中山大学羽毛球场馆自动订场(Python+selenium+百度aip)
双鸭山南校人太多,小伙伴们日常约球抢不到室内的场馆,只好去室外打。所以趁考完试有时间写了一个自动抢羽毛球场的脚本,网好的时候20秒订场无压力。下面来分享一波这个脚本的一些技术细节(重点讲一下图像降噪和百度云的文字识别接口),也算是对我这两天学习的一个总结。
其实在大概在一年之前在自动操作浏览器上selenium+phantomjs还是标配,但是随着17年8月firefox和chrome相继推出了无头模式的浏览器完美地取代了phantomjs,所以selenium 3.8.1以上的版本都不再支持phantomjs。这个脚本用的是headless firefox,与以往Selenium不同的是需要额外加载selenium firefox 的官方Webdriver:Geckodriver,不然会报错。另外一个要注意的是如果想用headless firefox需要电脑本身已经安装了firefox(注意至少是56.0以上的版本,否则不支持无头模式)。
Gecokdriver下载地址:https://github.com/mozilla/geckodriver/releases
首先配置好driver并获取鸭大NetID登录页面信息:
from selenium import webdriver
driver = webdriver.Firefox(executable_path='.../geckodriver')#根据geckodriver所在路径配置driver
driver.get("http://gym.sysu.edu.cn/product/show.html?id=61")#获取页面信息
driver.maximize_window()#最大化窗口
driver.find_element_by_xpath("//a[contains(text(),'登录')]").click()#跳转到登录页面配置好driver后,我们就可以用python在后台操作网页啦,一些常用的操作:
driver.get("http://gym.sysu.edu.cn/index.html")#打开网页
driver.find_element_by_xpath("//a[@href='/product/index.html']").click()#用click()点击用xpath定位到的网页元素
driver.find_element_by_xpath("//input[@id='txt_name']").send_keys('英东羽毛球场')#用send_keys()向输入框中填入数据
driver.execute_script("window.scrollTo(0,500)")#滑动网页到指定位置
driver.save_screenshot(screenshotadd)#保存当前页面截图
driver.page_source()#获取当前页面源代码
driver.current_url#当前页面的url
我们需要对登录页面截图,根据验证码的xpath定位验证码在整张截图的位置并截取保存验证码到本地:
def Convertimg():
imglocation = ("//img[@name='captchaImg']")#验证码的xpath地址
driver.save_screenshot(screenshotadd)
im = Image.open(screenshotadd)
left = driver.find_element_by_xpath(imglocation).location['x']
top = driver.find_element_by_xpath(imglocation).location['y']
right = driver.find_element_by_xpath(imglocation).location['x'] + driver.find_element_by_xpath(imglocation).size['width']
bottom = driver.find_element_by_xpath(imglocation).location['y'] + driver.find_element_by_xpath(imglocation).size['height']
im = im.crop((left, top, right, bottom))
im.save(codeadd)原始的验证码是这样的:
![]()
虽然现在百度谷歌阿里都有各自的将图像识别成文字的python接口,但是这些接口在图像有噪音时普遍很差。比如这里的验证码有多条直线穿过,如果直接用像pytesseract这样的图像识别接口来识别的话基本上成功率只有百分之几,也就是说可能要试100次才能成功登陆几次,那我这卡着12点抢场地的脚本肯定要凉。所以必须对验证码进行降噪再进行图像识别才行。事实上经过降噪处理的验证码识别一次成功率达到了80%以上。
现在比较流行的比较标准的验证码识别套路是(图片来自https://blog.csdn.net/eddy_zheng/article/details/48895085):
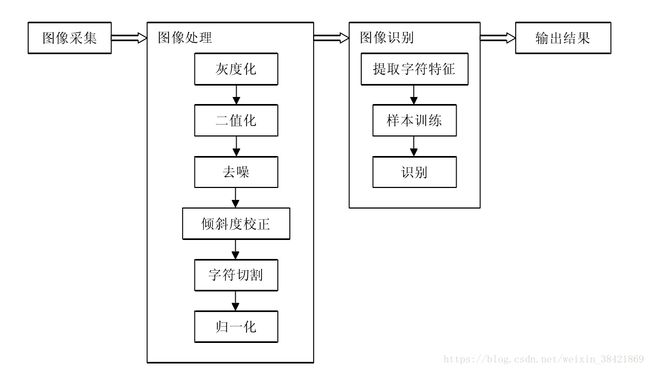
但是我发现我们学校验证码上的噪音线都是黑色的,而字符通常都是彩色的,这可是个大bug啊哈哈哈。所以我的降噪流程是:
1.将黑色以及接近黑色的噪音线(R,G,B值都接近0)替换为白色(R,G,B值都是255)
![]()
2.将第一步得到的图像进行二值处理变成黑白图像,灰度阈值设为160都可,也就是低于这个阈值的点都填白色,高于这个阈值的点都填黑色
![]()
3.提取边缘,使得字母和数字更清晰(虽然在这张图不太明显,但是经过几十张验证码的测试,这一步还是有必要的):
![]()
4.把图片适当变大一点,提高文字识别的精度

到这里降噪就完成啦,顺便介绍一下python图片处理界的三个大佬:PIL、opencv和skimage。PIL应该是最老的一位大佬,有些年久失修而且目前只支持python 2.x版本,于是有人就把它改造升级成了python 3.x下的pillow,功能也变强了(但仍然是偏基础的库)。opencv可以说是高端玩家了,不仅高端还资格老,不仅资格老还在不停地更新。图像处理对opencv只是小菜,它还能处理视频,也有深度神经网络和机器学习功能,这意味着opencv自己就可以完成对文字识别的训练和深度学习提高识别精度,可以说是图像处理界的战斗机了。skimage看名字就知道它和大名鼎鼎的scikit-learn有点儿关系,功能上比较接近opencv,也是个强大的包。我觉得看documentation应该是学习一个包最快的方式,这里放上三个包的documentation地址。但是也放上一个写得不错的图像处理的总结比较贴供参考:https://blog.csdn.net/IAMoldpan/article/details/78628460
Documentation地址:
skimage : http://scikit-image.org/docs/stable/
opencv:https://docs.opencv.org/master/d9/df8/tutorial_root.html
PIL:http://pillow.readthedocs.io/en/5.2.x/
降噪部分的代码:
def clearimage(originadd):
img = Image.open(originadd)#读取系统的内照片
#将黑色干扰线替换为白色
width = img.size[0]#长度
height = img.size[1]#宽度
for i in range(0,width):#遍历所有长度的点
for j in range(0,height):#遍历所有宽度的点
data = (img.getpixel((i,j)))#打印该图片的所有点
if (data[0]<=25 and data[1]<=25 and data[2]<=25):#RGBA的r,g,b均小于25
img.putpixel((i,j),(255,255,255,255))#则这些像素点的颜色改成白色
img = img.convert("RGB")#把图片强制转成RGB
img.save(repadd)#保存修改像素点后的图片
#灰度化
Grayimg = cv2.cvtColor(cv2.imread(repadd), cv2.COLOR_BGR2GRAY)
ret, thresh = cv2.threshold(Grayimg, 160, 255,cv2.THRESH_BINARY)
cv2.imwrite(greyadd, thresh)
#提取边缘
edimg = Image.open(greyadd)
conF = edimg.filter(ImageFilter.CONTOUR)
conF.save(edadd)#改变图片尺寸
def ResizeImage(filein, fileout, width, height, type):
img = Image.open(filein)
out = img.resize((width, height),Image.ANTIALIAS)
out.save(fileout, type)其实按照图像识别的套路,在正式识别之前是要把图片的字符切成一个一个的然后分别识别的,但是我降噪做得比较干净不切片也能识别的很好加上学校网站允许填入的验证码之间有空格所以就没有切片后分别识别,这样运行速度也快一点。
在图像降噪上也有一些流行的算法,但是我们对我鸭大的验证码效果都不太好,降完后识别率依然很低所以我就弃用了。但是这里也把这些算法放上来给大家参考:
#去除多余的点和多余的干扰线
im = Image.open(rgbadd)
data = im.getdata()
w, h = im.size
try:
for x in range(1, w - 1):
if x > 1 and x != w - 2:
# 获取目标像素点左右位置
left = x - 1
right = x + 1
for y in range(1, h - 1):
# 获取目标像素点上下位置
up = y - 1
down = y + 1
if x <= 2 or x >= (w - 2):
data.putpixel((x, y), 255)
elif y <= 2 or y >= (h - 2):
data.putpixel((x, y), 255)
elif data.getpixel((x, y)) == 0:
if y > 1 and y != h - 1:
# 以目标像素点为中心点,获取周围像素点颜色
# 0为黑色,255为白色
up_color = data.getpixel((x, up))
down_color = data.getpixel((x, down))
left_color = data.getpixel((left, y))
left_down_color = data.getpixel((left, down))
right_color = data.getpixel((right, y))
right_up_color = data.getpixel((right, up))
right_down_color = data.getpixel((right, down))
# 去除竖线干扰线
if down_color == 0:
if left_color == 255 and left_down_color == 255 and \
right_color == 255 and right_down_color == 255:
data.putpixel((x, y), 255)
# 去除横线干扰线
elif right_color == 0:
if down_color == 255 and right_down_color == 255 and \
up_color == 255 and right_up_color == 255:
data.putpixel((x, y), 255)
# 去除斜线干扰线
if left_color == 255 and right_color == 255 \
and up_color == 255 and down_color == 255:
data.putpixel((x, y), 255)
else:
pass
except:
pass另一种降噪方法:
# 根据一个点A的RGB值,与周围的8个点的RBG值比较,设定一个值N(0 下面一步就是对降噪完成的图片进行文字识别得到验证码啦,这里一定要吹一波百度的文字识别接口baidu-aip,私以为做得相当不错,在中文的图像识别上有碾压谷歌的pytesseract的趋势。来张无噪声的图感受一下:

百度baidu-aip接口识别结果:
蒹葭
先秦:佚名
蒹葭苍苍,白露为霜。所谓伊人,在水一方。
溯洄从之,道阻且长。溯游从之,宛在水中央。
蒹葭萋萋,白露未晞。所谓伊人,在水之湄。
溯洄从之,道阳且跻。溯游从之,宛在水中坻。
蒹葭采采,白露未已。所谓伊人,在水之涘。
溯洄从之,道阻且右。溯游从之,宛在水中沚。
谷歌pytesseract识别结果:
8 所 调 人 , 在 - 方 。
深 从 久 , 定 中 央
。 所 澈 伊 人 , 圭 水 淳
。 淇 渡 从 之 , 定 圭 北 中 坂 。
。 所 澈 伊人 , 圭 水 浩
从 丿 , 定 圭 水 中 沥 。
这里重点介绍一下百度文字识别接口的用法:
1.首先注册一个百度云账号https://cloud.baidu.com/
2.在导航栏里面点文字识别,百度云提供了很多免费的人工智能的接口,感觉可以说是很棒了,对自然语言处理、自动驾驶、人脸识别感兴趣的小伙伴都可以来围观一波,一定会有意想不到的惊喜。
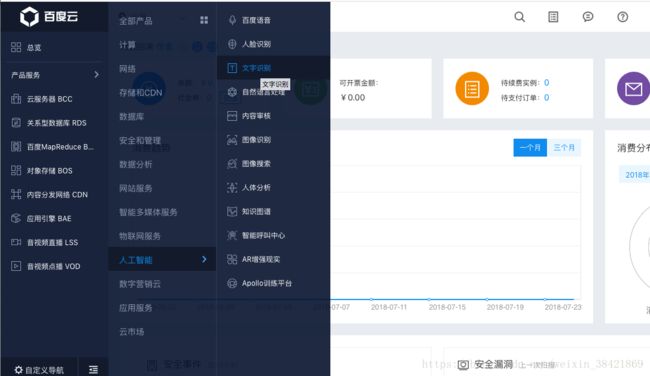
点创建应用,勾选文字识别下面的接口,就可以得到百度爸爸给我们的接口密匙啦,密匙包括:
'appId': '11352243',
'apiKey': 'Nd5Z1NkGoLDvHwBsD2bFLpCE',
'secretKey': 'A9FsnnPj1Ys2Gofi0SNgYo23hKOIK8Os'
(举个栗子大概是这种形式,但是为了隐私随便改了几个字母)
3.安装baidu-aip包,下载地址:https://pypi.org/project/baidu-aip/。私以为直接用pip或者brew更方便一点。
用百度的图形识别接口识别验证码的代码:
config = {
'appId': '11352243',
'apiKey': 'Nd5Z1NkGoLDvHwBsD2bFLpCE',
'secretKey': 'A9FsnnPj1Ys2Gofi0SNgYo23hKOIK8Os'
}
client = AipOcr(**config)
image = open(image_path,'rb').read()
result = client.basicGeneral(image)
with open("/Users/mengjiexu/Documents/badminton/result.txt","a") as f:
for line in result["words_result"]:
f.write(line["words"]+"\n")另外一个在写程序中遇到的小麻烦是明明可以从源代码中定位到订球场页面的点击位置,但是运行时总是报错"could not be scrolled into view",可能是这个元素在浏览器中实际上是不能被直接点击的,所以与一般直接click()的方式不同,我不得不换用了另一种方法去点击它,于是成功了。
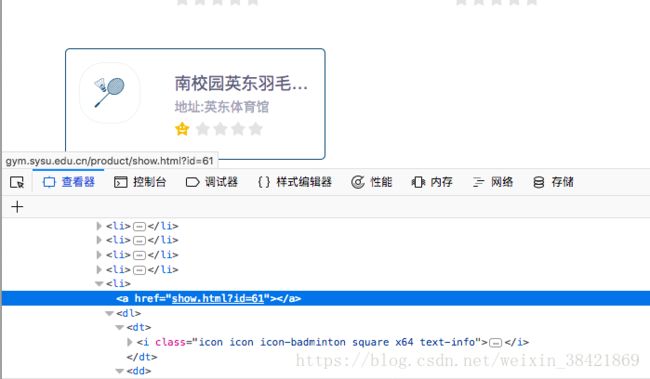
target = driver.find_element_by_xpath("//a[@href='show.html?id=61']")
driver.execute_script("arguments[0].click();", target)另外分享一些用python和网站进行交互的tips:
1.如果你网速不够快,就需要在跳转页面时加个两三秒的等待时间或者直接指定等某个元素完全渲染出来再进行下一步,不然即使你的代码没错,也有可能因为暂时没有渲染出你下一步要用的元素报错。举个栗子(不是这次写鸭大的程序时候用到的):
import selenium.webdriver.support.ui as ui
wait = ui.WebDriverWait(driver, 10)#等指定元素加载出来再进行下一步
wait.until(lambda driver: driver.find_element_by_xpath("//a[contains(text(),'人才管理')]"))
driver.find_element_by_xpath("//a[contains(text(),'人才管理')]").click()
time.sleep(2)#加两秒的等待时间2.有些网页会有iframe,一般iframe的形式都是跳出一个边栏把页面分成两部分(具体有没有iframe需要看网页的源代码才能完全确定),而iframe里的元素是不能直接访问的,需要从主页面switch过去,举个栗子:
cvframe = driver.find_element_by_xpath("//div/iframe")#根据xpath定位iframe的位置
driver.switch_to_frame(cvframe)#从主界面切换到iframe以访问iframe中的元素
html = etree.HTML(driver.page_source)
cvcontent = html.xpath("//html/body/descendant::text()")
with open("{}{}{}".format('/Users/mengjiexu/Documents/parser/', id, '.txt'), 'w') as f:
for line in cvcontent:
f.write(line.strip())
f.close()
driver.switch_to_default_content()#从iframe切回主界面现在只是完成了一个有基础的订场功能的demo,后期可能会加上挂到服务器上定时启动或者是放到坚果云上用手机启动脚本订场的功能,但是我要暂停一下去写高宏作业啦,不然高宏可能要凉,等过几天再更新代码吧~
应广大热爱打球的吃瓜小伙伴们的要求,这里先放上目前的demo:https://github.com/xumj9/sysubadminton
程序实现效果请看:http://t.cn/RewK11A?m=4265757913116630&u=3564852345
主要参考链接:
https://segmentfault.com/a/1190000012861561
https://blog.csdn.net/u013010889/article/details/54347089
https://www.cnblogs.com/monxue/p/get_random_code.html
https://www.cnblogs.com/qqandfqr/p/7866650.html
https://blog.csdn.net/xinghun_4/article/details/47864949
https://blog.csdn.net/eddy_zheng/article/details/48895085