语义分割系列教程2—pytorch实现
大家好,我是小开,今天给大家分享语义分割教程的第二部分。
这篇分享的内容是完整的实现语义分割的训练,无论实验结果如何,首先把模型跑起来,后面的教程我们会陆续进行优化。
完整的实验过程总共由以下四部分组成:
- 数据处理
- 模型设计
- 实验设置
- 训练
数据处理
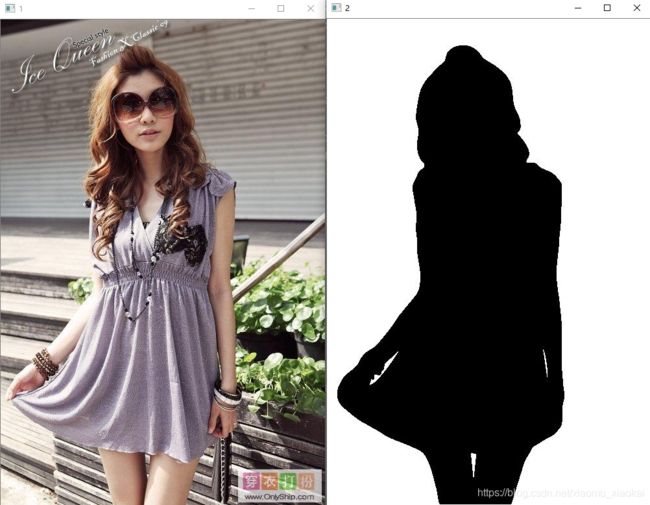
首先我们先看一下数据集中的数据,images文件夹中保存了图像的RGB原图,而profiles文件夹中保存了对应的mask图,下面是两组对应图像的示例:
首先,我们需要对图像进行读取,并将其对应的路径进行保存,其中image_list中保存了全部RGB图像的存储路径,label_list中保存了全部Mask图像的存储路径,具体实现代码如下:
def __init__(self):
dataset_save_path = '../dataset/baiduseg/clean_images/'
image_save_path = os.path.join(dataset_save_path, 'images')
label_save_path = os.path.join(dataset_save_path, 'profiles')
self.image_list = []
self.label_list = []
for i in os.listdir(image_save_path):
self.image_list.append(os.path.join(image_save_path, i))
for i in os.listdir(label_save_path):
self.label_list.append(os.path.join(label_save_path, i))
assert len(self.image_list) == len(self.label_list)在进行数据读取时,按照index拿出对应的RGB图像与mask图像,具体实现代码如下:
def __getitem__(self, item):
image = cv2.imread(self.image_list[item])
label = cv2.imread(self.label_list[item], cv2.IMREAD_GRAYSCALE)
image = cv2.resize(image, (256, 256))
label = cv2.resize(label, (256, 256)) / 255
image = image.astype(np.float32)
label = label.astype(np.float32)
image = image.swapaxes(0, 2).swapaxes(1, 2)
return image, label
模型设计
在模型上,我们这次采用了一个简单的U形网络设计,整体分为编码器与解码器两部分。
在编码器中不断进行下采样,减小特征图尺寸,提高channel数。这里我们采用步长为2的最大池化进行下采样操作。
比如初始的特征图尺寸为 (3, 256,256)
经过第一个下采样模块后特征图为(16,128,128),其中16是我们设置好的channel数,当然设置32,64都是可以的,channel数的设计直接影响到模型的性能与体积。
下采样模块的代码如下:
temp = self.convb1(inputs)
temp = self.downsample_pool_block_1(temp)其中,两部分的代码如下:
class ConvBlock(nn.Module):
def __init__(self, input_channel, output_channel, kernel_size=3, stride=1, padding=0):
super(ConvBlock, self).__init__()
self.conv_block = nn.Sequential(
nn.Conv2d(input_channel, output_channel, kernel_size, stride, padding=padding, bias=False),
nn.BatchNorm2d(output_channel, affine=False),
nn.ReLU(inplace=True),
)
def forward(self, inputs):
return self.conv_block(inputs)
-----------------------------------------------------------------------------------
self.convb1 = ConvBlock(3, 16, 3, 1, 1)
self.downsample_pool_block_1 = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)在上采样中,特征图的尺寸会不断扩大,channel数不断减小,最终网络的output为(1, 256,256),与mask图像的尺寸完全对应。
在上采样操作中,转置卷积与插值是比较常见的,这里我们使用双线性插值操作扩大特征图的尺寸,实现代码如下:
temp_shape = [temp.shape[2] * 2, temp.shape[3] * 2]
temp = F.interpolate(temp, size=temp_shape, mode="bilinear")
实验设置
在实验设置中,最重要的往往是loss函数的设计与优化器的选择,当然一些训练trick与超参数调优也是提升模型性能的关键,由于这篇教程仅仅是跑通训练,这里我们简单的选择了交叉熵作为损失函数,Adam作为我们的优化器,lr很随意的选择了0.0005,batch_size设置为16,就不再赘述了。
训练
训练共100个epoch,在每一个epoch中会对全部训练数据进行训练,代码如下:
for epoch in range(100):
net.train()
for bz_image, bz_label in train_loader:
bz_image = bz_image.to(device)
bz_label = bz_label.to(device)
bz_logit = net(bz_image)
loss, acc = ce_loss(bz_logit, bz_label)
optimizer.zero_grad()
loss.backward()
optimizer.step()
到这里我们就简单的实现了一个语义分割模型的训练,下次我们会针对各个部分进行模型性能的优化。
大家可以关注一下公众号:算法手记。
二维码在下面,所有教程的全部代码和一些干货分享都会及时发布到公众号里,谢谢大家支持了。
