训练过程可视化
训练的目的是为了迭代出好的参数(自动)、超参数(人工)。在训练的过程中需要将注意力放到三个要素train_loss, train_acc, test_acc。如果能动态的观察训练过程中三个要素的变化,从宏观视角更本质的把握训练过程,则更利于超参数(人工)的选取和debug训练过程中出现的问题。
在实际中以epoch(训练轮数)横坐标,上面三个值为纵坐标进行描点画图,这里面涉及到两个通用的类Animator、Accumulator,二者是配合使用,下面具体分析这两个类的代码细节和用法。
Accumulator
class Accumulator:
"""For accumulating sums over `n` variables."""
def __init__(self, n):
"""Defined in :numref:`sec_softmax_scratch`"""
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]注意:这里add在代入参数的时候,要写成metric.add(1, 2)形式,不能写成metric.add((1, 2)).
In [26]: metric = Accumulator(2)
In [27]: metric
Out[27]: <__main__.Accumulator at 0x7f2e4827f820>
In [28]: metric[0]
Out[41]: 0.0
metric[1]
Out[44]: 0.0
In [29]: metric.add(1, 2)
metric[0]
Out[46]: 1.0
metric[1]
Out[47]: 2.0
zip() 函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
我们可以使用 list() 转换来输出列表。
如果各个迭代器的元素个数不一致,则返回列表长度与最短的对象相同,利用 * 号操作符,可以将元组解压为列表。
a = [1,2,3]
b = [4,5,6]
zipped = zip(a,b)
# 返回一个对象
zipped
# list() 转换为列表
list(zipped)
[(1, 4), (2, 5), (3, 6)]
# 再次观察zipped
Out[31]: []
# 说明和迭代器一样,迭代一个,少一个元素
# 使用next再次验证
zipped = zip(a,b)
next(zipped)
Out[34]: (1, 4)
next(zipped)
Out[35]: (2, 5)
next(zipped)
Out[36]: (3, 6) Accumulator
class Animator:
"""For plotting data in animation."""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
"""Defined in :numref:`sec_softmax_scratch`"""
# Incrementally plot multiple lines
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# Use a lambda function to capture arguments
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# Add multiple data points into the figure
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)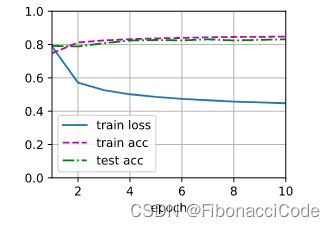
结合上图,这里仅关注 Animator的使用,而忽视其它细节:
- figsize=(3.5, 2.5):视觉上框图的长和宽,可以在此基础上适当调整;
- xlabel='epoch':x坐标轴的名称;
- ylabel='epoch':y坐标轴的名称(对于多个y值的,名称可以不标);
- xlim=[1, num_epochs]:x轴数值范围;
- ylim=[0.3, 0.9]:y轴数值范围;
- legend=['train loss', 'train acc', 'test acc']:图例,这里的顺序和add(self, x, y)
 向量的数值一致(元素个数和意义都一致);
向量的数值一致(元素个数和意义都一致); - animator.add(epoch + 1, train_metrics + (test_acc,)):每次描 len(y) 个点;
train_plt函数
reduce_sum = lambda x, *args, **kwargs: x.sum(*args, **kwargs)
astype = lambda x, *args, **kwargs: x.type(*args, **kwargs)
def accuracy(y_hat, y):
"""Compute the number of correct predictions.
Defined in :numref:`sec_softmax_scratch`"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = d2l.argmax(y_hat, axis=1)
cmp = d2l.astype(y_hat, y.dtype) == y
return float(reduce_sum(astype(cmp, y.dtype)))
def evaluate_loss(model, train_iter):
# Set the model to evaluation mode
if isinstance(model, torch.nn.Module):
model.eval()
metric = Accumulator(2)
for X, y in train_iter:
# Compute gradients and update parameters
y_hat = model(X)
l = loss(y_hat, y)
metric.add(float(l.sum()), y.numel())
return metric[0] / metric[1]
def evaluate_accuracy(net, data_iter):
"""Compute the accuracy for a model on a dataset.
Defined in :numref:`sec_softmax_scratch`"""
if isinstance(net, torch.nn.Module):
net.eval() # Set the model to evaluation mode
metric = Accumulator(2) # No. of correct predictions, no. of predictions
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), d2l.size(y))
return metric[0] / metric[1]
def train_plt(animator, idx, model, train_iter):
train_loss = evaluate_loss(model, train_iter)
train_acc = evaluate_accuracy(model, train_iter)
test_acc = evaluate_accuracy(model, test_iter)
animator.add(idx, (train_loss, train_acc, test_acc))
参考资料:
1. 3.6. softmax回归的从零开始实现 — 动手学深度学习 2.0.0 documentation