Fine-Grained Sketch Based Image Retrieval
GIthub :On-the-Fly-FGSBIR
Contributions
- 引入了一种新颖的动态 FG-SBIR 框架,使用强化学习训练来检索不完整草图照片 ;
- 开发了一种基于 Kendall-Tau rank distance 的奖励机制,考虑了草图的完整性和相关的不确定性 ;
- 在两个公共数据集上(QMUL-Shoe-V2 & QMUL-Chair-V2)证明了该框架的优越性 ;

Introduction
基于草图的图像检索(sketch based image retreival, SBIR)由于其潜在的商业应用而受到了特别的关注 ;
草图检索相比于文本/标记检索有着关键的优势:可以传递细粒度的细节 ;
ps:
- fine-grained :细粒度,类别内分类任务;
- coarse-grained :粗粒度,类别间分类任务 ;
FG-SBIR 任务仍存在着两个障碍阻碍了实践中的广泛应用:
- 绘制完整草图所需的时间 ;
- 用户绘图技能的缺乏 ;
从 “less is more” 的角度来打破这些障碍,旨在实现较少的笔画就能检索目标图片:

传统的方案:
- 直接将不完整草图输入现有的 FG-SBIR 框架当中 ;
- 训练数据中包含合成草图 ;
即,大多采用三元组排名框架 (triplet ranking framework):
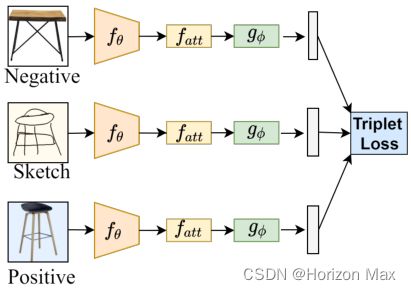
每个三元组都被视为一个独立的训练样本,由于草图的高度抽象性,最初的草图笔画可能对应着多张可能的图像,这极易给模型带来一个噪声梯度 ;
而且没有特定的机制可以指导现有的 FG-SBIR 模型以最小的笔画来检索图像,使得其在动态检索过程中表现性能较差 ;
Related Works
Category-level SBIR
当前研究方向可以分为以下三类:
- traditional SBIR :对象类别在训练和测试中非常常见 ;
- zero-shot SBIR :提升模型在不相关的训练和测试类别间的泛化能力以减少注释成本 ;
- sketch-image hashing :通过嵌入二进制哈希码代替连续向量来提高检索的计算成本 ;
Fine-grained SBIR
提出了三元组损失 ;
Partial Sketch
流行于图像修复领域 ;
Reinforcement Learning in Vision
通过权衡草图的可识别性和笔画数量来学习抽象和总结,即通过使用 RL 从给定的完整笔画中过滤掉不必要的笔画 ;
Methodology
- 通过预训练的 FG-SBIR 模型得到 embedding 函数 F(.):I → RD ,实现将栅格化草图或图像 I 映射到 D维特征 ;
- 给定一个包含M张图像的图库 G = { Xi } i = 1 M ^M_{i=1} i=1M ;
- 由函数 F(.) 得到一个 D维向量的列表: G ^ \widehat{G} G = { F(Xi) } i = 1 M ^M_{i=1} i=1M ;
- 给定查询草图 S 和一些成对的距离度量,可以从 G 中得到检索到的 top-q 图像:Retq(F(S), G ^ \widehat{G} G ) ;
- 若真实图像出现在 top-q 当中则认为检索精度为 ture ;
- 由于设计的是动态检索,所以草图可以表示为:S ∈ { p1, p2, p3, … , pN } ,pi表示一个草图坐标元组 (x, y) ;
- 设草图绘制操作为 ∅ ,由 S 中前 K 个坐标得到的列表 SK 生成一张栅格化草图 ;
- 目标:K 最小时,真实图像出现在 Retq(F( ∅(SK)), G ^ \widehat{G} G ) 当中 ;
Base Models
由三个特定的模块组成:
- fθ :由预训练的 Inception V3 权重进行初始化 ;
- fatt :1×1 convolution + softmax ;
- g∅ :经过 l2 归一化后的最终全连接层,输出大小为 D ;
给定特征图 B = fθ(I) ,注意力模块输出为 Batt = B + B · fatt(B) ;
训练数据包括:Sketch、Positive、Negative ;
使用三元损失以减小草图与正样本之间的距离,并增大草图与负样本之间的距离;
- β+ = || F(a) - F( p) ||2
- β- = || F(a) - F(n) ||2
- 三元损失:max{ 0, μ + β+ - β- }
On-The-Fly FG-SBIR
- Basic Element :Agent、Environment、Goal ;
- Main Element :State、Action、Reward ;
- Core Element :Policy、Value ;
- agent
action:by producing a feature vector representation of the sketch at each rendering step ;reward:by retrieving the paired photo early ;
action_mean, sketch_anchor_embedding, log_prob, entropy =
SBIR_Environment.policy_network.select_action(sampled_batch[i_sketch].unsqueeze(0).to(opt.device))
reward = SBIR_Environment.get_reward(sketch_anchor_embedding, SBIR_Environment.Sketch_Name_Train[niter])
entropies.append(entropy)
log_probs.append(log_prob)
rewards.append(reward)
distance:
target_distance = F.pairwise_distance(F.normalize(sketch_feature),
self.Image_Array_Test[position_query].unsqueeze(0))
distance = F.pairwise_distance(F.normalize(sketch_feature),
self.Image_Array_Test)
rank_all[i_batch, i_sketch] = distance.le(target_distance).sum()
为减小计算开销,将草图栅格化 T 次来代替每一个坐标时刻渲染一个新的草图,即间隔步长为:[ N T \frac {N} {T} TN] ;
在保证照片分支不变的情况下,使用 baseline model 得到 G ^ \widehat{G} G ;
对草图分支进行微调的情况下,训练 agent (sketch branch) 来处理部分草图,使其能胜任处理部分草图 ;
假设一个草图渲染集为:S = { p1, p2, p3, … , pT } ,agent 每个时间 t 步骤内都将 st = ∅ (pt) 作为输入,并输出一个连续的动作向量 at ;
考虑 at 和 G ^ \widehat{G} G 之间的成对距离,检索环境 (environment) 返回一个奖励 (reward) : rt ;
RL模型的目的是在一个完整的草图绘制情景下 (environment) ,为 agent 找到最优策略 (Policy),使总奖励 (Reward) 最大化 ;
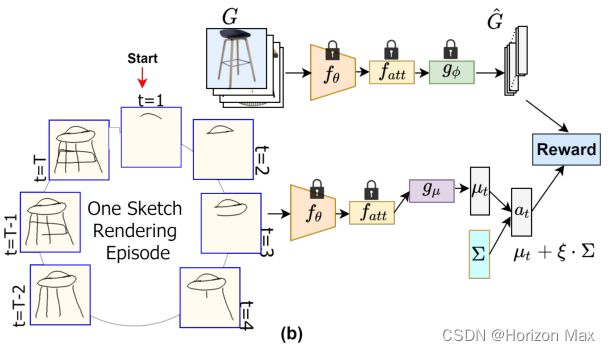
RL : ΠΘ(a | s)
- Θ :封装了预训练的 fθ 和 fatt 网络参数并保持固定 ;
- gμ :一个可训练的全连接层,用于预测多元高斯分布的平均向量 μ ;
在每个时间 t 步骤内,得到一个策略 (Policy) 分布 ΠΘ(at | st) ,此后从这个分布中采样一个动作作为草图的 D维特征表示;
即:at ~ ΠΘ( · | st)
Local Reward :
目标:使 配对图像(草图与对应图像)在得到的 rank list 最小 ;
Local Reward: R t L o c a l ^{Local}_{t} tLocal = 1 r a n k t \frac {1} {rank~t~} rank t 1
Global Reward :
使用 Kendall-Tau-distance 来测量 Lt 和 Lt+1 两个 rank list 之间的距离,以模拟草图绘制过程中草图与对应图像映射迈进的过程 ;
Kendall-Tau-distance 值会随着草图绘制过程不断减小 ;
Global Reward: R t G l o b a l ^{Global}_{t} tGlobal = -max(0, τ(Lt, Lt+1) - τ(Lt-1, Lt))
Training Procedure :
Rewards: Rt = γ1 · R t L o c a l ^{Local}_{t} tLocal + γ2 · R t G l o b a l ^{Global}_{t} tGlobal
Experiments
Datasets
- QMUL-Shoe-V2 :6051/679 sketches + 1800/200 photos for training/testing ;
- QMUL-Chair-V2 :1275/725 sketches + 300/100 photos for training/testing ;
Implementation Details
- PyTorch + Nvidia RTX 2080-Ti GPU ;
- ImageNet 数据集预训练 Inception-V3 (不包括辅助分支)网络被用作草图和照片分支的骨干网络 ;
- Adam optimizer ;
- D = 64 ;
- T = 20 ;
- batch_size = 16 ;
- learning_rate = 0.001 ,100 epoch → 0.0001;
- γ1 = 1 , γ2 = 1e-4 ;
Evaluation Metric
- ranking percentile:排名百分比 ;
- 1 r a n k \frac {1} {rank} rank1 versus percentage of sketch : 1 r a n k \frac {1} {rank} rank1 ;
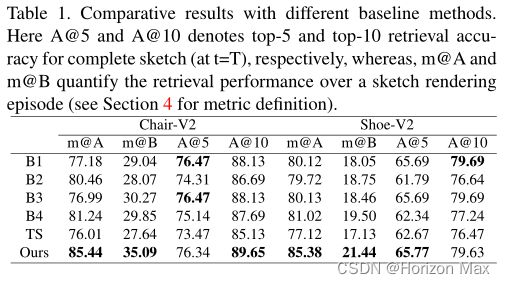
Baseline Methods
- B1 :仅训练三元损失的基线模型(基于RL微调之前的模型);
- B2:训练草图中包含了绘图过程中的草图 ;
- B3:为每一个草图分支训练了一个模型(T=20时共20个不同的模型);
- B4:Engilberge等人设计的类似跨模态检索的设置 ;

Code