李宏毅2022机器学习HW4解析
准备工作
作业四是speaker Identification(语者识别),需要将助教代码+数据集放置于同一目录下,记得解压数据集。关注本公众号,可获得代码和数据集(文末有方法)。
Kaggle提交地址
https://www.kaggle.com/competitions/ml2022spring-hw4,提交结果可能需要科学上网,想讨论的可进QQ群:156013866。
Simple Baseline (acc>0.60824)
方法:使用TransformerEncoder层,其中TransformerEncoderLayer的层数是2(num_layers=2),,运行代码出现output.csv文件,将其提交到kaggle上得到分数:0.65775。
# __init__中启用encoderself.encoder = nn.TransformerEncoder(self.encoder_layer, num_layers=2)# forward中使用encoderout = self.encoder(out)

Medium Baseline (acc>0.70375)
方法:维度更改+使用TransformerEncoder层+Dropout+全连接层修改+Train longer。助教代码中的d_model维度是40,而我们需要预测的n_spks维度是600,维度相差过大,需要将d_model调整为224,经测试d_model过大过小都不好。TransformerEncoder使用3层TransformerEncoderLayer,dropout=0.2。全连接层从2层改为1层,并加入BatchNorm。训练step由70000改为100000。运行代码,提交得到kaggle分数:0.74025。
def __init__(self, d_model=224, n_spks=600, dropout=0.2):super().__init__()self.prenet = nn.Linear(40, d_model)self.encoder_layer = nn.TransformerEncoderLayer(d_model=d_model,dim_feedforward=d_model*2, nhead=2, dropout=dropout)self.encoder = nn.TransformerEncoder(self.encoder_layer,num_layers=3)self.pred_layer = nn.Sequential(nn.BatchNorm1d(d_model),nn.Linear(d_model, n_spks),)

Strong Baseline (acc>0.7750)
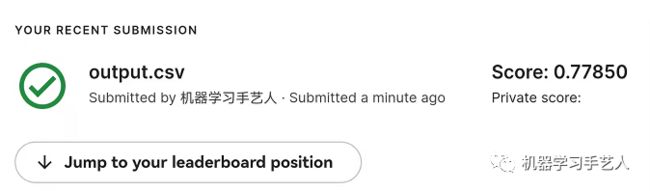
方法:维度更改+使用ConformerBlock+Dropout+全连接层修改+Train longer。与medium baseline相比,将transoformerEncoder改为ConformerBlock,可以通过下载现成的Conformer代码实现。运行代码,提交后得到分数:0.77850。
!pip install conformerfrom conformer import ConformerBlock# 模型中的主要改动def __init__(self, d_model=224, n_spks=600, dropout=0.25):super().__init__()self.prenet = nn.Linear(40, d_model)self.encoder = ConformerBlock(dim = d_model,dim_head = 4,heads = 4,ff_mult = 4,conv_expansion_factor = 2,conv_kernel_size = 20,attn_dropout = dropout,ff_dropout = dropout,conv_dropout = dropout,)self.pred_layer = nn.Sequential(nn.BatchNorm1d(d_model),nn.Linear(d_model, n_spks),)
Boss Baseline (acc>0.86500)
方法:维度更改+ConformerBlock+Self-attention pooling+Additive margin softmax+Train longer。与strong baseline相比,将mean pooling 换成了self-attention pooling,另外使用了简单版的additive margin softmax,batch size从32到64,step改为200000步。运行代码,提交后得到分数:0.78725。提升效果有限,另外试了正常版的additive margin softmax,仍然效果有限,最后用ensemble+TTA,能到达boss baseline,不过这跟作业课件中的要求有违背,课件中的说明是单个模型到达boss baseline,以后有更多时间我会再做更多尝试,完成后再补充。
class SelfAttentionPooling(nn.Module):def __init__(self, input_dim):super().__init__()self.W = nn.Linear(input_dim, 1)def forward(self, batch_rep):att_w = F.softmax(self.W(batch_rep).squeeze(-1), dim=-1).unsqueeze(-1)utter_rep = torch.sum(batch_rep * att_w, dim=1)return utter_rep
from torch.autograd import Variableclass AMSoftmax(nn.Module):def __init__(self):super().__init__()def forward(self, input, target, scale=5.0, margin=0.35):cos_theta = inputtarget = target.view(-1, 1) # size=(B,1)index = cos_theta.data * 0.0 # size=(B,Classnum)index.scatter_(1, target.data.view(-1, 1), 1)index = index.byte()index = Variable(index).bool()output = cos_theta * 1.0 # size=(B,Classnum)output[index] -= marginoutput = output * scalelogpt = F.log_softmax(output, dim=-1)logpt = logpt.gather(1, target)logpt = logpt.view(-1)loss = -1 * logptloss = loss.mean()return loss
作业四答案获得方式:
-
关注微信公众号 “机器学习手艺人”
-
后台回复关键词:202204