非侵入式负荷监测(NILM):分类与回归,单目标与多目标
对NILM的分类、回归问题以及论文里总说的为每个设备训练一个模型总是存疑,最近终于搞懂了,记录一下,如有错误,欢迎指正。
回归与分类
分类
直接识别数据的开关状态,NILM的数据集通常不包含开关信息,所以要先自己给数据集打标签,比如设置一个阈值,某时刻大于多少瓦则认为该设备开启,该时刻设备对应的标签就是1,关闭则为0 。
把聚合数据和上述打好的标签放入模型,最后输出每个设备对应的开关状态(01序列),借用看的一篇论文的图,侵删

回归
上面说过了,数据集一般不包含开关信息,但是包含设备签名(单个设备的消耗),所以可以直接拿来做回归,输入为聚合数据和设备签名,输出为目标设备的消耗情况,这个消耗也可以转换成设备的开关状态,见下图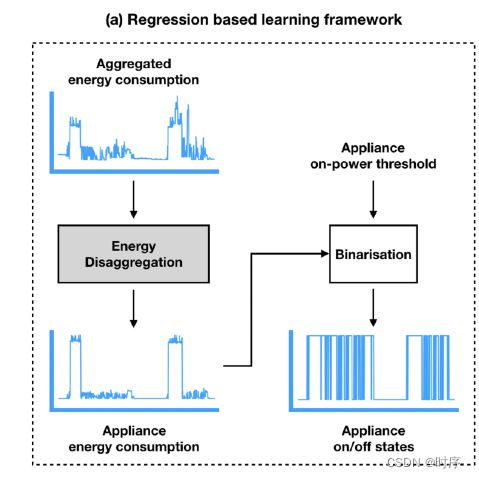
单目标与多目标
单目标
就是为每个目标设备训练一个模型,对应到分类和回归就是多类分类和单目标回归问题。
这样做的好处和坏处都很明显,好处在于每个设备的模型可以相互独立地开发,迁移性也好一点。坏处就是需要大量的时间和数据去训练多个模型,还可能会显著低估或高估总功耗,因为没有最小化总功耗和每个设备的预测个别功耗之和之间的差异,而且这样做各设备之间是独立的,无法利用它们互相之间的联系。
多目标
意在建立一个通用模型,同时识别或分解多个设备,对应多标签分类和多目标回归。
听起来显然是这种方法更好,只训练一个模型需要的数据量和时间少多了,但现在用的最多的反而还是上面那种方法,为什么呢?因为每个家电的模式和行为不同,因此很难创建一个通用的模型,能够同时分解所有家电的总功耗,设备相互之间差异很大,同一个设备受天气、使用习惯等影响也会导致签名发生改变,同类设备不同品牌的签名差距可能很大…种种阻碍导致这种方法难以普及,但是也有做的不错的成绩,见参考文献。
参考文献
【1】Kaselimi, Maria, et al. “Towards Trustworthy Energy Disaggregation: A Review of Challenges, Methods, and Perspectives for Non-Intrusive Load Monitoring.” Sensors 22.15 (2022): 5872.
【2】Faustine, Anthony, et al. “UNet-NILM: A deep neural network for multi-tasks appliances state detection and power estimation in NILM.” Proceedings of the 5th International Workshop on Non-Intrusive Load Monitoring. 2020.