线程/协程/异步的编程模型(CPU利用率为核心)
最近看了一个b站博主的视频https://www.bilibili.com/video/av64066246/讲到了线程/协程/异步的编程模型,这里做下记录
1.线程
上篇文章有聊到进程和线程的关系,但是没有涉及到更低层的原理,这里刚好可以将其补充上
我们知道进程是组织资源的最小单位,而线程是安排CPU执行的最小单位。引进线程是为了更好地共享资源。我们也知道在多线程编程模型中,由于cpu是分时复用的,所以线程上下文会涉及到很多次在用户态和内核态的上下文切换。操作系统为了保护自己严格控制用户程序的资源访问,需要调用外部资源的时候,往往需要让操作系统去进行调用(也就是我们常说的系统调用),不需要外部资源的程序运行状态是用户态,反之需要内核帮忙操作资源此时就是内核态。
但是很多人在学习线程的时候都会有这样的疑问?
为什么cpu需要分时,去频繁切换时间片执行线程?
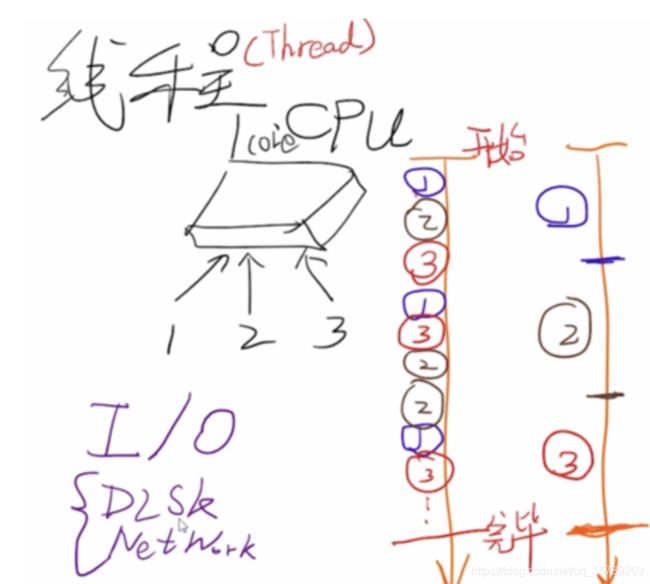
单核CPU,有3个要执行的线程,先执行线程1,让出时间片,再执行线程2,让出时间片,再执行线程3,直至所有线程执行完毕;
左右两边的区别在于:右边不对CPU进行时间分片,右边只执行了两次线程的上下文切换 ,两侧执行的总时间是一样的。
疑问:明明右边的执行效率更高(只进行了两次上下文切换)?多线程存在的意义?
意义:I/O:包括DiskIO(耗时)和NetworkIO
在读取文件的过程中,CPU并不直接读取硬盘,而是对DMA(DMA全称直接内存访问控制器)下达指令,让DMA完成文件的读取。
步骤:
(1)CPU向DMA下达指令,指令中含有磁盘设备信息和需要读取的文件位置;
(2)DMA告知硬盘进行文件的读取,文件读取会将硬盘中的内容加载到内存中;
(3)硬盘读取完毕后,硬盘会给DMA一个反馈;
(4)DMA最终以中断的形式通知CPU:文件读取完成
(5)最后,CPU从内存中去读取变量的值,即拿到了文件的内容

CPU在(1)状态后,就处于闲置的状态,CPU可以去执行其他的线程
假设这3个线程都是需要读取文件,看最右边的紫色线,CPU先让1号线程执行,1号线程执行:让DMA进行读取,此时CPU让出资源交给其他的线程,接着线程2拿到CPU的控制权,他通知DMA去进行文件的读取,接着线程3也是一样操作。。。。
此时CPU的等待时间X可以让给其他线程。
文件读取完成后,三个DMA以中断的方式形式通知CPU,他们的时间点分别为y1,y2,y3,接着线程1又拿到CPU资源,又可以接着进行操作
意义的总结:X这块的执行权(就是DMA的执行的过程中),这块的CPU不是阻塞的,CPU可以交给其他的线程,其次,CPU总线是可以复用的,DMA可以充分的利用这些总线,通过这两点可以提高CPU的利用率
缺点:线程是OS底层的api,线程开辟浪费时间,运行线程也会造成线程上下文的切换,用户态和内核态的转换,浪费CPU切换的时间
2.协程
- 编程语言级别的线程,可以像使用线程一样使用协程,但是在OS底层,他并不是线程;
- 协程全程处于用户态,可以大量开辟,更轻量,接近1K,不用考虑用户态和内核态的转化;,开辟上千个线程是极限,go语言开辟协程的数量可以达到千万级别
在传统的J2EE系统中都是基于每个请求占用一个线程去完成完整的业务逻辑(包括事务)。所以系统的吞吐能力取决于每个线程的操作耗时。如果遇到很耗时的I/O行为,则整个系统的吞吐立刻下降,因为这个时候线程一直处于阻塞状态,如果线程很多的时候,会存在很多线程处于空闲状态(等待该线程执行完才能执行),造成了资源应用不彻底。
最常见的例子就是JDBC(它是同步阻塞的),这也是为什么很多人都说数据库是瓶颈的原因。这里的耗时其实是让CPU一直在等待I/O返回,说白了线程根本没有利用CPU去做运算,而是处于空转状态。而另外过多的线程,也会带来更多的ContextSwitch开销。
对于上述问题,现阶段行业里的比较流行的解决方案之一就是单线程加上异步回调这个我们在第三点会谈到。其代表派是node.js以及Java里的新秀Vert.x。
而协程的目的就是当出现长时间的I/O操作时,通过让出目前的协程调度,执行下一个任务的方式,来消除ContextSwitch上的开销。
协程的特点:
- 线程的切换由操作系统负责调度,协程由用户自己进行调度,因此减少了上下文切换,提高了效率。
- 线程的默认Stack大小是1M,而协程更轻量,接近1K。因此可以在相同的内存中开启更多的协程。
- 由于在同一个线程上,因此可以避免竞争关系而使用锁。
- 适用于被阻塞的,且需要大量并发的场景。但不适用于大量计算的多线程,遇到此种情况,更好实用线程去解决。
而与IO多路复用结合起来,特别是高度服务化的今天,http请求会产生很多socket io操作,tcp包是分段的,一个socket可读了,然后可能只读到了半条请求,需要进行频繁的保存和恢复线程。
所以很适合用协程来调度。具体可以看这篇文章说的真的很好:
https://blog.csdn.net/weixin_39717110/article/details/110722214?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_title-0&spm=1001.2101.3001.4242
协程的原理
当出现IO阻塞的时候,由协程的调度器进行调度,通过将数据流立刻yield掉(主动让出),并且记录当前栈上的数据,阻塞完后立刻再通过线程恢复栈,并把阻塞的结果放到这个线程上去跑,这样看上去好像跟写同步代码没有任何差别,这整个流程可以称为coroutine,而跑在由coroutine负责调度的线程称为Fiber。比如Golang里的 go关键字其实就是负责开启一个Fiber,让func逻辑跑在上面。
由于协程的暂停完全由程序控制,发生在用户态上;而线程的阻塞状态是由操作系统内核来进行切换,发生在内核态上。
因此,协程的开销远远小于线程的开销,也就没有了ContextSwitch上的开销。
比较线程协程:
1、占用资源初始单位为1MB,固定不可变初始一般为 2KB,可随需要而增大调度所属由 OS 的内核完成由用户完成。
2、切换开销涉及模式切换(从用户态切换到内核态)、16个寄存器、PC、SP...等寄存器的刷新等只有三个寄存器的值修改 - PC / SP / DX.性能问题资源占用太高,频繁创建销毁会带来严重的性能问题资源占用小,不会带来严重的性能问题。
3、数据同步需要用锁等机制确保数据的一直性和可见性不需要多线程的锁机制,因为只有一个线程,也不存在同时写变量冲突,在协程中控制共享资源不加锁,只需要判断状态就好了,所以执行效率比多线程高很多。比如在java中,每个线程都会从内存中拷贝自己的栈,然后在线程完成后回写到内存中,所以高并发的时候我们经常为线程加上锁,这个锁很多时候浪费了,而协程由于在一个线程中,所以根本不会有这个问题。
3.异步
在1中的(4)DMA最终以中断的形式通知CPU:文件读取完成就是异步操作,Node.js是单线程的,却可以应对高并发,就是因为他是异步的。在Node.js中有大量的回调函数的产生,大量的异步操作eg:在单线程的执行过程中,出现了IO读写,就会交给DMA去进行文件的读写,单线程继续工作,最终在触发的时候,会触发一个回调函数,获取到一个文件的数据
总结:所有的这些方法模型都是基于一个目的,cpu-》内存-〉磁盘速度差距太大,cpu会空出很多空闲时间,所以需要这样来提高cpu的利用率。但是同时也提高了我们写程序的复杂度。