遥感和随机森林核心思想python
背景
- 前几天遇到我的一个大哥,让我帮他做遥感的机器学习。
- 之前没做过,都不太懂,后来在这个大哥的指导下,大概了解了一点点皮毛。
- 所谓的遥感机器学习其实主要做的是:遥感数据处理。也就是把遥感数据处理成面板数据之后,就可以使用机器学习模型了。
- 这篇文章还不涉及交叉验证、调参等细节。如果后面有需要,会继续介绍。
数据与代码
- 数据和代码全都免费共享,我觉得这种东西本来就是免费的,共享给大家。虽然代码是我写的,但是我也是使用别人的包,站在巨人的肩膀上,有什么理由不公开呢。
- 数据在公众号【统计学人】上,关注并且回复【气象数据】,里面有一个【data20220907】文件夹就是。
- 代码已经上传到我的GitHub里面,链接为:https://github.com/yuanzhoulvpi2017/tiny_python/tree/main/python_GIS,里面的【09开头的部分】
思路与代码讲解
要注意,我们的思路是这样的:
- 处理gis数据,获得每个样本点对于的波段的数据,获得每个样本点对应的类别。
- 将每个样本点的波段数据、类别整理成面板数据。
- 把每个样本点的波段数据看作X,类别看作Y。
- 训练一个模型,这里使用随机森林。
- 查看模型效果。
- 模型预测所有的波段数据,生产类别。
- 可视化。
气象数据格式多种多样,但是你只要保证能把数据提取出样本数据,那就是抓住了问题的本质。
step 1
## 安装要求
1. rasterio: `pip install rasterio`
2. ipympl: `pip install ipympl`
3. 别的包就非常常见了,只要是使用anaconda的都有
# 导入包
import geopandas as gpd
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import rasterio
import seaborn as sns
from matplotlib import cm
# 可视化引擎后端
%matplotlib widget
step 2 & 3
# 加载数据
dataset_list = [rasterio.open(
f'数据集/data20220907/band/band{i}.tif') for i in range(1, 12) if i != 8]
dataset_list
#可视化
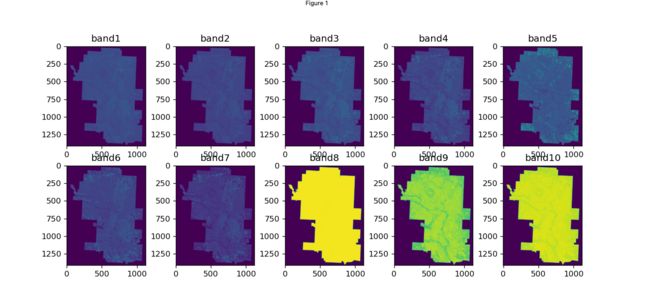
fig, ax = plt.subplots(ncols=5, nrows=2, figsize=(12, 5), dpi=120)
ax = ax.flatten()
for index in range(len(dataset_list)):
ax[index].imshow(dataset_list[index].read()[0, :, :])
ax[index].set_title(f"band{index+1}")
calgary_trainingpointer_gpd = gpd.read_file(
"数据集/data20220907/calgary_trainingPointers")
# calgary_trainingpointer_gpd = calgary_trainingpointer_gpd.to_crs(dataset_list[0].crs.to_string())
calgary_trainingpointer_gpd
# class id geometry
# 0 clouds 1.0 POINT (-114.24357 51.12257)
# 1 clouds 1.0 POINT (-114.21657 51.12176)
# 2 clouds 1.0 POINT (-114.21073 51.12747)
# 3 clouds 1.0 POINT (-114.20116 51.12273)
# 4 clouds 1.0 POINT (-114.20370 51.12623)
# .. ... ... ...
# 696 water 4.0 POINT (-113.98607 50.86494)
# 697 water 4.0 POINT (-113.97288 50.85150)
# 698 water 4.0 POINT (-113.97410 50.85180)
# 699 water 4.0 POINT (-113.97348 50.85231)
# 700 water 4.0 POINT (-113.97307 50.85155)
#
# [701 rows x 3 columns]
cityboundary_gpd = gpd.read_file("数据集/data20220907/CityBoundary.geojson")
# cityboundary_gpd = cityboundary_gpd.to_crs(dataset_list[0].crs.to_string())
cityboundary_gpd
# city geometry
# 0 CALGARY POLYGON ((-114.01329 51.21243, -114.01328 51.2...
hydrology_gpd = gpd.read_file("数据集/data20220907/Hydrology.geojson")
print(hydrology_gpd)
# perimeter lake_source feature_type lake_name modified_dt \
# 0 246282.03805549 None water course BOW RIVER 2016-04-28
# 1 560.10253111 None lake None 2016-04-28
# 2 668.64838361 None lake None 2016-04-28
# 3 41.55559065 None water course None 2016-04-28
# 4 13.34736581 None water course None 2016-04-28
# .. ... ... ... ... ...
# 334 649.54054944 None lake None 2016-04-28
# 335 303.66086309 None lake None 2016-04-28
# 336 15.99628769 None water course None 2016-04-28
# 337 377.19831 None lake None 2016-04-28
# 338 479.05509668 None lake None 2016-04-28
#
# geometry
# 0 POLYGON ((-113.88592 50.85995, -113.88591 50.8...
# 1 POLYGON ((-114.11757 50.91028, -114.11757 50.9...
# 2 POLYGON ((-114.11992 50.91971, -114.11992 50.9...
# 3 POLYGON ((-114.25190 51.02269, -114.25190 51.0...
# 4 POLYGON ((-114.19277 51.00366, -114.19281 51.0...
# .. ...
# 334 POLYGON ((-114.21012 51.03827, -114.21018 51.0...
# 335 POLYGON ((-114.01852 50.89452, -114.01849 50.8...
# 336 POLYGON ((-114.03763 50.86162, -114.03763 50.8...
# 337 POLYGON ((-113.96479 51.15260, -113.96480 51.1...
# 338 POLYGON ((-114.09421 50.89511, -114.09421 50.8...
#
# [339 rows x 6 columns]
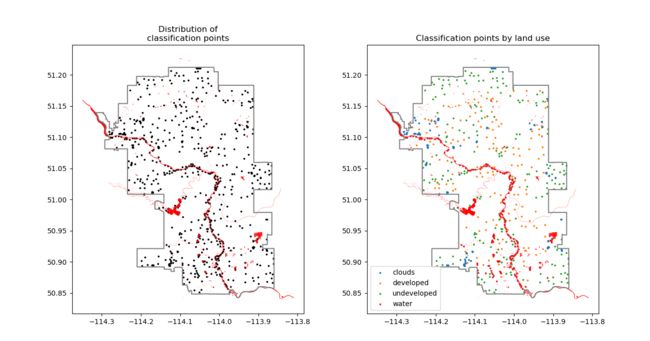
fig, ax = plt.subplots(ncols=2, nrows=1, figsize=(14, 7))
calgary_trainingpointer_gpd.plot(ax=ax[0], color='black', markersize=3)
for temp_type in calgary_trainingpointer_gpd['class'].unique().tolist():
calgary_trainingpointer_gpd.loc[calgary_trainingpointer_gpd['class'] == temp_type].plot(ax=ax[1],
label=temp_type, markersize=3)
for index in range(2):
cityboundary_gpd.boundary.plot(ax=ax[index], color='gray')
hydrology_gpd.plot(ax=ax[index], color='red')
ax[0].set_title("Distribution of\nclassification points")
ax[1].set_title("Classification points by land use")
ax[1].legend(loc='lower left')
这里就是基本的样本点:
- 左边的图:展示了区域、样本点的分布、河流。
- 右边的图:基于左边的图,还展示了各个点的类别:cloud、deleloped、undeveloped、water。
# [dataset_list[i].read().shape for i in range(len(dataset_list))]
all_read_vector = np.concatenate(
[dataset_list[i].read() for i in range(len(dataset_list))], axis=0)
def location2value(x, y):
row, col = dataset_list[0].index(x, y)
res = all_read_vector[:, row, col]
return pd.Series(res)
trainX = calgary_trainingpointer_gpd.to_crs(dataset_list[0].crs.to_string()).pipe(
lambda x: x.assign(**{
'lon': x.geometry.x,
'lat': x.geometry.y
})
).pipe(
lambda x: x.apply(lambda x: location2value(x['lon'], x['lat']), axis=1)
)
trainX
# 0 1 2 3 4 5 6 7 8 9
# 0 23278 24686 26910 29927 34254 30755 19882 5120 29911 27294
# 1 13592 13627 14518 15678 18062 18903 16396 5138 30276 27412
# 2 12979 12679 12513 12704 16030 15946 14071 5087 30123 27140
# 3 13547 13280 13815 14977 16552 15771 13154 5095 31188 28323
# 4 15238 15537 16206 17117 18014 26436 27730 5139 29918 25979
# .. ... ... ... ... ... ... ... ... ... ...
# 696 10015 9163 8331 7501 7036 5991 5768 5036 25666 23959
# 697 10109 9368 8931 8788 13583 14772 11269 5077 29650 27033
# 698 9627 8737 7928 7111 6517 5654 5482 5060 28599 26085
# 699 9679 8743 7797 6960 6569 5704 5522 5055 28434 25817
# 700 9691 8735 7710 6933 7435 6299 5930 5042 28929 26266
#
# [701 rows x 10 columns]
trainY = calgary_trainingpointer_gpd['class']
trainY
# 0 clouds
# 1 clouds
# 2 clouds
# 3 clouds
# 4 clouds
# ...
# 696 water
# 697 water
# 698 water
# 699 water
# 700 water
# Name: class, Length: 701, dtype: object
注意:
- 上面的trainX就是我们样本点的波段数据了,也就是叫X了。
- 上面的trainY就是我们的样本点的类别数据,也就是叫Y了。
step 4
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import confusion_matrix
- 这里对数据做分割,一部分是训练集、一部分是测试集合
X_train, X_test, y_train, y_test = train_test_split(
trainX, trainY, train_size=0.8, random_state=42)
X_train.shape
- 使用最简单的随机森林分类模型,参数也是默认的,
rf_fit = RandomForestClassifier() # SVC()
rf_fit.fit(X_train, y_train)
step 5
- 查看模型在训练集上的效果:可以看出来,在训练集上都学到了信息,并且分类也都全部正确。
# 混淆矩阵 on 训练集
predict_train = rf_fit.predict(X_train)
confusion_matrix(y_true=y_train, y_pred=predict_train)
# [[110 0 0 0]
# [ 0 126 0 0]
# [ 0 0 159 0]
# [ 0 0 0 165]]
- 查看模型在测试集上的效果,可以看到,有错误的点,但是整体上效果还好。
# 混淆矩阵 on 测试集
predict_test = rf_fit.predict(X_test)
confusion_matrix(y_test, predict_test)
# array([[35, 1, 0, 1],
# [ 1, 27, 0, 0],
# [ 0, 2, 39, 0],
# [ 0, 2, 0, 33]])
- 直接查看准确率,发现准确率为95%,还可以。
np.sum(y_test == predict_test) / predict_test.shape[0] * 100
# 95.0354609929078
step 6 & 7
# 将所有待预测的点全部整理成面板数据
predict_all_x = np.hstack([dataset_list[i].read().reshape(-1, 1)
for i in range(len(dataset_list))])
# 使用刚才的模型去预测所有的点的分类
predict_all_result = rf_fit.predict(predict_all_x)
# 将预测的标签和id进行转换
class_list = np.unique(predict_all_result).tolist()
class_dict = {value: index for index, value in enumerate(class_list)}
print(class_dict)
# 将预测的分类型数据整理成数值矩阵
result = pd.DataFrame({'class': predict_all_result})['class'].map(
class_dict).values.reshape(dataset_list[0].read().shape[1:])
result
# 有的点不属于预测范围内,因此把范围外的点给裁剪掉,这里就是mask掉(设置值为NAN)
# mask
# 因为有的数据点,不是区域内的,虽然做了预测,但是结果并不对,要mask掉
import shapely.vectorized
from shapely.geometry import shape
cityboundary_gpdnewcrs = cityboundary_gpd.to_crs(
dataset_list[0].crs.to_string())
x = np.linspace(dataset_list[0].bounds.left,
dataset_list[0].bounds.right, dataset_list[0].read().shape[2])
y = np.linspace(dataset_list[0].bounds.bottom,
dataset_list[0].bounds.top, dataset_list[0].read().shape[1])[::-1]
xx, yy = np.meshgrid(x, y)
mask_ = shapely.vectorized.contains(
shape(cityboundary_gpdnewcrs['geometry'][0]), xx, yy)
mask_.shape
result_mask = result.copy().astype(np.float)
result_mask[~mask_] = np.nan
# 可视化单一的模型效果图
fig, ax = plt.subplots(figsize=(10, 10))
cmap = cm.get_cmap('Blues', len(class_list))
clb = ax.imshow(result_mask, cmap=cmap, vmax=3+0.5, vmin=0-0.5)
cbar = fig.colorbar(clb, ticks=range(4))
cbar.ax.set_yticklabels(class_list, rotation=-45)
# ax[1].imshow(mask_)
# 可视化所有的图,三个图累加在一起
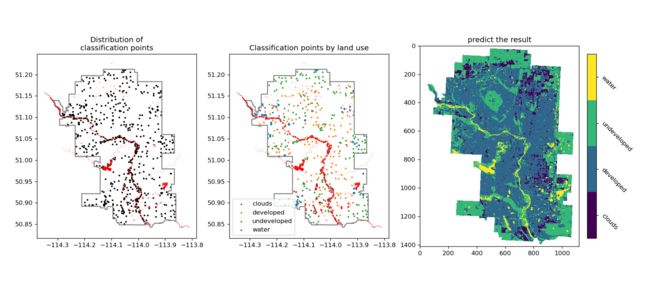
fig, ax = plt.subplots(ncols=3, nrows=1, figsize=(
14, 7), dpi=120, constrained_layout=True)
calgary_trainingpointer_gpd.plot(ax=ax[0], color='black', markersize=3)
for temp_type in calgary_trainingpointer_gpd['class'].unique().tolist():
calgary_trainingpointer_gpd.loc[calgary_trainingpointer_gpd['class'] == temp_type].plot(ax=ax[1],
label=temp_type, markersize=3)
for index in range(2):
cityboundary_gpd.boundary.plot(ax=ax[index], color='gray')
hydrology_gpd.plot(ax=ax[index], color='red')
ax[0].set_title("Distribution of\nclassification points")
ax[1].set_title("Classification points by land use")
ax[1].legend(loc='lower left')
cmap = cm.get_cmap('viridis', len(class_list))
clb = ax[2].imshow(result_mask, cmap=cmap, vmax=3+0.5, vmin=0-0.5)
ax[2].set_title("predict the result")
# 添加标签给colorbar
cbar = fig.colorbar(clb, ticks=range(4), shrink=0.6)
cbar.ax.set_yticklabels(class_list, rotation=-45)
fig.savefig("结果/plot20220907.png")
效果图1:

效果图2:
总结
- 本文只是介绍了非常简单的一个遥感数据模版:读数据、处理数据(包括使用机器学习建模了)、可视化数据。
- 没有介绍机器学习别的知识,我后面会带大家使用交叉验证等一些优秀的方法来分析处理数据。
- 里面还有一个彩蛋:对150万个点做mask,只用了0.1秒。
- 遥感数据千千万、机器学习模型、参数也是无穷无尽的。但是只要把握住本质,就可以逐一击破!
最后
- 我文章分享技术、代码都是公开免费的,但是帮助客户处理数据都是保密和收费的
- 我这里提供遥感数据分析建模服务,如果有需要的小伙伴可以联系我。
- 有交流群,希望加入的话,可以联系我,在交流群里你可以提需求,然后可能会复现~
阅读更多
list