GoogLeNet(Inception V1)论文笔记及Pytorch代码解析
注: 本文仅供自己学习记录
感谢良心up同济子豪兄精彩讲解
【精读AI论文】GoogLeNet(Inception V1)深度学习图像分类算法_哔哩哔哩_bilibili
GoogLeNet(Inception V1)论文笔记
详细结构图:Netscope CNN Analyzer
论文概要
WE NEED TO GO DEEPER
Inception的技术演变
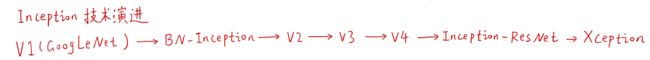
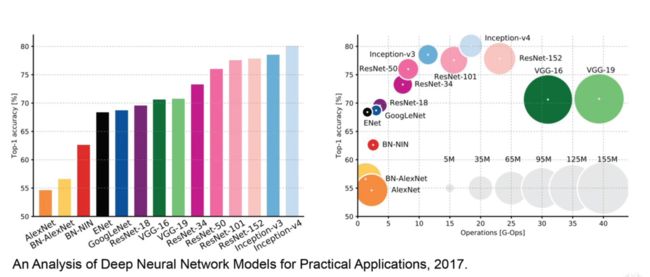
Inception不同于其他大型网络模型,可以方便的部署任何地方(边缘计算设备)
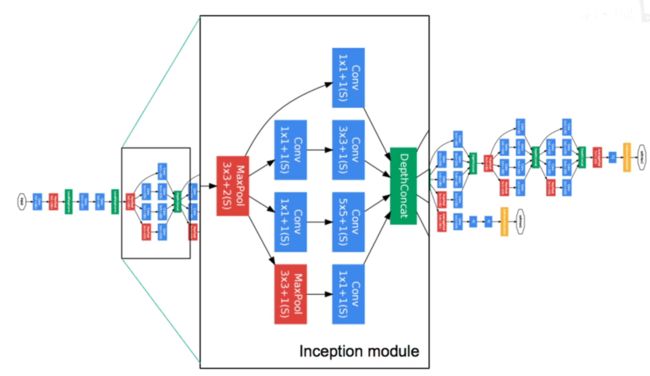
Inception原理图

将数据进行四路处理(不同尺度的卷积和一个池化),之后再汇总到cincatenate ,最后汇总的深度可以不同,长宽应该相同
提出了两种结构,
a是原生模块,问题是叠加越来愈大,导致计算量爆炸(尤其是池化层的计算量大)
b是改进版本(减少参数量和运算量),在进行3x3和5x5卷积之前,先使用1x1卷积进行降维,在池化层将池化后的数据进行1x1的卷积降维

其中GoogLeNet中的“Le"是在致敬LeNet-5
结构的优点
不管图像中需要提取的特征是占据图像大范围、占据部分图像还是占据小范围等情况,都可以通过不同卷积核(多尺度并行)提取到特征,并进行识别

1x1卷积核功能介绍

上图中一个原尺寸为64x64x192的数据块,使用1x1x192的卷积核扫描之后就可以得到一个64x64的二维图像,这是1x1卷积降维的做法
类似使用一把锥子将原三维图像扎在平面中,可以实现跨通道信息交流
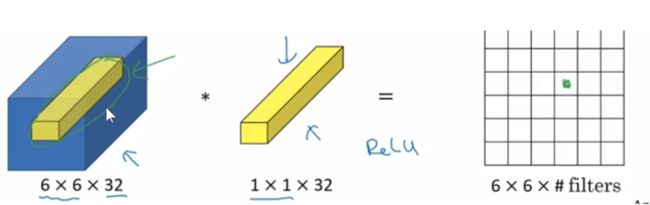
主要作用:
降维或者升维
跨通道信息交融
减少参数量
增加模型深度,提高非线性表示能力
思路来源
使用多个类型卷积核进行扫描再合并的思路来源于论文:Network In Network

其中将5x5的卷积使用16个1x1卷积核降维,再用32个5x5卷积核升维,这样做的效果和使用5x5直接进行卷积的效果是一样的,但是参数量相较之前少了很多
最后使用GAP(globle average pooling)代替全连接层,也可以大大减少参数量
卷积过程:

网络结构
将九个Inception模块累加起来,随着层数的增加,3x3和5x5的卷积核比例也在增加
GAP(globle average pooling)

每一个数据层都是用一个平均值来代表这一层,把一个三维的向量变成了一个一维的向量,大大减少了参数量。
传统的全连接层是将三维的向量拉成一个一维向量,由于和前面层中权重等参数的联系,所以中间要进行大量运算。

GAP不光可以减少参数量,还可以进行迁移学习
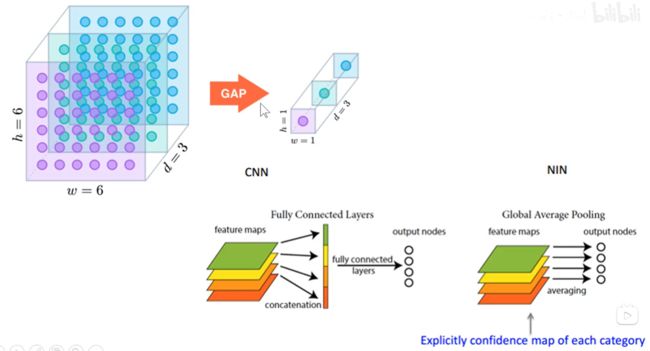
还可以用在类似注意力机制的方法中。在经过全卷积神经网络之后(空间信息没有丢失),进行softmax激活。把所有的权重值和之前全部层的数据相加就可以得到一张Class Activation Map,这张图体现了该分类在原图上的关注区域
该方法可以使用分类的模型进行定位、语义分割这样的弱监督或半监督学习

卷积核操作
可以将Inception结构中的5x5卷积拆分成两个3x3的卷积

也可以把3x3卷积在进行拆分,拆分成若干个1xn或nx1的卷积,可以在深度和宽度两个方向进行拆分在进行堆叠
Inception模型
Tensorflow和Pytorch 都有提供Inception的预训练模型,可以进行微调和迁移学习,我们可以通过模型在任何一个领域实现自己想要的结果
cs231n的课程中有相关Inception的延伸

Cs231n中对Inception的介绍
由于VGG是一个体量特别大,且计算量超大的模型,GoogLeNet采取另一种方式进行改进,使用Inception结构
传统结构的Inception结构的缺点就是参数量不够小,因为池化层的存在,

途中因为池化层的厚度为256,要保持整个输出厚度相同,其他的也要变成256,因此参数量增加。参数量的计算是由图中Conv Ops的计算方法,数据大小*感受野

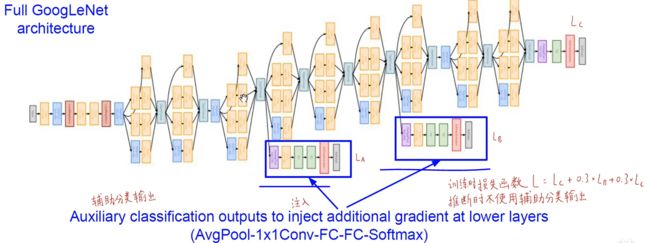
网络中还有两个辅助的分类器,分类器的作用是让网络更快的学习到分类的特征,起到正则化的作用,可以做到浅层和中间层都进行梯度注入功能,右下角为最终的损失函数公式
论文正文
论文作者团队

Abstract
通过精心制作的一个结构上,在增加网络深度和宽度的同时减少参数量和计算量
该方法来源于两个哲学理论,赫布理论和多尺度信息处理
赫布理论:神经元突触“用进废退” Fire together,wire together
多尺度信息处理:不同神经元(不同卷积核)提取到的不同特征进行融合
上面的结构最后归化为一个GoogLeNet,这是一个22层的深度网络。该结构在图像分类和目标检测的表现都不错
1、Introduction(背景介绍)
由于过去几年神经网络的发展(2012-2014),目标检测和物体识别得到了快速发展。不仅得益于硬件,数据集和更庞大复杂的模型,更得益于新的模型思路和改进结构
但是前几个优秀的网络框架是在仅使用当年的数据集的情况下(未扩展数据集)达到了最好的效果,因此不能只通过硬件提升和增大数据集来提升模型精度,还需要更优秀的算法
GoogLeNet比AlexNet少12倍参数量,但更加准确
该结构已经过时:这之前目标识别领域效果最好的模型是R-CNN,它是深度学习+传统计算机视觉协同的目标检测模型(先用候选框标出,在进行深度网络进行识别)
不能一味的追求精度提升,更要兼顾计算效率、能耗、内存占用以及部署在移动设备和嵌入式设备中的难度。
保证模型在测试阶段乘-加运算次数少于15亿次,不仅仅是实验室学术成果,更要贴近现实,保证基本的泛化性,可以使用在更大规模数据集。
两个是思想来源:
1)电影《盗梦空间》中的"we need to go deeper"
2)重要文献1:网中网
1x1卷积升维-降维 Global Average Pooling层取代全连接层
3)重要文献2:《Provable bounds for learning some deep representations》
用稀疏、分散的网络取代之前庞大密集臃肿的网络
2、Related Work(文献综述)
从1998年LeNet-5开始,奠定了CNN基础结构:(卷积+normalization+最大池化)xn + 全连接层xm
通过叠加卷积层提高精度,例如AlexNet和ZFNet
通过扩大宽度(layer size)提高精度,例如ZFNet、overfeat
使用dropout降低过拟合(dropout有专门的论文,具体可参考改论文)
Improving neural networks by preventing co-adaptation of feature detectors
虽然池化层丢失了空间像素精确信息,但是我们依然可以使用CNN进行定位和目标检测
受神经科学研究成果启发->多尺度信息融合(每一个视觉神经元关注的信息不同)
Network-in-Network文献中说到:
(既要增加深度也要增加宽度)
Inception模块中1x1卷积作用:
1)降维
2)减少参数量和运算量
3)增加模型深度提高非线性表达能力
之前最先进的网路机构是RBG大神(Gireshick)提出的R-CNN,
两阶段方法:
1)从图像的底层信息中找出候选框
2)再从候选框中使用CNN进行分类和回归
注:multi-bok方法可以提高候选框包含真实目标的比例,可以做到节省资源
3、Motivation and High Leval Considerations(哲学问题,Inception模块思想来源)
传统提高模型性能的方法:
1)增加深度(层数)
2)怎家宽度(卷积核个数)
适用于大规模标注好的数据集
上面方法的缺点:
1)参数过多,很容易导致过拟合
2)对小数据集和获取标注成本大的数据集不适用
例如:(细粒度)对于图片中两种狗的差别普通人很难区分,需要专家对两种类别进行标识,增大了成本

计算效率也是问题之一:两个相连卷积层,两层同步增加卷积核个数,计算量将平方增加。
如果很多权重训练后接近0,这部分计算效率就被浪费。
问题总结:不能不考虑计算效率,不计成本追求精度
解决思路:想要从根本上解决这些问题(过拟合和计算效率),可以使用稀疏连接结构取代密集连接
文中举例:Inception结构使用四路分支进行卷积处理,传统的VGG或者是ALEX结构只是一路,相比之下Inception就是使用的稀疏结构。另外一个文献提到了一种类似于赫布学习法则(神经元之间的突触用进废退)的假设,人的每个神经元(机器神经元类似)有识别物体不同部位的功能,一只猫的耳朵、眼睛、鼻子等部位会被相应功能的神经元提取,如果一张图片中有猫出现,那么这些特征肯定都会同时出现。
稀疏结构的问题:现有的设备(CPU或者GPU),它们在密集连接中是高效的,在稀疏结构中是低效的,尽管计算量相比密集连接少了100倍,对于查表运算和缓存失准的开支都会导致计算瓶颈
对于稀疏结构的解释(有点哲学意味):
1)首先卷积的过程就具有稀疏连接的用法,在卷积核对图片扫描的过程中,一次卷积仅提取一部分的特征
2)在Le-Net中,将上一层的部分通道组合后传入下一层,到了AlexNet,使用上一层所有通道一起参与卷积,实现更好的并行运算加速
提出了一个新问题:能否在仍旧利用现有硬件进行密集矩阵运算的条件下,改进模型结构,哪怕只是在卷积层水平改进,从而能够利用额外的稀疏性呢?
另外将系数矩阵分解为密集的子矩阵,能够加速矩阵乘法,也许在不远的未来会有人实现这种
non-uniform deep-learning architectures
Inception结构是在基于密集连接运算的情况使用稀疏连接结构,以此达到精度最高且运算效率最高的情况。在目标检测领域,使用R-CNN和Inception结构结合可以达到很好的效果(文中在原理介绍这里提到的猜测成分,我没看太懂,不过不影响整体结构)
Inception背后原理需要进一步探索,如果自动机器学习工具Automl能在各种情景下设计出类似结构的网络,那么证明Inception思路是正确的(还是再说这个想法是猜想)
4、Architectural Details(结构具体介绍)
设计思想
用密集模块去近似出局部最优稀疏结构,聚合高相关性的特征输入到下一层。
局部信息由1x1卷积提取,越靠前面的层越提取局部信息,大范围空间信息由大卷积核提取,越靠后面的层越提取大范围空间信息
为了保证四个支路输出大小相同使用patch对齐,使用pading填充长宽相同,通道数不同
池化分支很有用,所以四路中应该有一个池化分支
整体结构特征是3x3和5x5卷积核比例随模型加深提高
原生Inception模块问题,通道数越大,参数量爆炸

结构细节介绍
对于改进版Inception的方法,
使用1x1进行降维,尽可能的减少产数量,但是也不能使用太多的降维计算,太过密集压缩的嵌入向量不便于模型处理(既要使用降维 解决参数爆炸,也要尽可能减少使用,保证稀疏结构),所以是在3x3和5x5卷积层之前应用1x1卷积降维,之后在使用relu线性激活函 数,其作用是降维、减少参数量、增加非线性,增加模型深度。
Inception模块的位置:
底层先用普通卷积层,后面用Inception模块堆叠,主要考虑到训练时的内存
好处:
因为使用了1x1的卷积,所以在堆叠模块时没有计算量爆炸
视觉信息多尺度并行分开处理再融合汇总,比较符合人类神经系统
增加模型宽度和深度,精心调整后可实现,比相同精度普通网络快2~3倍
5、GoogLeNet
名字来源:This name is an homage to Yann LeCuns pioneering LeNet 5 network (致敬LeNet网络)
GoogLeNet网络结构及相关参数
前几层是普通神经网络
后面堆叠九个Inception模块
最后进行Global Average Pooling(全局平均池化):一个channel用平均值代表,取代全连接层 减少参数量
权重和计算量均匀分配给各层
这是在试验了多个中结构之后效果最好的网络结构,具体参数如下表

细节介绍
1)所有卷积使用Relu激活函数,1x1卷积后面也是用Relu激活函数
2)在计算资源,内存读写首先设备上便于部署22层有权重的层,算上Inception内部共100层
3)用GAP代替全连接层(展平层):
1.便于fine-tune迁移学习
2.提升了0.6%的top-1准确率
4)最后一层需要使用dropout防止过拟合
5)增加了两个辅助分类器
浅层特征对于分类已经有足够的区分性, 在4a和4d模块后面加辅助分类器
辅助分类器的参数被提供给训练最后的损失函数
L=L(最后)+0.3xL(辅1)+0.3xL(辅2)
![]()
测试阶段需要去掉辅助分类器
注:浅层的辅助分类器后面被证实没太大用处,作者在Inception v2/v3的论文中去掉了浅层辅助分类器
完整结构图如下:
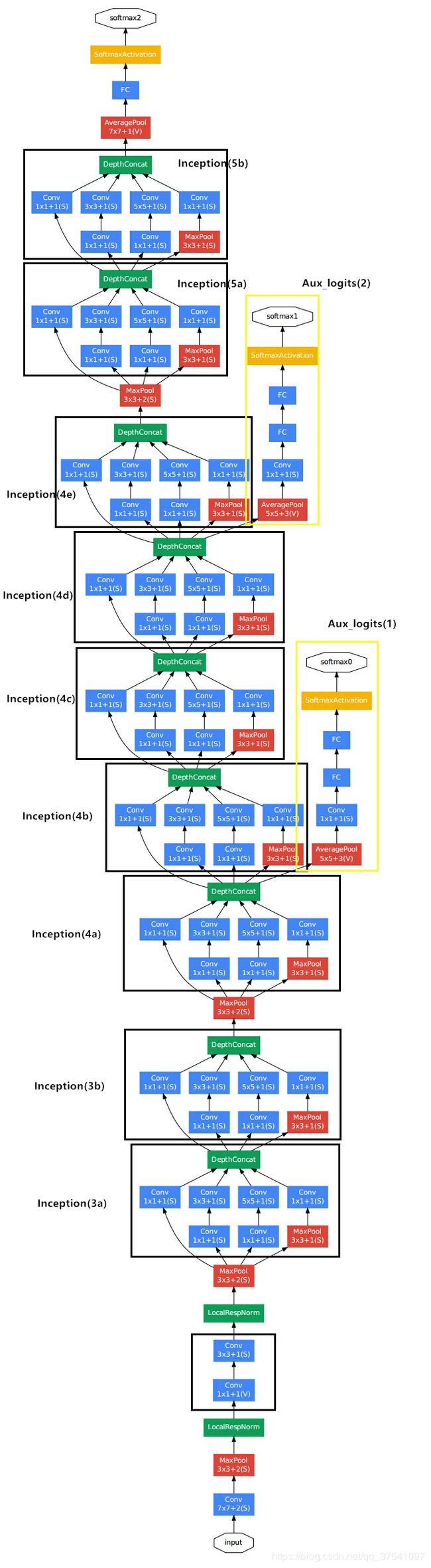
下图为同济子豪解析图:




6、Training Methodology
方法设定:
1)数据并行,一个batch均分K份,让不同节点前向和反向传播,再由中央param server优化更新权重
把一个大的batch分成K份处理,可以在通的时间内处理更多数据
2)由于使用数据并行处理,所以也要使用异步随机梯度下降,动量为0.9,学习率每八轮降低4%,指数衰减平均(动量)
3)调参玄学(一些调整参数的小技巧)
1.裁剪为原图8%到100之间,宽高比3/4和4/3之间
2.data enhancement(数据增强)
3.使用随机插值(bilinear, area, nearest neighbor and cubic,with equal probability)等概率使用不同差值方法
注:以上的调参方法和图像增强技巧对最后结果有没有用作者也说不清楚
7、ILSVRC 2014 Classification Challenge Setup and Results (分类竞赛)
其中2014年的分类竞赛一共是有一百二十万张训练集图像,五万张验证集图像和十万张测试集图像,1000个分类,每个图像有一个标签
两个评价指标:
1)TOP1:第一个猜想结果就是答案
2)TOP5:前五个猜测结果中包含答案
识别分类:
1)一个好的模型应该是好而不同,文中用到的七个模型集成,每个模型使用相同的初始化方法甚至相同的初始值,相同的学习率策略,仅在图像采样和输入顺序有区别,这里作者在文中也承认了这个错误,由于一些疏忽导致了这样的结果
2)将原图缩放为短边长度256,288,320,352的四个尺度,每个尺度裁出左中右(或上中下)三张小图,每张小图取四个角和中央的五张224x224的patch以及每张小图缩放至224x224,一共是六个patch,同时取其镜像。综上一共4x3x6x2=144个patch
七个模型对一张图的144个patch进行处理再融合。
对144个patch的softmax分类结果取平均
注:这种方式太过激进,在现实应用中不需要,因为可以看到裁剪144个相对于裁剪10个的精度提升不大,裁剪数量对精度的提升是有限的
结果比较如下:

图像增强和图像裁剪实验的对比结果,发现模型集成越多,图像裁剪-增强越多,整个模型的精度就越高,也证明了该操作对提升精度是有用的。

之后对模型的优秀分类能力进行介绍(略)
8、ILSVRC 2014 Detection Challenge Setup and Results(物体检测竞赛)
评判标准:如果算法给出的框分类正确且与正确标签框的交并比IOU(Jaccard相似度)>0.5,就认为这个框预测正确
使用map作为模型评估指标,每个类别不同阈值下precison-recall曲线围成的面积--AP(0-100,越高越好)
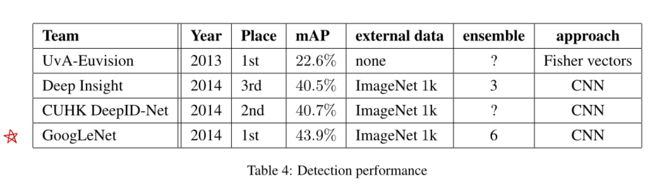
识别结果对比表:

与R-CNN的比较:
1)结合selective search 和multi-box prediction减少无用的候选框
2)没有使用框回归直接对候选框分类
3)使用Inception模型作为分类器
9 、Conclusions
我们的结果似乎提供了一个坚实的证据,即通过现成的密集构建块逼近预期的最佳稀疏结构是改进计算机视觉神经网络的一种可行方法。该方法的主要优点是在计算需求适度增加的情况下,显著提高了质量。
我们的方法提供了坚实的证据,证明转向更稀疏的体系结构总体上是可行和有用的。这表明在[2]的基础上,未来有希望以自动化方式创建更稀疏、更精细的结构。
References
[1]Know your meme: We need to go deeper.http://knowyourmeme.com/memes/we-need-to-go-deeper. Accessed: 2014-09-15.
网络流行梗,盗梦空间
[2]Sanjeev Arora, Aditya Bhaskara, Rong Ge, and Tengyu Ma. Provable bounds for learning some deep representations.CoRR, abs/1310.6343, 2013
涉及到大量的数学推导,主要思想是用稀疏、分散的网络代替庞大臃肿的、密集的网络
[3]Ümit V . C ¸ atalyürek, Cevdet Aykanat, and Bora Uc ¸ar. On two-dimensional sparse matrix partitioning: Models, methods, and a recipe.SIAM J. Sci. Comput., 32(2):656–683, February 2010.
将稀疏矩阵分解为密集的子矩阵,能加速矩阵乘法
[6]Ross B. Girshick, Jeff Donahue, Trevor Darrell, and Jitendra Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. InComputer Vision and Pattern Recognition, 2014. CVPR 2014. IEEE Conference on, 2014.
R-CNN目标检测模型论文
[9]Alex Krizhevsky, Ilya Sutskever, and Geoff Hinton. Imagenet classification with deep convolutional neural networks. InAdvances in Neural Information Processing Systems 25, pages 1106–1114, 2012.
AlexNet网络框架论文
[12]Min Lin, Qiang Chen, and Shuicheng Yan. Network in network.CoRR, abs/1312.4400, 2013.
文中提出1x1卷积和Global Average Pooling
[19]Alexander Toshev and Christian Szegedy. Deeppose: Human pose estimation via deep neural networks.CoRR, abs/1312.4659, 2013.
deeppose人体姿态估计模型
[20]Koen E. A. van de Sande, Jasper R. R. Uijlings, Theo Gevers, and Arnold W. M. Smeulders. Segmentation as selective search for object recognition. InProceedings of the 2011 International Conference on Computer Vision, ICCV ’11, pages 1879–1886, Washington, DC, USA, IEEE Computer Society.
selective search生成目标检测候选框的region proposal方法
[21]Matthew D. Zeiler and Rob Fergus. Visualizing and understanding convolutional networks. In David J. Fleet, Tomás Pajdla, Bernt Schiele, and Tinne Tuytelaars, editors,Computer Vision ECCV 2014 - 13th European Conference, Zurich, Switzerland, September 6-12, 2014, Proceedings, Part I, volume 8689 ofLecture Notes in Computer Science, pages 818–833. Springer,2014.
ZFNet 2013年ILSVRC分类竞赛冠军(文中涉及到反卷积和卷积可视化的做法和成果)
pytorch代码表示及注释
#该代码应该是改进了很多版本的代码,跟原始Inception V1可能会有不同
import warnings
from collections import namedtuple
from typing import Optional, Tuple, List, Callable, Any
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from .._internally_replaced_utils import load_state_dict_from_url
from ..utils import _log_api_usage_once
__all__ = ["GoogLeNet", "googlenet", "GoogLeNetOutputs", "_GoogLeNetOutputs"]
#下面几行都是存储的一些名词,后面在对应层会取用
model_urls = {
# GoogLeNet ported from TensorFlow
"googlenet": "https://download.pytorch.org/models/googlenet-1378be20.pth",
}
GoogLeNetOutputs = namedtuple("GoogLeNetOutputs", ["logits", "aux_logits2", "aux_logits1"])
GoogLeNetOutputs.__annotations__ = {"logits": Tensor, "aux_logits2": Optional[Tensor], "aux_logits1": Optional[Tensor]}
# Script annotations failed with _GoogleNetOutputs = namedtuple ...
# _GoogLeNetOutputs set here for backwards compat
_GoogLeNetOutputs = GoogLeNetOutputs
#其中_xxx和xxx本质上是相同的,唯一的区别就是_XXX代表的是in_palce
#in-place操作,意思是所有的操作都是”就地“操作,不允许进行移动,或者称作原位操作,即不允许使用临时变量
class GoogLeNet(nn.Module):
__constants__ = ["aux_logits", "transform_input"]
#参数初始化
def __init__(
self,
num_classes: int = 1000,
aux_logits: bool = True,
transform_input: bool = False,
init_weights: Optional[bool] = None,
blocks: Optional[List[Callable[..., nn.Module]]] = None,
#两种不同德dropout率,分别用在辅助分类器和最后输出之前,防止过拟合
dropout: float = 0.2,
dropout_aux: float = 0.7,
) -> None:
super().__init__()
_log_api_usage_once(self)
if blocks is None:
blocks = [BasicConv2d, Inception, InceptionAux]
if init_weights is None:
warnings.warn(
"The default weight initialization of GoogleNet will be changed in future releases of "
"torchvision. If you wish to keep the old behavior (which leads to long initialization times"
" due to scipy/scipy#11299), please set init_weights=True.",
FutureWarning,
)
init_weights = True
assert len(blocks) == 3
#对应模块,对应名称
conv_block = blocks[0]
inception_block = blocks[1]
inception_aux_block = blocks[2]
#设置各个小模块中的基本参数,卷积核、步长、pading等,具体参数的意义在后面函数定义中查看
self.aux_logits = aux_logits
self.transform_input = transform_input
#其中的参数都对应各个模块固定值,不用更改
self.conv1 = conv_block(3, 64, kernel_size=7, stride=2, padding=3)
self.maxpool1 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.conv2 = conv_block(64, 64, kernel_size=1)
self.conv3 = conv_block(64, 192, kernel_size=3, padding=1)
self.maxpool2 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception3a = inception_block(192, 64, 96, 128, 16, 32, 32)
self.inception3b = inception_block(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = nn.MaxPool2d(3, stride=2, ceil_mode=True)
self.inception4a = inception_block(480, 192, 96, 208, 16, 48, 64)
self.inception4b = inception_block(512, 160, 112, 224, 24, 64, 64)
self.inception4c = inception_block(512, 128, 128, 256, 24, 64, 64)
self.inception4d = inception_block(512, 112, 144, 288, 32, 64, 64)
self.inception4e = inception_block(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = nn.MaxPool2d(2, stride=2, ceil_mode=True)
self.inception5a = inception_block(832, 256, 160, 320, 32, 128, 128)
self.inception5b = inception_block(832, 384, 192, 384, 48, 128, 128)
#辅助分类器初始化,是不是需要加入
if aux_logits:
self.aux1 = inception_aux_block(512, num_classes, dropout=dropout_aux)
self.aux2 = inception_aux_block(528, num_classes, dropout=dropout_aux)
else:
self.aux1 = None # type: ignore[assignment]
self.aux2 = None # type: ignore[assignment]
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.dropout = nn.Dropout(p=dropout)
self.fc = nn.Linear(1024, num_classes)
if init_weights:
self._initialize_weights()
#下划线前缀的含义是告知其他程序员:以单个下划线开头的变量或方法仅供内部使用。 该约定在PEP 8中有定义。
#该函数仅供内部调用,运行过程中不用管他,查看代码时要看这部分,这部分代码才是真正的实际操作
def _initialize_weights(self) -> None:
for m in self.modules():
if isinstance(m, nn.Conv2d) or isinstance(m, nn.Linear):
torch.nn.init.trunc_normal_(m.weight, mean=0.0, std=0.01, a=-2, b=2)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
#处理一下输入,torch.unsqueeze升维
def _transform_input(self, x: Tensor) -> Tensor:
if self.transform_input:
x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5
x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5
x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5
x = torch.cat((x_ch0, x_ch1, x_ch2), 1)
return x
#前向传导大过程,带入前面设定好的模块
def _forward(self, x: Tensor) -> Tuple[Tensor, Optional[Tensor], Optional[Tensor]]:
# N x 3 x 224 x 224
x = self.conv1(x)
# N x 64 x 112 x 112
x = self.maxpool1(x)
# N x 64 x 56 x 56
x = self.conv2(x)
# N x 64 x 56 x 56
x = self.conv3(x)
# N x 192 x 56 x 56
x = self.maxpool2(x)
# N x 192 x 28 x 28
x = self.inception3a(x)
# N x 256 x 28 x 28
x = self.inception3b(x)
# N x 480 x 28 x 28
x = self.maxpool3(x)
# N x 480 x 14 x 14
x = self.inception4a(x)
# N x 512 x 14 x 14
aux1: Optional[Tensor] = None
if self.aux1 is not None:
if self.training:
aux1 = self.aux1(x)
x = self.inception4b(x)
# N x 512 x 14 x 14
x = self.inception4c(x)
# N x 512 x 14 x 14
x = self.inception4d(x)
# N x 528 x 14 x 14
aux2: Optional[Tensor] = None
if self.aux2 is not None:
if self.training:
aux2 = self.aux2(x)
x = self.inception4e(x)
# N x 832 x 14 x 14
x = self.maxpool4(x)
# N x 832 x 7 x 7
x = self.inception5a(x)
# N x 832 x 7 x 7
x = self.inception5b(x)
# N x 1024 x 7 x 7
x = self.avgpool(x)
# N x 1024 x 1 x 1
x = torch.flatten(x, 1)
# N x 1024
x = self.dropout(x)
x = self.fc(x)
# N x 1000 (num_classes)
return x, aux2, aux1
#下面的函数作为@后面的torch.jit.unused函数的入参,这种操作的返回(这两部操作也组成一个函数)作为B函数的实际功能。
#举例
'''def decorator(func):
return func
@decorator
def some_func():
pass'''
#等同于
'''
def decorator(func):
return func
def some_func():
pass
some_func = decorator(some_func)
'''
@torch.jit.unused
def eager_outputs(self, x: Tensor, aux2: Tensor, aux1: Optional[Tensor]) -> GoogLeNetOutputs:
if self.training and self.aux_logits:
return _GoogLeNetOutputs(x, aux2, aux1)
else:
return x # type: ignore[return-value]
#整个网络的最后输出,三个出来的值(两个辅助分类器和最后的输出),最后分别使用对应权重进行求和
def forward(self, x: Tensor) -> GoogLeNetOutputs:
x = self._transform_input(x)
x, aux1, aux2 = self._forward(x)
aux_defined = self.training and self.aux_logits
if torch.jit.is_scripting():
if not aux_defined:
warnings.warn("Scripted GoogleNet always returns GoogleNetOutputs Tuple")
return GoogLeNetOutputs(x, aux2, aux1)
else:
return self.eager_outputs(x, aux2, aux1)
#inception模块定义,详细结构
#里面参数是
class Inception(nn.Module):
def __init__(
self,
in_channels: int,
ch1x1: int,
ch3x3red: int,
ch3x3: int,
ch5x5red: int,
ch5x5: int,
pool_proj: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
#下面四路分别代表了竖直方向的四路,进行不同的操作,有1x1、3x3、5x5、池化
self.branch1 = conv_block(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
conv_block(in_channels, ch3x3red, kernel_size=1), conv_block(ch3x3red, ch3x3, kernel_size=3, padding=1)
)## 保证输出大小等于输入大小
self.branch3 = nn.Sequential(
conv_block(in_channels, ch5x5red, kernel_size=1),
# Here, kernel_size=3 instead of kernel_size=5 is a known bug.
# Please see https://github.com/pytorch/vision/issues/906 for details.
conv_block(ch5x5red, ch5x5, kernel_size=3, padding=1),
)# 保证输出大小等于输入大小
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
conv_block(in_channels, pool_proj, kernel_size=1),
)
def _forward(self, x: Tensor) -> List[Tensor]:
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return outputs
def forward(self, x: Tensor) -> Tensor:
outputs = self._forward(x)
return torch.cat(outputs, 1)
#辅助分类器中发生模块,卷积、全连接、dropout
class InceptionAux(nn.Module):
def __init__(
self,
in_channels: int,
num_classes: int,
conv_block: Optional[Callable[..., nn.Module]] = None,
dropout: float = 0.7,
) -> None:
super().__init__()
if conv_block is None:
conv_block = BasicConv2d
self.conv = conv_block(in_channels, 128, kernel_size=1)
self.fc1 = nn.Linear(2048, 1024)
self.fc2 = nn.Linear(1024, num_classes)
self.dropout = nn.Dropout(p=dropout)
#顺序为平均池化-》1x1卷积-》1024全连接-》relu-》dropout-》1000线性全连接
def forward(self, x: Tensor) -> Tensor:
# aux1: N x 512 x 14 x 14, aux2: N x 528 x 14 x 14
x = F.adaptive_avg_pool2d(x, (4, 4))
# aux1: N x 512 x 4 x 4, aux2: N x 528 x 4 x 4
x = self.conv(x)
# N x 128 x 4 x 4
x = torch.flatten(x, 1)
# N x 2048
x = F.relu(self.fc1(x), inplace=True)
# N x 1024
x = self.dropout(x)
# N x 1024
x = self.fc2(x)
# N x 1000 (num_classes)
return x
class BasicConv2d(nn.Module):
def __init__(self, in_channels: int, out_channels: int, **kwargs: Any) -> None:
super().__init__()
self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)
self.bn = nn.BatchNorm2d(out_channels, eps=0.001)
def forward(self, x: Tensor) -> Tensor:
x = self.conv(x)
x = self.bn(x)
return F.relu(x, inplace=True)
def googlenet(pretrained: bool = False, progress: bool = True, **kwargs: Any) -> GoogLeNet:
r"""GoogLeNet (Inception v1) model architecture from
`"Going Deepe s" `_.
The required minimum input size of the model is 15x15.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
aux_logits (bool): If True, adds two auxiliary branches that can improve training.
Default: *False* when pretrained is True otherwise *True*
transform_input (bool): If True, preprocesses the input according to the method with which it
was trained on ImageNet. Default: True if ``pretrained=True``, else False.
"""
if pretrained:
if "transform_input" not in kwargs:
kwargs["transform_input"] = True
if "aux_logits" not in kwargs:
kwargs["aux_logits"] = False
if kwargs["aux_logits"]:
warnings.warn(
"auxiliary heads in the pretrained googlenet model are NOT pretrained, so make sure to train them"
)
original_aux_logits = kwargs["aux_logits"]
kwargs["aux_logits"] = True
kwargs["init_weights"] = False
model = GoogLeNet(**kwargs)
state_dict = load_state_dict_from_url(model_urls["googlenet"], progress=progress)
model.load_state_dict(state_dict)
if not original_aux_logits:
model.aux_logits = False
model.aux1 = None # type: ignore[assignment]
model.aux2 = None # type: ignore[assignment]
return model
return GoogLeNet(**kwargs)