【翻】Lucene相关性算法TF-IDF、BM25算法介绍
推荐参考文章:
英文版: https://opensourceconnections.com/blog/2015/10/16/bm25-the-next-generation-of-lucene-relevation/
中文版: BM25下一代Lucene相关性算法
一、 TF*IDF
TF*IDF :检索词和文档相关性的评分计算公式: tf * idf
IDF * TF = log(numDocs / docFreq) * tf- 第一步,计算词频 tf: 即检索词,如'dog'在文档中出现的频次。
- 第二步,计算逆文档频率 idf: 即检索词出现在多少文档中。如果在几乎所有文档中都出现,那就是一个非常常见的词,说明含义并不特殊,那么它在计算单词和文档相关性时的权重就不应该很高。 idf = log(numDocs/ docFreq)
- 第三步,考虑文档的长度field length 。检索词'dog'在一个有500个单词的文档中出现两次,文档是有关dog的可能性比较低;如果'dog'在一个很短的文档中出现两次,那它跟dog有关的可能性就较大。所以,这里引入一个概念,fieldNorms。在匹配段文档和长文档时,fieldNorms贡献了一个倾向短文档的偏置。
二、 Fudging TF*IDF
信息检索实验中发现原始的TF-IDF 值并不能很好的拟合相关性。单词与文档中的相关性并不是随着出现频次的增加而线性增长的。一篇文章中提到6次dog,就意味着它比另一篇提到dog3次的文档的相关性高两倍吗?
所以,对TF*IDF进行了修改,修改后的计算公式为:
IDF score * TF score * fieldNorms = log(numDocs / docFreq +1) * sqrt(tf) * (1/sqrt(length))比较公式可以发现,这里对三个数值TF, IDF, field length的使用都进行了修改,不再是直接。
那么这么修改的含义是什么呢?对于相关性计算都有什么改变和提升呢?
1、从原始TF到TF Score, TF Score = sqrt(TF)
词term在文档中出现的频次与文档的相关性不再是线性关系,而是趋于更加平滑的关系。查询单词在一个文档中出现了 16次,在另一个文档中出现了4次,前面文档的相关性比后面的高2倍,而不是4倍.
| Raw TF/原始词频 | TF Score |
|---|---|
| 1 | 1.0 |
| 2 | 1.141 |
| 4 | 2.0 |
| 8 | 2.828 |
| 16 | 4.0 |
2、从原始DF到IDF score, IDF score = log(numDocs / docFreq +1)
numDocs 表示语料库中的所有文档数。假设 numDocs=1000,对应的原始DF到IDF Score的变换如下。 log函数比反函数更平滑一些。一个单词出现在4个文档中比出现在64个文档中的特殊性差不多高两倍(6.298/3.733)
| Raw DF | IDF Score |
|---|---|
| 1 | 7.214 |
| 2 | 6.809 |
| 4 | 6.298 |
| 64 | 3.733 |
| 128 | 3.048 |
| 256 | 2.359 |
3、从文档长度length到Field Norm score, Field Norm score = 1 / sqrt(length)
一个长度128 的文档的相关性差不多是一个长度为1 的文档的十分之一。这也和我们的直觉更相符合,匹配到的只有一个单词的文档就是关于这个搜索主题的,而长度128的文档,搜索单词只是其中一个单词,其主题是否相关就不那么确定了。
| Raw Length | Field Norm Score |
|---|---|
| 1 | 1.0 |
| 2 | 0.707 |
| 4 | 0.5 |
| 64 | 0.125 |
| 128 | 0.088 |
| 256 | 0.0625 |
三、 BM25: 下一代 TF*IDF
BM25 是在 TF*IDF基础上发展起来的,是 “Best Match 25” 的缩写,发表于1994年, 是调整相关性计算的第 25次迭代。 基础理论来自概率信息检索。
BM25相关性计算公式:
IDF * ((k + 1) * tf) / (k * (1.0 - b + b * (|d|/avgDl)) + tf)这其中对TF、IDF、length 的使用 做了很多改动,我们依次说明下:
1、从经典TF-score 到BM25中的TF-score
BM25中的term频率比传统的TF*IDF更能抑制term频率的影响,频率的影响总是在增加,但渐渐地接近一个值。
我们先不考虑计算公式中的 文档长度 length部分,即把 (1.0 - b + b * (|d|/avgDl)) 当作1, 那么词频在相关性公式中的影响可以简化看作: 其中k是需要学习的一个参数
((k + 1) * tf) / (k + tf)比较 经典TF-score = sqrt(tf) 和 BM25中的TF-score,得到下图的对比:(这里k=1.2)
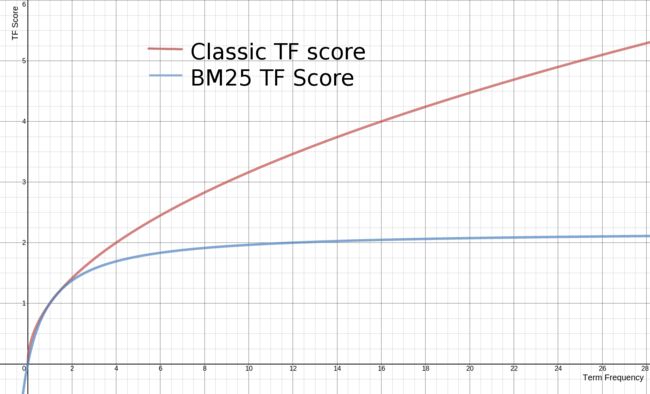
图中可以看出来,BM25中的TF-score曲线渐近接近(k+1)。什么意思呢?
含义是更多的tf意味着更多的相关性,但是你很快就达到了收益递减。你永远不会超过k,但你总是接近它!
而经典的Lucene tf不断增加,但从未达到饱和点。
这个k值是多少?对于BM25,k通常设置为1.2。大多数人不去管k。改变k是一种有用的调整方法来修改TF的影响。修改k会导致渐近线移动。然而更重要的是,较高的k会导致TF需要更长的时间才能达到饱和。通过扩展饱和点,可以扩展高频和低频率文档之间的相关性差异!
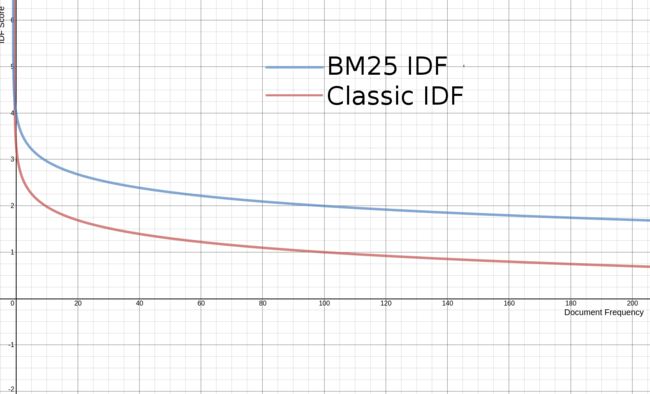
2、从经典 IDF-score 到BM25中的 IDF-score
IDF score = log(numDocs / (docFreq + 1))
从图上看BM25’s IDF 与经典 Lucene IDF很相似,并没有什么大的区别。?????并没有讲清楚相似在哪里
2、从经典 文档length-score 到BM25中的 length-score
相似性分数还受文档是否高于或低于语料库中文档平均长度的影响。
((k + 1) * tf) / (k * (1.0 - b + b * L) + tf)计算公式中引入了两个变量,常数b,长度L,用 (1.0 - b + b * L) 与 k 相乘,作为分母中的一个加项。
L 是文档长度length=|d|相比于平均文档长度avgDl的比值 ,L= |d|/avgDl。
如果文档长度是语料库中平均文档长度的两倍, L =2 ;如果文档长度是平均文档长度的十分之一,L = 0.1 。

如图中所示,不同L值的最终结果是,较短的文档到达渐近线的速度更快。他们几乎马上饱和到最好的TF分数。这是有道理的,短文档的term较少。在这些简短的文档中匹配的越多,就越确信其相关性。所以这个数字上升得更快。另一方面,一本长篇的书需要更多的匹配才能达到我们自信的程度。所以达到“最大相关性”需要更长的时间。
常数b将允许我们微调L值对得分的影响。注意,在上面的公式中,b为0时,完全消除了L的影响,等价于经典的TF公式。b越高,文档长度对评分的影响越大。
BM25的适用范围:
对核心文档搜索问题是巨大的改进。但在数字、图像和其他被搜索实体的边缘,使用并不明朗。
随着BM25成为默认值,我们将直接看到当理论与实践相结合时会发生什么。相关性从来不是一个固定不变的,它是你精心打造的用户体验。现实世界可能会大不相同。文档不仅仅是文档,还包括餐厅、产品、新闻文章、推特、医生办公室和其他许多东西。也许你的“相似性”的正确答案是经常提起朋友在微博上的微博,在附近有着相似的兴趣。减少文本相似度,更多关注用户需要找到的重要内容。换言之,搜索和其他任何东西一样,都是在打造用户体验。