GoogLeNet (Inception)v1论文笔记
GoogLeNet v1
Going deeper with convolutions
这篇论文角度偏向于实际部署,减少计算消耗。
Abstract
提出了inception结构,旨在提升网络内的计算资源利用率。可以在计算开销不变的情况下增加网络的深度和宽度。decisions were based on 赫布法则和对于multi-scale 处理的直觉。
multi-scale:用多种尺度的卷积核并行处理,之后汇总
Introduction
造就图像识别和目标检测快速发展不仅仅是因为更强的硬件、更大的数据集、更大的模型,还有 new ideas、算法和改进的网络结构。
随着移动和嵌入式计算的发展,算法的能力和占用内存变得越来越重要。models准确度稳定并且计算量不算特别庞大(keep a computational budget of 1.5 billion multiply-adds at inference time),models都可以拿来在真实场景中使用。
边缘计算:靠近物或数据源头的一侧
提出了inception结构和inception模块。
Related Work
最近趋势:增加深度和宽度,使用dropout防止过拟合
尽管max pooling 层会丢失准确的空间信息,但网络还是在很多场景中得到了应用
用1*1卷积层+relu降维,可以增加深度和宽度,performance没有显著下降。
Inception思想来源
增加模型的size是一个直截了当的提升性能的方法,包括:增加深度;增加宽度(每层units的数量),前提是能在很多标注好的数据集上训练。
增加size有两个缺点:1.容易过拟合,训练集有限的情况就不适用(例如专家标注的精细的狗种类的数据)2.计算资源消耗大
详细:1.Bigger size typically means a larger number of parameters, which makes the enlarged network more prone to overfitting;the creation of high quality training sets can be tricky and expensive for expert human raters to do so.
2.额外的层算出来参数都是0,浪费(resnet 就是通过identity mapping 显示构造这种关系,通过跳跃连接没有增加额外计算复杂度让网络加深)
要重视计算资源,兼顾计算效率
解决这两个问题的方案:用稀疏连接取代密集连接
参照了生物学Hebbian principle – neurons that fire together, wire together,相关的特征都是同时激活的,并且Arora的理论研究证实过的(论文)
当时硬件不行,稀疏性矩阵不好在GPU上密集矩阵加速计算,因为非均匀稀疏数据结构在现有计算机上处理低效
如前文所说,加大模型size(深度、宽度)会出现两个问题:1.过拟合;2.计算效率下降。
解决方法是用稀疏连接取代密集连接,根据赫布法则,生物系统上的神经元共进共退,都是同时激活的。但是当时的计算机适合密集运算,并不适合稀疏运算。传统的lenet有稀疏性和随机性,alexnet之后为了并行计算提升效率就没了。
所以作者提出问题:能不能利用现有硬件(进行密集矩阵运算)改进模型结构,哪怕只是在卷积层水平改进,从而能利用额外的稀疏性?
inception是利用修改网络结构,用密集的模块(卷积)达到类似稀疏运算的效果(width up)。
但这个architecture只是猜测,成功的原理未知。
Architectural Details
inception结构主要思想:用密集的模块(卷积模块)近似出一个局部最优稀疏结构,然后在空间上重复叠起来。
假设:局部信息由1 1小卷积提取,前面的层提取局部信息,大范围空间信息由大卷积核(3 3,5 *5)提取,后面的提取信息空间比较大。**不同的支路的感受野是不同的
高层特征由高层抽象得到,可解释性会变弱,3 3和5 5卷积在层内比例提高(提取大范围空间信息)**
池化操作在当时的SOTA中很有用,加进模型里有效。
(a)是原始版本的inception module,feature map长宽一样,叠起来,随着层数增加channel会越来愈多,加了池化层之后就更多了。尽管这个结构会满足优化的系数结构,但效率很低,计算量在几个层之内就会爆炸。
(b)是改进后的module(根据层数会调整不同大小的卷积核比例),在3* 3和5* 5卷积之前增加了1* 1卷积(ReLu)来降维,让channel变薄,池化层后面也加了一层1* 1卷积。

综上,inception网络先用普通卷积,之后再堆叠inception模块,偶尔会加入max-pooling层。这种结构可以在增加units的同时不会造成计算复杂度爆炸上涨。1 *1卷积降维用的很频繁,主要是为了减少输出的厚度。另外这种结构符合神经科学认知:多尺度并行分开处理再融合汇总。
这个结构增加了计算资源的利用率,允许增加宽度和深度,而计算不会变得复杂。
GooLeNet
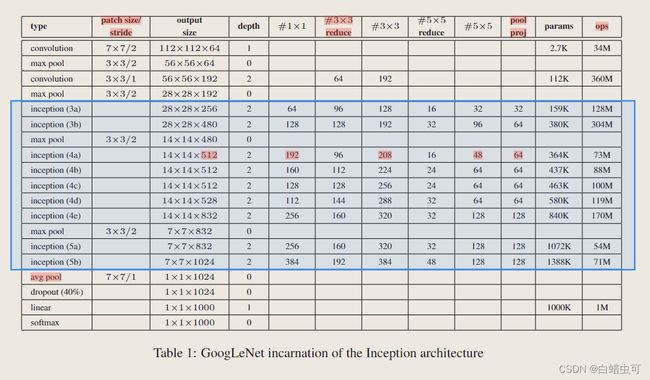
gap:全局平均池化,一个channel用一个平均值代表,生成一维向量,取代全连接层,减少参数量
patch size/stride:卷积核步长 depth代表模块内的层数,
depth:内部层数
#1* 1:1* 1卷积总和
#3×3 reduce and #5×5 reduce:卷积之前1* 1卷积降维后的维度(1*1卷积的个数)
所有reduction/projection layers都用relu。
ops:乘-加法计算量
GoogLeNet共九个inception模块,所有卷积都用Relu。
输入:224* 224 *3 ,mean subtraction,输出feature map大小都是减半关系。
mean subtraction:通过减去数据中每个维度的平均值,将数据的每个维度都以原点为中心进行居中。其python numpy的代码为X -= np.mean(X, axis = 0)。
特点:
1.计算复杂度不高,占用内存小,总共100层,可以在计算资源、内存读写有限的设备上部署
2.使用GAP全局平均池化代替全连接层便于迁移学习并提升了准确率
3.使用dropout
4.还使用了额外的辅助分类器dropout 0.7,loss里这两个层的权重为0.3,目的是让模型能保持一个较大的梯度能训练的动。但效果不显著,后面v2v3都去掉了。



前面用了两个LRN层,alexnet里提出的,效果不明显。
训练方法
1.数据并行,在多个GPU上跑
2.异步随机梯度下降
etc
ILSVRC 2014 Classification Challenge Setup and Results
7个模型集成在不同的GPU上跑,最后对144个patch的分类结果取平均。

Detection Challenge
与rcnn比较:1.结合selective search 和multibox prediction 减少无用的候选框2.没有用框回归,直接对候选框分类3.使用inception模型作为分类器。
精度翻倍。
模型为了比赛提升精度用了很多tricks,现实部署没必要。
trick
短边缩放成256、288、320、352四个尺度,每个尺度裁出(哪边长哪个方向裁剪)三个小图,小图5取个224* 224patch+缩放到224* 224的patch,再做6个镜像翻转
我的总结:
1.稀疏性很重要。
2.可以学习Inception的稀疏结构,通过横向增加层来增加宽度,适应现代硬件的并行计算的特性。
3.在设计模型的时候要注重计算复杂度和内存占用,除了提升精度之外还要注重模型在真实场景的可用性。