工具 每分钟_手势自动标记及分类工具
传统的手势辨识主要采用图像处理手法,针对手部图片进行影像分析,着重在于形状及特征点的取得,缺点是需要控制严格的外在环境因子(如灯光、背景、颜色等),才能避免造成影像分析时的干扰,而近年来得利于 AI 技术,透过深度学习自动萃取特征并进行影像分类及对象侦测,可让手势辨识变得更加精确,也不易受外在环境所干扰。
不过,如果您打算自行训练一个手势辨识模型,首先要面对的第一项工作便是图片的搜集及标记,这是一项相当繁杂且花时间的人力密集工作,因此如果有个方便好用的工具能自动将影片或摄影机中的手势,自动裁切并依手势类型分类好,甚至还能将手势自动标记好,是不是非常方便呢?
这是可能的,只要先训练好一个侦测手部的模型,便可以利用它来制作一个手势自动分类及标记的工具,产生两种类型的 dataset:
1.Classified image dataset
2.VOC labeled dataset
本文目的是希望透过该工具,节省图片数据搜集、图片分类、图片标记这三项工作的时间,而我们唯一的工作仅是准备影片、在镜头前比出需要的各种手势,让该工具直接替我们产生出可直接用来训练影像分类或对象侦测使用的 dataset。
制作手部侦测模型
在设计这套工具前,我们需要训练一个手部侦测模型,这个模型的目的是「无论任何姿势,只要是人的手掌都要能侦测到」,至于如何训练该模型,您可使用任何常用的开源对象侦测 framework,下方我们分别以 YOLOV3-Tiny 以及 SSD-Mobilenet 2 作为训练示范,dataset 则是使用两种开源 hand dataset 以及一个自制的 hand dataset 来训练。
•训练的 dataset
下方介绍两个开源的 dataset 以及一个自己制作的 dataset:
A)EgoHands:A Datasetfor Hands in Complex Egocentric Interactions,
http://vision.soic.indiana.edu/projects/egohands/
该 dataset 来源为 48 个影片(二个人在进行互动游戏,以第一人称视角拍摄);图片尺寸为 720×1280 px,每个影片汇出 100 frames并已 labeled,总计 4800 张;Label 的格式为 matlab 的 mat 檔,poly 多边形(每个手部约 200~300 points)。

B)VGG hand dataset:
http://www.robots.ox.ac.uk/~vgg/data/hands/
VGG(Visual GeometryGroup)为牛津大学工程科学系的社群。内容分为train/test/validation 三个 dataset,图片来源为其它开源影像数据库(如 PASCAL VOC)及电影片段;
Label 为依物体长宽而变化倾斜的矩形,不是常用的左右垂直上下水平的 label,格式为使用 Matlab 的 mat 檔;图片尺寸不定,长宽一般介于 300~600 px 之间。

C)自拍的 hand dataset
使用 webcam 拍摄,尺寸为 640×480 px,数量 1723 张;原先是作为数字 0~5 的手势 dataset,使用 VOC 格式的 label;拍摄地点为 office。
•Hand dataset 格式转换
EgoHands 和 VGG hand dataset 的标记格式皆是Matlab 的 mat,我习惯先将它们转为 PASCAL VOC 格式,以方便后续YOLO 或是 SSD models 的训练。
A)EgoHands dataset
1. 下载 EgoHands dataset :进入http://vision.soic.indiana.edu/projects/egohands/ 后,点选下图中红框的link ,不需申请即可直接下载。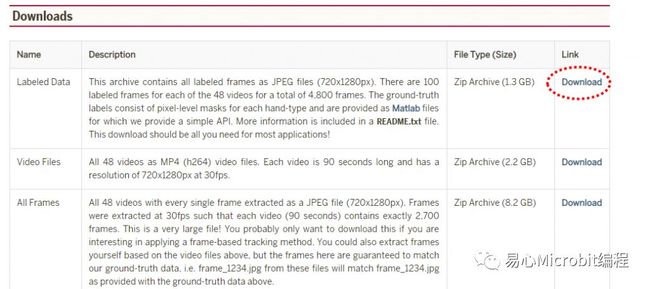
2. 解压后,第一层的 metadata.mat即为存放标记信息的地方,图片则放置于 _LABELLED_SAMPLES folder。
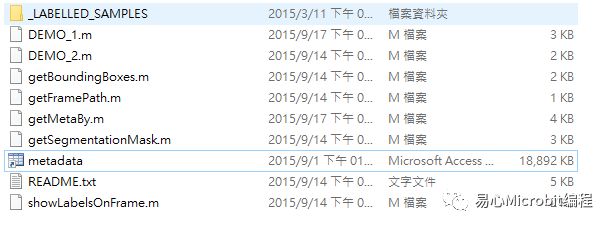
3. 转为 VOC 格式檔。
4. 转档结果:会于指定的 palm_egohands/目录下,产生 labels 及 images 两个文件夹,接着你可用 labelImg 开启,检验格式转换是否正确。
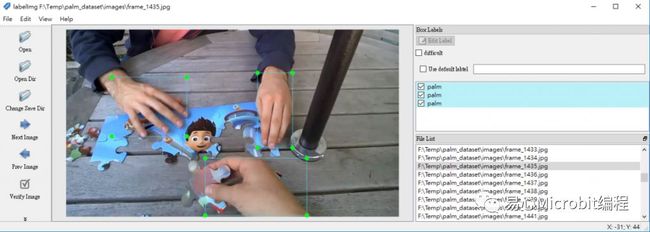
B)VGG hand dataset
1. 下载:进入http://www.robots.ox.ac.uk/~vgg/data/hands/,点选下方的 link,不需申请即可直接下载。

2. 下载解压后,内有 training、test、validation 等三个文件夹,每个文件夹下分为 images 及 annotations 两个目录,每个图文件搭配一个与图文件同名的 matlab 标记文件。
3. 新增 images 及 annotations目录,接着将各目录下的 images 图文件及 annotations 标记文件集中放置于新建的 images 及 annotations 文件夹中。
4. 转为 VOC 格式檔。
5. 转档结果:会于指定的palm_oxford_hands/train/ 目录下,产生 labels 及 images 两个文件夹,接着你可用 labelImg 开启,检验格式转换是否正确。

Palm detection 训练
下面我们分别使用 YOLOV3-Tiny 以及 SSD-Mobilenet 来训练此手部侦测模型:
•YOLOV3-Tiny 训练
可利用我之前所撰写的 makeYOLOV3 程序,只需要在安装好 Darknet 环境的 PC 上,输入 VOC 格式 dataset 的路径,便可自动转换为 YOLO dataset,接着产生 YOLO 的 data、cfg、names 等配置文件案,执行结束后会显示您所要执行的训练 command,只需要 copy/paste 执行该行指令便可开始训练。
另外,训练之前,建议先执行先验框程序,取得六组先验框(YOLOV3 为九组)放在 yolov3-tiny.cfg 的 anchors 参数中。训练过程如下:

•SSD-Mobilenet V2 训练
1. 转换为 TensorflowTF-Record dataset。
2. Download pre-trained model 及 config file。
3. 修改ssd_mobilenet_v2_coco.config 灰色字的部份。
num_classes:1
batch_size:24
fine_tune_checkpoint:“ssd_mobilenet_v2_coco/model.ckpt"
train_input_reader: {
tf_record_input_reader {
input_path: “ssd_dataset/train.record"
}
label_map_path:“ssd_dataset/object-detection.pbtxt"
}
eval_input_reader: {
tf_record_input_reader {
input_path: “ssd_dataset/test.record"
}
label_map_path:“ssd_dataset/object-detection.pbtxt"
shuffle: false
num_readers: 1}
4. 开始训练。
python train.py –logtostderr–train_dir=/home/chtseng/works/train_palm_model/training/–pipeline_config_path=/home/chtseng/works/train_palm_model/palm_ssd_mobilenet_v2.config
在 Jetson Nano 上测试手部侦测模型的效果
将图片 size 缩小至 VGA 尺寸后,Jetson Nano 开发板上透过 GPU 加速,YOLOV3-Tiny 与 SSD-MobileNetV2 的 FPS 皆可到七以上。
•YOLOV3-Tiny
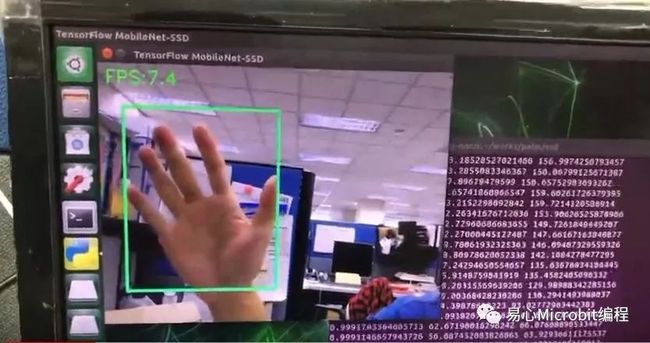
•SSD-MobileNetV2

这个手部侦测模型可协助我们取得影像中的手部区域,接着我们便可设计程序针对该区域进行标记或分类,以便产生手部的 classification dataset 以及 VOC labeleddataset。举例来说,我们透过键盘输入手势的名称,接着在镜头前比出各种需要的手势,该工具便可自动将手部区域 crop,另外储存为依类别分类的手势图片库,或者自动label 成 VOC dataset。
制作手势自动分类及标记工具
在上文中,我们已经利用数个开源的手势 dataset 训练好了一个可侦测手部的 YOLOV3-Tiny 模型,其效果如下:
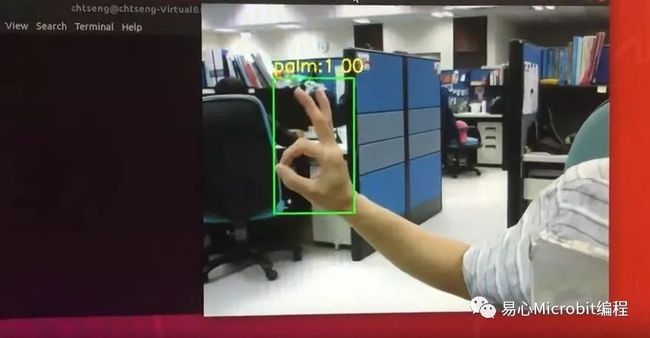
接下来将介绍如何利用此 model 来设计一个工具,协助我们产生 1)已 label 好的手势 VOC dataset、2)依手势类别分类好的 classified dataset。
使用说明
使用上相当简单,只用到两个快捷键:
•按下「l」录(小写的 L),可切换 class 名称,表示接下来的影像画面,若有侦测到手掌,其 class皆为指定的名称。
•按下「q」录,将结束此 auto labeling 程序。
执行:python3 auto_labeling_hand_gestures.py
操作示范
下面将示范如何透过本 auto labeling 程序制作一个手势 dataset:
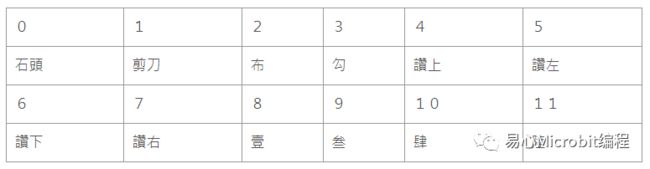
1. 执行auto_labeling_hand_gestures.py。
2. 按「l」键,输入「0」,接着在镜头前方比出石头的手势。
视 Frame rate 速度、设定的 frame interval 以及是否有侦测到手掌而定,每分钟所搜集到的 image 数量会有所差异;以我自己在 Intel i5-3470 CPU 透过 Virtual Box 执行为例,每分钟可搜集到 80 张左右的图片。
3. 依次按「l」键,分别输入各class 的代码(0~11),分别比出相对应的手势。
4. 可回头输入不同 class 的手势,本程序会自动将图片补在对应的 class 文件夹中。
5. 录制结束后,按「q」键结束。
将整个 Auto labeling 的操作过程录成影片,总共 12 种手势,在六分钟内便可录制完成。
https://www.youtube.com/watch?v=Z0z9_CgAnaQ&feature=emb_logo
自动产生的 Dataset
操作完成后,会在指定目录下产生出下列三种 dataset:
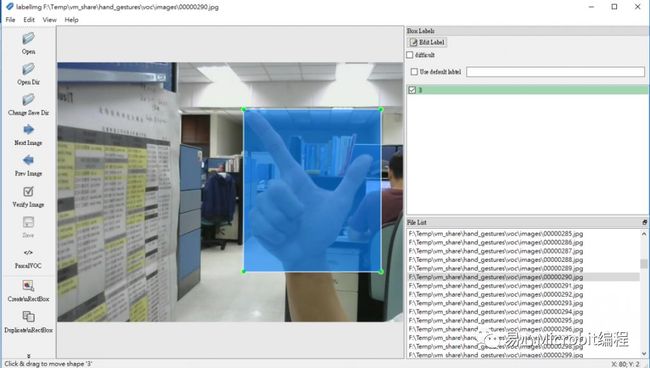
1.VOC 标记格式的 dataset,总共 1370 张。


2.分类好的手势图片,共有 12 个文件夹,每个文件夹约 100~200 张图片。
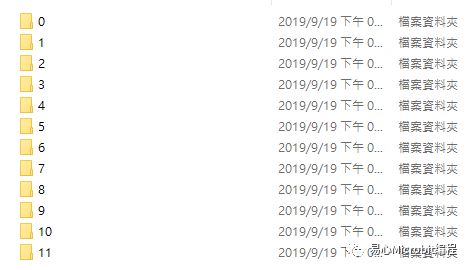

3.分类好的手势图片原图,共有 12 个文件夹,每个文件夹约 100~200 张图片。


小结
本次所示范自动产生的 dataset,其图片数目还不够,我们尚需不同的人物、场景及环境,来产生更多的图片才行。Auto labeling 并非万能,后续还是需要人工的 review、增修、标记框及筛选错误,若我们用于自动标记的模型训练得相当优异,那么后续的 review 时间肯定可以减少许多。
======================
