DFAnet:Deep Feature Aggregation for Real-time Semantic Segmentation自己翻译的
DFAnet:Deep Feature Aggregation for Real-time Semantic Segmentation
原始论文Li H, Xiong P, Fan H, et al. Dfanet: Deep feature aggregation for real-time semantic segmentation[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2019: 9522-9531.
Abstract
一、从单一的轻量级主干出发,通过子网络和子级连接分别聚合识别特征
二、基于多尺度特征传播,DFANet极大的减少了参数数量,同时保持了有效的感受野,并且增强了模型的学习能力
三、在数据集Cityscapes 和 CamVid 进行测试,与state-of-art方法比较,以少于8倍的计算量和两倍快的速度提供了相当的准确率
四、在Cityscapes上实现了70.3%的平均IOU,同时只有1.7GFLOPS,在一块NVIDIA Titan X上达到了160FPS,当图片分辨率更高时,能以3.4GFLOPs达到71.3%的平均IOU
1 Introduction
语义分割:目的是给图片中所有的像素赋予密集标签
之前的语义分割方法:
1、A deep convolutional encoder-decoder architecture for image segmentation.
2、Speeding up semantic segmentation for autonomous driving
3、Real-time semantic image segmentation via spatial sparsity.
4、Bisenet: Bilateral segmentation network for real-time semantic segmentation
5、Icnet for real-time semantic segmentation on high-resolution images.
6、Enet: A deep neural network architecture for real-time semantic segmentation.
动机(motivation):在高分辨率地形图上的操作在U型结构中花费了大量的时间,一些工作通过限制输入图片的size来减小计算复杂度,或者通过减少冗余通道,虽然有效,但是会损失边界和小物体周围的空间细节,同时浅层网络也会削弱特征识别能力
其他方法采用多分支框架结合空间细节和上下文信息。然而,在高分辨率图像上的额外分支限制了速度,分支之间的相互独立性限制了这些方法的模型学习能力。
在主流的语义分割架构中,采用金字塔式的特征组合步骤,如空间金字塔池[34][5],利用高层上下文来丰富特征,同时导致计算成本的急剧增加。
此外,传统方法通常从单个路径体系结构的最终输出中丰富特征映射。在这种设计中,高层上下文缺乏与前面的层特征的结合,而前面的层也保留了网络路径中的空间细节和语义信息。
为了同时增加模型的学习能力和感受野,特征重复利用是一个非常自然的想法,这促使我们去寻找一个轻量级的方法,将多层级上下文合并到编码特征中
我们的工作:在我们的模型中部署了两个策略去实现层级间的特征聚合,第一,我们重用从主干提取的高级特征来弥补语义信息和结构细节间的差距;第二,我们结合网络结构处理路径不同阶段的特征来增强特征的表达能力。
DFANet包含三个部分:
轻量级主干、子网络聚合和子级聚合模块。
轻量级主干:由于depthwise separable卷积被证明在实时推断中是最有效的,因此我们修改Xception网络作为主干网络,为了追求更好的准确性,我们在主干网络的尾部附加了一个全连接的注意模块,以保留最大的接受域。
子网络聚合:子网络聚合的重点是将前一个主干的高级特征映射上采样到下一个主干的输入,以细化预测结果。
子级聚合模块:子阶段聚合通过“粗”部分和“细”部分组装对应阶段之间的特征表示。
在这三个模块之后,采用卷积和双线性上采样操作组成的小型解码器,将各个阶段的输出结合起来,得到由粗到精的分割结果。
主要贡献:
1、创造了实时语义分割计算量的最低记录,与已存在的最好的网络相比,有少于8倍的FLOPs并且快两倍
2、提出了一个全新的分割网络结构,有多个相互连接的编码流,以纳入高层次的上下文编码的特点。
3、的结构提供了一种更好的方法来最大限度地利用多尺度接受域,并在计算量略有增加的情况下多次细化高级特性。
4、修改了Xception中枢,增加了FC的注意层,以增加接收区,而不增加额外的运算。
2 Related work
实时语义分割:SegNet利用一个小的架构和池化指示策略来减少网络参数;ENet考虑减少下采样次数,以追求一个非常紧凑的框架。由于它忽略了模型的最后阶段,所以该模型的接受域太小,无法正确地分割较大的对象;ESPNet利用新的空间金字塔模块;ICNet使用多尺度输入图片和级连网络来增加有效性;BiSeNet引入了空间路径和语义路径来减少计算量;我们在特征空间中增强了单一模型的能力来保留更多的细节信息
深度分离卷积:(深度卷积紧接着点卷积)此操作减少了计算成本和参数数量,同时保持了类似(或稍好一些)的性能。
高层特征:分割任务中的关键问题是接受域和分类能力,在一般的编码器-解码器结构中,编码器输出的高级特征描述了输入图像的语义信息。PSPNet、DeepLab series、PAN应用一个额外的操作来结合更多的上下文信息和多尺度特征表示。空间金字塔汇聚已经被广泛地应用于为整体场景解释提供良好的描述符,特别是对多尺度的各种对象。这些模型在多个基准上显示了高质量的分割结果,但通常需要大量的计算资源。
上下文编码:SE-Net通过对信道信息的挖掘来学习信道级的注意,在图像分类方面取得了很好的效果,注意机制成为深度神经网络[3]的有力工具。可以将其视为一种信道选择,以改进模块的特征表示。EncNet[32][20][6]引入了上下文编码来增强基于编码语义的逐像素预测。在本文中,我们还提出了一个全连接模块来提高骨干性能,这对计算影响很小
特征聚合:传统方法采用单路编解码器网络来解决像素间的预测问题。随着网络深度的增加,如何在块与块之间聚合特征值得进一步关注。RefineNet[17]不是简单的跳过连接设计,而是在编码器和解码器之间的每个上采样阶段引入一个复杂的细化模块来提取多尺度特征。另一种聚合方法是实现密集连接。最近在[13]中提出了密集连接的概念用于图像分类,并将其扩展到[14][28]中的语义分割。DLA[31]扩展了该方法,开发了更深层次的聚合结构,增强了特征表示能力。
3 Deep Feature Aggregation Network
在实时语义分割任务中应用最近的语义分割方法时,我们首先对计算量进行观察和分析,这促使我们的聚合策略需要结合特征提取网络的不同深度位置的细节和空间信息,DFANet结构如下所示
###3.1 观察
首先简要看一下分割网络的结构
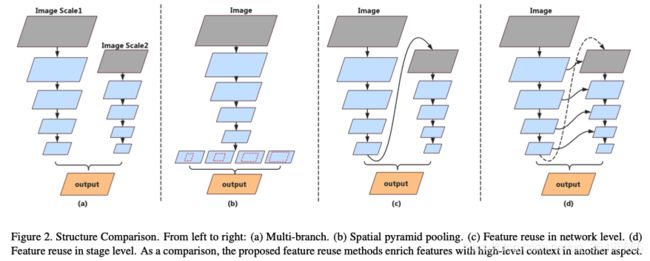
对于实时推理,[33][29]应用多分枝来实现多尺度提取并保证图像空间细节,如BiSeNet[29]提出用浅层网络处理高分辨率图片,同时利用快速向下采样的深度网络来平衡分类能力和接受野的关系,这种架构如图2(a)所示。这种方法的缺点非常明显,这些模型缺乏对来自并行分支的高级特征的处理,因为它仅仅实现了卷积层来融合特征,此外平行分支间的特征缺乏交流,而且在高分辨率图片中额外的分支会限制速度的提升。
在语义分割任务中,空间金字塔模块是一个处理高层特征常用的方法(图2b)。空间金字塔的能力是提取高层语义上下文并增加感受野。但是空间金字塔通常很消耗时间。
通过上面方法的启发,首先用上采样网络的输出并用一个子网络来细化特征图来替换高层操作,如图2c所示。与空间金字塔模块不同,特征映射在更大的分辨率上进行细化,同时学习子像素的细节。然而,当整体架构变深时,由于特征流是单路径的,高维特征和接受域往往会出现精度损失。
因此,我们提出了阶段级方法来传递低层特征和空间信息以进行语义理解,如图2d所示。因为这些子网络具有相似的结构,因此可以通过将具有相同分辨率的层连接起来来生成多级上下文,从而产生阶段级细化。我们提出的深度特征聚合网络旨在利用网络级和阶段级的特征。
3.2深度特征聚合
我们的关注点是融合网络中不同深度的特征,我们的聚合策略由子网络聚合和子阶段聚合。
子网络聚合:子网络聚合在网络层级实现高层特征的结合。根据上面的分析,我们通过主干网络的堆叠来实现我们的架构,即将前面主干网络的输出输入到下一个主干网络。另一方面,子网络聚合可以被看为一个细化处理。主干网络定义为: y = Φ ( x ) y=\Phi(x) y=Φ(x) ,编码输出 Φ n \Phi_{n} Φn是编码 Φ n + 1 \Phi_{n+1} Φn+1的输入,因此子网络聚合可以表示为:
Y = Φ n ( Φ n − 1 ( … Φ 1 ( X ) ) ) Y=\Phi_{n}\left(\Phi_{n-1}\left(\ldots \Phi_{1}(X)\right)\right) Y=Φn(Φn−1(…Φ1(X)))
相似的想法在[21]中也有介绍,网络结构由堆叠的编码-解码器构成的沙漏网络。子网络聚合允许这些高层特征被再次处理来进一步评估和重新评估高阶空间关系。
子阶段聚合:子阶段聚合的关注点是融合多个网络间阶段级语义和空间信息,随着网络深度的增加,空间细节的精度会有损失。通常的方法,像U型结构在解码器模块中实现跳跃连接来恢复图像细节。然而,编码器模块越深越会损失低层特征和空间信息,无法对大尺度的各种对象和精确的结构边缘进行判断。并行分支设计采用原始分辨率和降低分辨率作为输入,输出是大规模分支和小规模分支结果的融合,而这种设计缺乏并行分支之间的信息通信。
我们的子阶段聚合通过编码周期来合并特征。我们在相同深度的子网络中进行不同阶段的融合。前一个子网络中某一阶段的输出贡献给下一个子网络相应阶段位置的输入。
对于一个主干 Φ n ( x ) \Phi_{n}(x) Φn(x),一个阶段处理可以被定义为 ϕ n i \phi_{n}^{i} ϕni,那么之前主干网络的阶段是 ϕ n − 1 i \phi_{n-1}^{i} ϕn−1i, i i i是阶段的索引,那么子阶段聚合可以被表示为:
x n i = { x n i − 1 + ϕ n i ( x n i − 1 ) if n = 1 [ x n i − 1 , x n − 1 i ] + ϕ n i ( [ x n i − 1 , x n − 1 i ] ) otherwise x_{n}^{i}=\left\{\begin{array}{ll}{x_{n}^{i-1}+\phi_{n}^{i}\left(x_{n}^{i-1}\right)} & {\text { if } n=1} \\ {\left[x_{n}^{i-1}, x_{n-1}^{i}\right]+\phi_{n}^{i}\left(\left[x_{n}^{i-1}, x_{n-1}^{i}\right]\right)} & {\text { otherwise }}\end{array}\right. xni={xni−1+ϕni(xni−1)[xni−1,xn−1i]+ϕni([xni−1,xn−1i]) if n=1 otherwise 其中
x n − 1 i = x n − 1 i − 1 + ϕ n − 1 i ( x n − 1 i − 1 ) x_{n-1}^{i}=x_{n-1}^{i-1}+\phi_{n-1}^{i}\left(x_{n-1}^{i-1}\right) xn−1i=xn−1i−1+ϕn−1i(xn−1i−1)
传统的方法是学习对于 x n i − 1 x_{n}^{i-1} xni−1学习一个映射 F ( x ) + x \mathcal{F}(x)+x F(x)+x,在我们的方法中,子阶段聚合在每个阶段开始时学习一个 [ x n i − 1 , x n − 1 i ] \left[x_{n}^{i-1}, x_{n-1}^{i}\right] [xni−1,xn−1i]的残差方程
当 n > 1 n>1 n>1时,在第 n n n个网络的第 i i i个阶段的输入由第 n − 1 n-1 n−1个网络的第 i i i个阶段的输出和第 n n n个网络的第 i − 1 i-1 i−1个阶段输出决定,然后第 i i i个阶段学习一个 [ x n i − 1 , x n − 1 i ] \left[x_{n}^{i-1}, x_{n-1}^{i}\right] [xni−1,xn−1i]的残差表示, x n i − 1 x_{n}^{i-1} xni−1和 x n − 1 i x_{n-1}^{i} xn−1i有相同的resolution,利用连接操作实现特征融合。
我们保持特征总是从高分辨率流向低分辨率。我们的公式不仅学习了第n个特征图的新映射,而且保留了第n-1个特征图的特征和接受域。信息流可以通过多个网络进行传输。
3.3 网络架构
完整的网络结构如图3所示
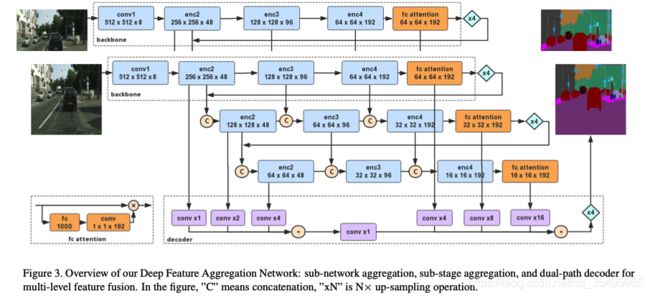
我们的语义分割网络可以被看作一个编码-解码结构,正如上面描述,编码器是由3个Xception主干组成的聚合,由子网络聚合和子级聚合方法组成。对于实时推断,我们不过多的关注解码器。解码器被设计为一个有效的上采样模块来融合低级和高级特征,为了便于实现我们的聚合策略,我们的子网络由一个具有双线性上采样的主干作为一个朴素解码器来实现。所有这些主干具有相同的结构,并以相同的预先训练过的权重进行初始化。
主干:基础主干是为了分割任务对轻量级Xception模型进行过少量修改的模型,下一部分讨论网络配置。对于语义分割,不仅需要提供密集特征表示,如何获得有效的语义上下文信息也是一个问题。因此,我们保留了来自ImageNet预处理的全连接层,以增强语义提取。在分类任务中,全连接(FC)层之后是全局池化层,从而得到最终的概率向量。由于分类任务数据集[15]相比分割任务数据集[10][36]提供了大量的类别,因此从ImageNet预处理的全连接层中提取类别信息比从分割数据集中提取更有效。我们在全连接层后应用1X1卷积层以匹配来自Xception主干的特征图。然后将N×C×1×1的编码向量按信道的方式与原始提取的特征相乘。
解码器:在图3中标明了我们的解码模块,对于实时推断,我们不过多的关注解码器模块的实际,根据DeepLabV3+[7]研究的发现,不是所有的阶段特征对于解码模块都是必要的。因此我们直接融合高层和低层特征,由于我们的编码器由三个主干组成,我们首先融合从三个主干的下层结构得到的高层特征,然后将高阶特征以4倍的比例进行双线性上采样,并分别融合来自具有相同空间分辨率的各骨干网的低阶信息。然后将高层次的特征和低层次的细节加在一起,并以4倍的倍数向上采样以做出最终的预测。在解码模块,我们只利用了很少的卷积运算来减少通道数
4 Experiments
我们在两个有挑战性的基础数据集上评估我们提出的网络:Citycapes和CamVid。将这两个数据集中图片的分辨率分别提高到 2048X1023 和 960X720,这对于实时语义分割具有很大的挑战性。接下来,我们首先探究架构的有效性,然后与现有的实时分割算法进行比较在Cityscapes和CamVid上进行精度和速度的结果。
下面提及到的网络遵循相同的训练策略,使用mini-batch SGD的训练方法,batch_size为48,momentum为0.9,weight decay为 1 e − 5 1 e-5 1e−5。基础学习率设为 2 e − 1 2 e-1 2e−1,应用‘poly’学习率更新策略,即基础学习率乘以 ( 1 − iter m a x − i ter ) power \left(1-\frac{\text { iter }}{m a x_{-i} \text { ter }}\right)^{\text {power }} (1−max−i ter iter )power 其中power为0.9。将类别上每个像素的交叉熵误差作为我们的损失函数。数据扩充包括均值减法、随机水平翻转、随机调整大小(范围为[0.75,1.75])和随机裁剪成固定大小进行训练。
4.1 DFA架构的分析
首先在Cityscapes数据集上进行定性和定量分析。Cityscapes数据集是由一组大型的,不同的立体声视频序列记录在50个不同的城市的街道上,包含30个类别,其中19个被考虑用于训练和评估。数据集包含5000张精细注释图像和19998张粗注释图像,均具有2048×1024的高分辨率。按照Cityscapes的标准设置,将经过精细注释的图像分别分为包含2979、500和1525张图像的训练、验证和测试集。我们只在训练过程中使用带注释的图像,并在40K迭代后停止训练过程。
模型表现评估是在验证集上做的,为了公平的进行比较,我们在1024*1024裁剪尺度上进行控制实验。在这个过程中,我们不使用任何测试技巧,如多尺度或多裁剪。对于定量评估,利用mIoU和FLOPs分别评估准确率和计算复杂度
4.1.1 轻量级架构网络
如前面所述,主干网络是模型加速的主要限制之一,然而,太小的主干网络会导致严重的分割精度下降。Xception是一种轻量级架构,能够很好的平衡速度和准确性。我们以更少的计算复杂度实现了两个修改的Xception网络(Xception A, Xception B),以追求我们所提出方法的推理速度。表1总结了这两个模型的详细架构。

Xception网络在ImageNet-1000数据集上进行预训练,与[15][7]的训练协议类似。具体来说,我们采用Nesterov动量优化器,动量= 0.9,初始学习率= 0.3,权值衰减4e−5。经过30个epoch的训练,我们设置学习率为0.03,再训练30个epoch。我们的批量大小是256,图像大小是224×224。调整超参数并不困难,因为我们的目标是在ImageNet上对模型进行语义分割的预训练。
我们在Cityscapes数据集上评估我们修改的Xception网络,为了使预测的分辨率和原始图片相同,特征通过16X因子被双线性上采样。作为对照,我们复制了ResNet50,它采用扩张卷积得到1/16下采样。可以看到,当用Xception A代替ResNet-50,分割准确率从68.3%下降到59.2%。然而在执行ASPP[5]时,性能下降较小(ResNet-50 + ASPP→72.1% Xception A + ASPP的67.1%),证明了ASPP模块在轻量级骨干网上的有效性。通过ASPP模块,XceptionA达到了67.1% mIoU,与ResNet50的68.3%相当,但前者的计算复杂度远低于后者。这促使我们在资源约束下应用轻量级模型和高级上下文模块进行语义分割。
我们也考虑减少输入图片的分辨率来减少计算。在以前的方法中,研究人员尝试使用低分辨率的输入来实现实时推理。但是,当缩放比例为0.25时,相应的mIoU低得令人无法忍受。虽然可以用更小的尺寸进行推断,但是原始模型的FLOPs仍然明显大于小的主干网络(9.3G的ResNet-50→1.6G的Xception A)。当有ASPP模块紧接着时,与传统的ResNet-50相比,Xception A容易获得更好的精度。即使应用在另一个较小的主干Xception B上,其准确度也可与之相媲美,而且FLOPs只有一半。尽管ASPP模块很有用,但其计算复杂度明显过高。全局池化注意力模块作为一个替换方案,我们评估了3.3节中介绍的FC注意力模块的影响。如表2所示

对于Xception A和B, FC attention可以获得4 - 6%的准确率提高,值得注意的是计算量几乎不变。FC attention为高维上下文的效果提供了证据,实现了一种简单有效的全局融合图像上下文信息的方法。在接下来的实验中,我们以主干A和B为基本单元来评价我们的DFANet的性能。
4.1.2 特征聚合
这一部分,我们研究聚合策略的有效性。我们复制主干来测试在Cityscapes验证集上的表现。如表3所示

基于BackboneA,采用一次子网络聚合,分割准确率由65.4%提高到66.3%。当应用两次聚合(‘×3’)时,准确率略有下降,从66.3%下降到65.1%。我们认为原因是此时的感受野早已超过了输入图片,会引入噪声。当输出被直接上采样到原始大小时,噪声也被放大了。虽然带来了更多的细节,但也带来了负干扰。当聚合数为“×4”时,我们在精度上没有得到很大的提高。由于输入分辨率为1024×1024时,最终输出分辨率为8×8,特征量太小,无法进行类别分类。
图4显示了三个主干堆叠的结果

可以看到,第一个主干的预测存在大量的噪声,然后在下一阶段通过空间细节使预测变得更加平滑。这一结果证明了接受域的扩大和全局上下文的引入是分阶段学习的结果。通过第三个聚合主干进行处理,结果中的结构细节变得更加精确。第三次细化后的预测结果将细节信息和上下文信息结合起来。我们认为,子级聚合带来了多尺度信息的组合。在级联模型的基础上,学习更多的判别特征,逐步处理子像素学习。
4.1.3 DFA整体架构
最后,对提出的DFA体系结构进行了整体的结果分析。在第3.3节中,我们的解码器模块被设计为高效、简单,可以将高级和低级功能结合起来。与直接上采样不同,解码器模块中的卷积进一步平滑了合并结果。聚合编码器的性能如表4所示。
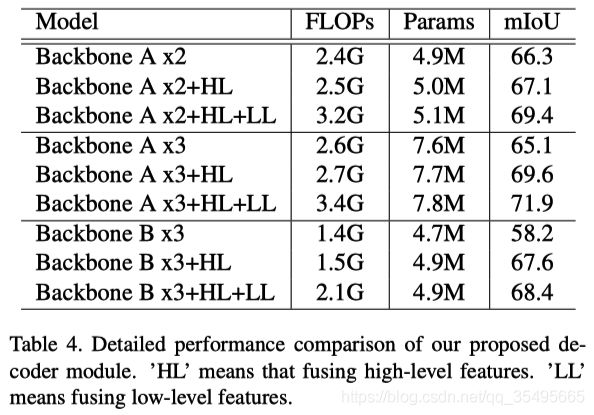
虽然BackboneA x3的性能略低于BackboneA x2,但最终的聚合编码器由三个主干网组成,如图3所示。基于解码操作,BackboneA x3的准确率高于Backbone x2.与前面的结论一样,也说明了细节是在substage 3中学习的,而噪声是在不同尺度输出的组合中去除的。
因为我们的聚合方法可以提供密集的特性,所以根据推理速度的要求我们不追求复杂的解码器模块设计。基于这两种类型的骨架,所有的高级和低级解码器都进一步提高了性能,计算量略有增加。综合以上分析,得出在Cityscapes 验证集的最终结果为71.9% mIoU,仅3.4 GFLOPs。此外,整个基于B主干网架构的计算量减少到2.1 GFLOPs,但仍达到68.4%的mIoU。
4.2 速度和准确率比较
所有的速度比较都在表5中给出了
 速度是算法的重要因素,我们尝试在相同的状态下测试我们的模型,并进行比较。本文利用网络推理时间对其有效性进行了研究。所有的实验都是在单片Titan X GPU的虚拟机上进行的。对于已提出的方法,我们使用性能最好的网络报告运行Cityscapes所有测试图像的平均时间。表中还列出了输入图像的分辨率以供比较。在这个过程中,我们不使用任何测试增强。
速度是算法的重要因素,我们尝试在相同的状态下测试我们的模型,并进行比较。本文利用网络推理时间对其有效性进行了研究。所有的实验都是在单片Titan X GPU的虚拟机上进行的。对于已提出的方法,我们使用性能最好的网络报告运行Cityscapes所有测试图像的平均时间。表中还列出了输入图像的分辨率以供比较。在这个过程中,我们不使用任何测试增强。
可以看到,我们提出的方法的推理速度明显优于最先进的推理方法,同时由于该方法具有简单、高效的推理过程,因此在精度上保持了竞争力。该方法的基线在Cityscapes测试集上达到mIoU 71.3%,推理速度为100 FPS。我们从输入尺寸和通道尺寸两个方面对该方法进行了扩展。当主链模型简化后,DFANet的精度性能下降到67.1%,推理速度仍然为120 FPS,与之前的技术水平(68.4%的BiSeNet[29])相当。然而,当输入图像的高度被降采样到一半时,DFANet A的FLOPs降到了1.7G,但其精度仍足以优于现有的几种方法。我们的方法的最快设置运行速度为160帧/秒,mIoU达到70.3%,而之前的最快结果[22]只有135帧/秒,mIoU也只有57%。与之前的最先进的模型[29]相比,我们提出的DFANet A, B, A’具有1.38×,1.65×和2.21×的速度提升,只有1/4,1/7和1/8的FLOPs,同时甚至有更好的分割精度。
4.3 在其他数据集上的比较
我们也在CamVid数据集上评估了我们的DFANet,CamVid包含从视频序列中提取的图像,分辨率高达960×720。它总共包含701张图像,其中367张用于培训,101张用于验证,233张用于测试。我们采用与[23]相同的设置。用于训练和评价的图像分辨率均为960×720。结果如表6所示

DFANets获得了比其他方法更快的推断速度,120帧/秒和160帧/秒的高分辨率,比最先进的方法[33]略差。
5 Conclusion
在本文中,我们提出了一种深度特征聚合来解决高分辨率图像的实时语义分割问题。聚合策略连接一系列卷积层,在不进行任何专门设计的操作的情况下,有效地细化高级和低级特征。通过在Cityscapes和CamVid数据集上的分析和定量实验,验证了该方法的有效性。
References
[1] Vijay Badrinarayanan, Alex Kendall, and Roberto Cipolla.
Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE transactions on pattern analysis and machine intelligence, 39(12):2481–2495, 2017.
[2] Gabriel J. Brostow, Jamie Shotton, Julien Fauqueur, and Roberto Cipolla. Segmentation and recognition using structure from motion point clouds. In ECCV (1), pages 44–57, 2008.
[3] Long Chen, Hanwang Zhang, Jun Xiao, Liqiang Nie, Jian Shao, Wei Liu, and Tat-Seng Chua. Sca-cnn: Spatial and channel-wise attention in convolutional networks for image captioning. arXiv preprint arXiv:1611.05594, 2016.
[4] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos, Kevin Murphy, and Alan L Yuille. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE transactions on pattern analysis and machine intelligence, 40(4):834–848, 2018.
[5] Liang-Chieh Chen, George Papandreou, Florian Schroff, and Hartwig Adam. Rethinking atrous convolution for semantic image segmentation. arXiv preprint arXiv:1706.05587, 2017.
[6] Liang-Chieh Chen, Yi Yang, Jiang Wang, Wei Xu, and Alan L Yuille. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3640–3649, 2016.
[7] Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. arXiv preprint arXiv:1802.02611, 2018.
[8] Franc¸ois Chollet. Xception: Deep learning with depthwise separable convolutions. arXiv preprint, pages 1610–02357, 2017.
[9] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe Franke, Stefan Roth, and Bernt Schiele. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3213–3223, 2016.
[10] Mark Everingham, Luc Van Gool, Christopher KI Williams, John Winn, and Andrew Zisserman. The pascal visual object classes (voc) challenge. International journal of computer vision, 88(2):303–338, 2010.
[11] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016.
[12] Jie Hu, Li Shen, and Gang Sun. Squeeze-and-excitation networks. arXiv preprint arXiv:1709.01507, 2017.
[13] Gao Huang, Zhuang Liu, Kilian Q Weinberger, and Laurens van der Maaten. Densely connected convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition, volume 1, page 3, 2017.
[14] Simon J´egou, Michal Drozdzal, David Vazquez, Adriana Romero, and Yoshua Bengio. The one hundred layers
tiramisu: Fully convolutional densenets for semantic segmentation. In Computer Vision and Pattern Recognition Workshops (CVPRW), 2017 IEEE Conference on, pages 1175–1183. IEEE, 2017.
[15] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton. Imagenet classification with deep convolutional neural networks. In Advances in neural information processing systems, pages 1097–1105, 2012.
[16] Hanchao Li, Pengfei Xiong, Jie An, and Lingxue Wang.
Pyramid attention network for semantic segmentation. arXiv preprint arXiv:1805.10180, 2018.
[17] Guosheng Lin, Anton Milan, Chunhua Shen, and Ian Reid. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[18] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014.
[19] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 3431–3440, 2015.
[20] Volodymyr Mnih, Nicolas Heess, Alex Graves, et al. Recurrent models of visual attention. In Advances in neural information processing systems, pages 2204–2212, 2014.
[21] Alejandro Newell, Kaiyu Yang, and Jia Deng. Stacked hourglass networks for human pose estimation. In European Conference on Computer Vision, pages 483–499. Springer, 2016.
[22] Adam Paszke, Abhishek Chaurasia, Sangpil Kim, and Eugenio Culurciello. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv preprint arXiv:1606.02147, 2016.
[23] Philip H. S. Torr Paul Sturgess, Karteek Alahari. Combining appearance and structure from motion features for road scene understanding. In BMVC, 2009.
[24] Tobias Pohlen, Alexander Hermans, Markus Mathias, and Bastian Leibe. Full-resolution residual networks for semantic segmentation in street scenes. arXiv preprint, 2017.
[25] Michael Treml, Jos´e Arjona-Medina, Thomas Unterthiner, Rupesh Durgesh, Felix Friedmann, Peter Schuberth, Andreas Mayr, Martin Heusel, Markus Hofmarcher, Michael Widrich, et al. Speeding up semantic segmentation for autonomous driving. In MLITS, NIPS Workshop, 2016.
[26] Shinji Watanabe, Takaaki Hori, Shigeki Karita, Tomoki Hayashi, Jiro Nishitoba, Yuya Unno, Nelson Enrique Yalta Soplin, Jahn Heymann, Matthew Wiesner, Nanxin Chen, et al. Espnet: End-to-end speech processing toolkit. arXiv preprint arXiv:1804.00015, 2018.
[27] Zifeng Wu, Chunhua Shen, and Anton van den Hengel. Realtime semantic image segmentation via spatial sparsity. arXiv preprint arXiv:1712.00213, 2017.
[28] Maoke Yang, Kun Yu, Chi Zhang, Zhiwei Li, and Kuiyuan Yang. Denseaspp for semantic segmentation in street scenes.
[29] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. Bisenet: Bilateral segmentation
9 network for real-time semantic segmentation. arXiv preprint arXiv:1808.00897, 2018.
[30] Changqian Yu, Jingbo Wang, Chao Peng, Changxin Gao, Gang Yu, and Nong Sang. Learning a discriminative feature network for semantic segmentation. arXiv preprint arXiv:1804.09337, 2018.
[31] Fisher Yu, Dequan Wang, Evan Shelhamer, and Trevor Darrell. Deep layer aggregation. arXiv preprint arXiv:1707.06484, 2017.
[32] Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, and Amit Agrawal. Context encoding for semantic segmentation. arXiv preprint arXiv:1803.08904, 2018.
[33] Hengshuang Zhao, Xiaojuan Qi, Xiaoyong Shen, Jianping Shi, and Jiaya Jia. Icnet for real-time semantic segmentation on high-resolution images. arXiv preprint arXiv:1704.08545, 2017.
[34] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. In IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), pages 2881–2890, 2017.
[35] Shuai Zheng, Sadeep Jayasumana, Bernardino RomeraParedes, Vibhav Vineet, Zhizhong Su, Dalong Du, Chang Huang, and Philip HS Torr. Conditional random fields as recurrent neural networks. In Proceedings of the IEEE International Conference on Computer Vision, pages 1529–1537, 2015.
[36] Bolei Zhou, Hang Zhao, Xavier Puig, Sanja Fidler, Adela Barriuso, and Antonio Torralba. Semantic understanding of scenes through the ade20k dataset. arXiv preprint arXiv:1608.05442, 2016.