大数据分析案例-基于KNN算法对茅台股票进行预测

♂️ 个人主页:@艾派森的个人主页
✍作者简介:Python学习者
希望大家多多支持,我们一起进步!
如果文章对你有帮助的话,
欢迎评论 点赞 收藏 加关注+
目录
1.项目背景
2.项目简介
2.1研究目的与意义
2.2研究方法与思路
2.3技术工具
3.算法原理
4.项目实施步骤
4.1理解数据
4.2探索性数据分析
4.3数据预处理
4.4特征工程
4.5模型构建
4.6模型评估
5.实验总结
源代码
1.项目背景
茅台集团于10月28日召开了“十四五”发展规划中期评估专题会议。尽管当前白酒板块资本市场波动较大,但白酒行业发展稳中向好的根本趋势没有改变,茅台产销势头良好,有信心、有能力确保股份公司未来实现持续稳健增长,全面完成“十四五”目标任务。对此,茅台集团进一步表示,信心主要源于各项改革成效显现在茅台酒、茅台酱香系列酒产质量稳定提升,产能将逐步释放。此外,渠道结构不断优化,统筹社会渠道商、茅台自营店、电商渠道商,构建了“一盘棋”的渠道格局,搭建了“i茅台”等贴近市场和消费者的直销渠道,成为业绩新增长极。不仅如此,茅台价格体系愈加完善,着力构建“品价匹配、层次清晰、梯度合理”的品牌产品结构,优化产品带和理顺价格带,今年来先后推出的珍品茅台、虎年生肖、茅台1935等新品,更好地满足了不同消费层次、不同消费群体的真实需求。未来,茅台将继续推进营销体制改革和价格市场化改革。本次实验就是研究茅台股票变动情况。
2.项目简介
2.1研究目的与意义
本次实验目的是研究茅台股票从2020年1月1日到2022年11月20日的股票价格变动情况,研究其变动趋势,构建涨跌预测模型。有利于政府、企业、股民等对其变动趋势做出相应的调整策略,规避风险。
2.2研究方法与思路
首先使用tushare第三方库读取茅台股票2020年到2022年11月20日的交易数据作为本次实验的数据集,接着查看数据的基本信息,了解数据,然后进行使用matplotlib进行数据可视化,做出k线图、5日和10日均线图,然后进行数据预处理构建目标特征,即涨(1)和跌(-1),接着通过特征筛选选出有用的特征,准备建模需要的数据,通过sklearn中的train_test_split来划分数据集,其中测试集比例为20%,训练集比例为80%,最后构建逻辑回归和KNN分类算法模型,通过模型在测试集上的准确率大小来评估模型的优劣,选出最佳模型后使用sklearn中的confusion_matrix混淆矩阵、classification_report分类报告、roc曲线来进行模型评估。
2.3技术工具
Python版本:3.9
代码编辑器:jupyter notebook
3.算法原理
(1)KNN算法简介
一提到KNN,很多人都想起了另外一个比较经典的聚类算法K_means,但其实,二者之间是有很多不同的,这两种算法之间的根本区别是,K_means本质上是无监督学习而KNN是监督学习,Kmeans是聚类算法而KNN是分类(或回归)算法。
古语说得好,物以类聚,人以群分;近朱者赤,近墨者黑。这两句话的大概意思就是,你周围大部分朋友是什么人,那么你大概率也就是这种人,这句话其实也就是KNN算法的核心思想。
(2)KNN算法的关键
①样本的所有特征都要做可比较的量化
若是样本特征中存在非数值的类型,必须采取手段将其量化为数值。例如样本特征中包含颜色,可通过将颜色转换为灰度值来实现距离计算。
②样本特征要做归一化处理
样本有多个参数,每一个参数都有自己的定义域和取值范围,他们对距离计算的影响不一样,如取值较大的影响力会盖过取值较小的参数。所以样本参数必须做一些 scale 处理,最简单的方式就是所有特征的数值都采取归一化处置。
③需要一个距离函数以计算两个样本之间的距离
通常使用的距离函数有:欧氏距离、余弦距离、汉明距离、曼哈顿距离等,一般选欧氏距离作为距离度量,但是这是只适用于连续变量。在文本分类这种非连续变量情况下,汉明距离可以用来作为度量。通常情况下,如果运用一些特殊的算法来计算度量的话,K近邻分类精度可显著提高,如运用大边缘最近邻法或者近邻成分分析法。
以计算二维空间中的A(x1,y1)、B(x2,y2)两点之间的距离为例,欧氏距离和曼哈顿距离的计算方法如下图所示:
④确定K的值
K值选的太大易引起欠拟合,太小容易过拟合,需交叉验证确定K值。
(3) KNN算法的评价
KNN算法的优点:
1.简单,易于理解,易于实现,无需估计参数,无需训练;
2.适合对稀有事件进行分类;
3.特别适合于多分类问题(multi-modal,对象具有多个类别标签), kNN比SVM的表现要好。
KNN算法的缺点:
KNN算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数,如下图所示。该算法只计算最近的邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。可以采用权值的方法(和该样本距离小的邻居权值大)来改进。
该方法的另一个不足之处是计算量较大,因为对每一个待分类的文本都要计算它到全体已知样本的距离,才能求得它的K个最近邻点。可理解性差,无法给出像决策树那样的规则。
4.项目实施步骤
4.1理解数据
首先导入本次实验用到的第三方库,并且调用tushare获取茅台的股票数据并查看前五行

接着使用shape查看数据大小

数据共有689行,7列
使用describe查看描述性统计信息
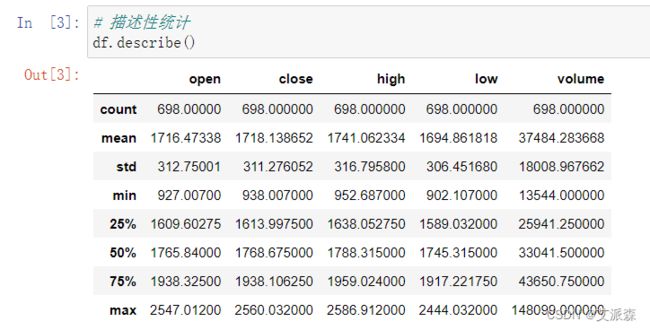
从数据描述性统计中,我们可以看出open、close、high、low、volume这五列特征的总数、均值、方差、最大最小值和四分位数。
4.2探索性数据分析
接着我们将数据进行可视化,做出K线图、5日和10日均线图


从图中我们可以看到,茅台股票价格从2020年开始直线增长,在2021年2月左右达到最高峰2500元,这中间的原因可能是因为从2020年1月疫情开始爆发导致了茅台价值直线上升,持续了一年,而后就开始下跌一段时间,又增长一段时间,这原因可能是经历了一年的疫情,疫情开始常态化,股票的价格就开始正常涨跌波动了。
4.3数据预处理
在数据预处理这,因为我们目标是预测股票的涨跌,属于二分类问题,所有这里我们需要构造股票在这一天是否涨跌这一列数据,即target。这里使用了NumPy库中的where()函数,传入的3个参数的含义分别为判断条件、满足条件的赋值、不满足条件的赋值,shift(-1)是将数据下移一行跟上一次比较,若差值大于0,则表示涨记为1,否则表示跌,记为-1。target里面,1表示次日上涨,-1表示次日下跌

4.4特征工程
这里,我们选取了开盘价open、收盘价close、最高值high、最低值low、交易量volume以及目标值target。

4.5模型构建
首先,准备建模需要的数据及X、y。然后划分数据集,测试集比例为20%,训练集比例为80%。

接着构建逻辑回归模型,并打印出其在测试集和训练集上的准确率
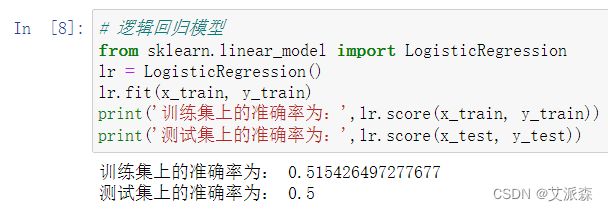
可以看出逻辑回归模型在训练集上的准确率为0.51,在测试集上的准确率为0.5.
构建KNN分类模型,并打印出其在测试集和训练集上的准确率
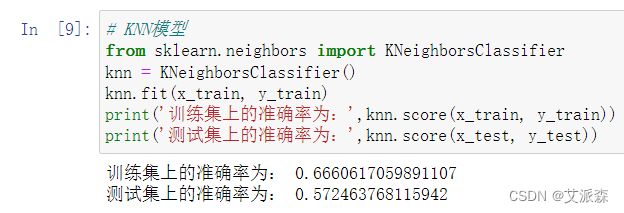
可以看出KNN分类算法在训练集上的准确率为0.66,在测试集上的准确率为0.57,模型效果明显大于逻辑回归模型,故我们使用KNN为最终的训练模型。
4.6模型评估
模型评估这里,我们使用sklearn中的confusion_matrix混淆矩阵和classification_report分类报告进行评估。
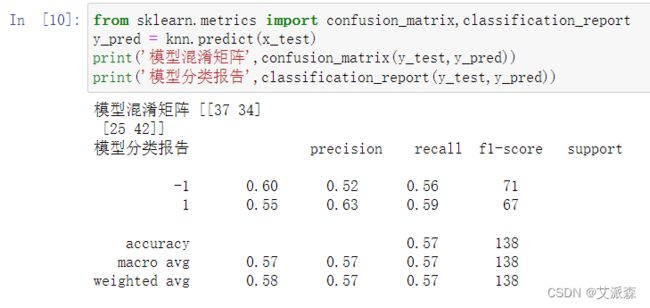
从混淆矩阵中我们可以看出模型在分类-1类时,有37个分类正确,有34个分类错误;在分类1类时,有25个分类错误,42个分类正确。从分类报告中,我们可以看出-1和1分类的精确率、召回率、f1值等数据。
最后,因为这是个二分类问题,我们还可以做出ROC曲线来评估模型的好坏。
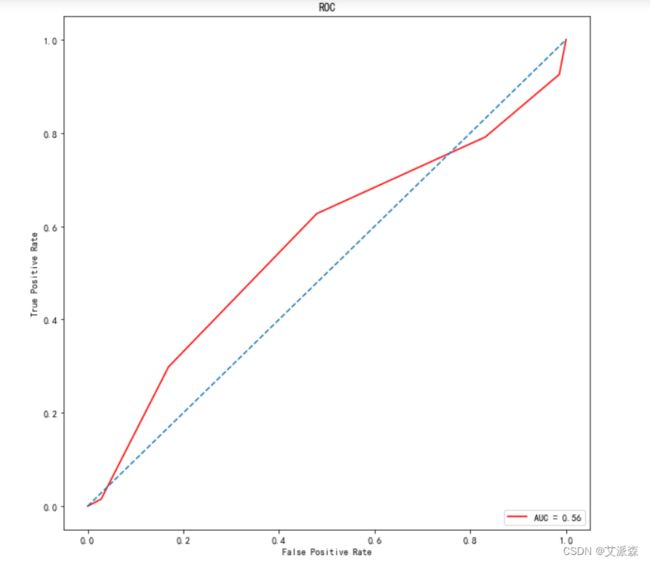
5.实验总结
通过本次股票预测实验,我们发现茅台的股票价格在疫情初期,也就是2020年,股票价格持续上涨,到2021年2月达到最高峰后开始在一个月内迅速下跌,之后便跌跌涨涨循环往复。最后使用KNN算法建立股票涨跌预测模型,最后得出的准确率为0.57,虽然比抛硬币的0.5概率高,但是还是较低,可能影响股票价格跌涨变动的因素有很多也很复杂,这里我们只是考虑了基本要素,模型效果还有待提高。
心得与体会:
通过这次Python项目实战,我学到了许多新的知识,这是一个让我把书本上的理论知识运用于实践中的好机会。原先,学的时候感叹学的资料太难懂,此刻想来,有些其实并不难,关键在于理解。
在这次实战中还锻炼了我其他方面的潜力,提高了我的综合素质。首先,它锻炼了我做项目的潜力,提高了独立思考问题、自我动手操作的潜力,在工作的过程中,复习了以前学习过的知识,并掌握了一些应用知识的技巧等
在此次实战中,我还学会了下面几点工作学习心态:
1)继续学习,不断提升理论涵养。在信息时代,学习是不断地汲取新信息,获得事业进步的动力。作为一名青年学子更就应把学习作为持续工作用心性的重要途径。走上工作岗位后,我会用心响应单位号召,结合工作实际,不断学习理论、业务知识和社会知识,用先进的理论武装头脑,用精良的业务知识提升潜力,以广博的社会知识拓展视野。
2)努力实践,自觉进行主角转化。只有将理论付诸于实践才能实现理论自身的价值,也只有将理论付诸于实践才能使理论得以检验。同样,一个人的价值也是透过实践活动来实现的,也只有透过实践才能锻炼人的品质,彰显人的意志。
3)提高工作用心性和主动性。实习,是开端也是结束。展此刻自我面前的是一片任自我驰骋的沃土,也分明感受到了沉甸甸的职责。在今后的工作和生活中,我将继续学习,深入实践,不断提升自我,努力创造业绩,继续创造更多的价值。
这次Python实战不仅仅使我学到了知识,丰富了经验。也帮忙我缩小了实践和理论的差距。在未来的工作中我会把学到的理论知识和实践经验不断的应用到实际工作中,为实现理想而努力。
源代码
import tushare as ts # 引入股票基本数据相关库
import numpy as np
import pandas as pd
import mpl_finance as mpf
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #解决中文显示
plt.rcParams['axes.unicode_minus'] = False #解决符号无法显示
import warnings
warnings.filterwarnings('ignore') # 忽略警告
# 获取茅台从2020年到2022年11月20日的股票基本数据
df = ts.get_k_data('600519', start='2020-01-01',end='2022-11-20')
print(df.head()) # 查看数据前五行
# 查看数据大小
print(df.shape)
# 描述性统计
print(df.describe())
# 导入调整日期格式涉及的两个库
from matplotlib.pylab import date2num
import datetime
# 将Tushare库中获取到的日期数据转换成candlestick_ochl()函数可读取的格式
def date_to_num(dates):
num_time = []
for date in dates:
date_time = datetime.datetime.strptime(date,'%Y-%m-%d')
num_date = date2num(date_time)
num_time.append(num_date)
return num_time
# 将DataFrame转换为二维数组,并利用date_to_num()函数转换日期格式
df_arr = df.values #将DataFrame格式的数据转换为二维数组
# 添加五日均线和10日均线
df['MA5'] = df['close'].rolling(5).mean()
df['MA10'] = df['close'].rolling(10).mean()
df_arr[:,0] = date_to_num(df_arr[:,0]) #将二维数组中的日期转换成数字格式
fig,ax = plt.subplots(figsize=(15,6))
mpf.candlestick_ochl(ax,df_arr,width=0.6,colorup='r',colordown='g',alpha=1.0)
plt.plot(df_arr[:,0],df['MA5'])
plt.plot(df_arr[:,0],df['MA10'])
plt.grid() # 显示网格
ax.xaxis_date() #设置x轴的刻度格式为常规日期格式
plt.title('茅台')
plt.xlabel('日期')
plt.ylabel('价格')
plt.show()
# 数据预处理-构造类别特征
df['target'] = np.where(df['close'].shift(-1) > df['close'],1,-1)
df.dropna(inplace=True) # 删除缺失值
print(df.head())
# 特征筛选
df2 = df[['open','close','high','low','volume','target']]
print(df2.head())
# 准备数据
X = df2.drop('target',axis=1)
y = df2['target']
# 划分数据集
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y,test_size=0.2)
# 逻辑回归模型
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(x_train, y_train)
print('训练集上的准确率为:',lr.score(x_train, y_train))
print('测试集上的准确率为:',lr.score(x_test, y_test))
# KNN模型
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier()
knn.fit(x_train, y_train)
print('训练集上的准确率为:',knn.score(x_train, y_train))
print('测试集上的准确率为:',knn.score(x_test, y_test))
from sklearn.metrics import confusion_matrix,classification_report
y_pred = knn.predict(x_test)
print('模型混淆矩阵',confusion_matrix(y_test,y_pred))
print('模型分类报告',classification_report(y_test,y_pred))
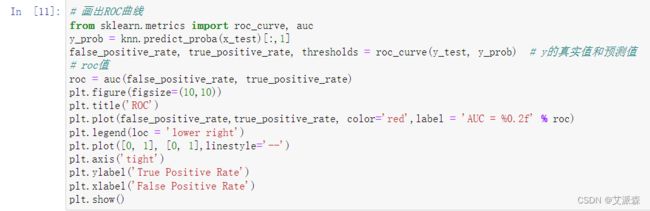
# 画出ROC曲线
from sklearn.metrics import roc_curve, auc
y_prob = knn.predict_proba(x_test)[:,1]
false_positive_rate, true_positive_rate, thresholds = roc_curve(y_test, y_prob) # y的真实值和预测值
# roc值
roc = auc(false_positive_rate, true_positive_rate)
plt.figure(figsize=(10,10))
plt.title('ROC')
plt.plot(false_positive_rate,true_positive_rate, color='red',label = 'AUC = %0.2f' % roc)
plt.legend(loc = 'lower right')
plt.plot([0, 1], [0, 1],linestyle='--')
plt.axis('tight')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.show()