大数据平台设计思路
一、什么是大数据平台
一般情况下,大数据平台指的是使用了Hadoop、Spark、Storm、Flink、Blink等这些分布式、实时或者离线计算框架,并在上面运行各种计算任务的平台。
建设大数据平台的最终目的是服务于业务需求,解决现有业务问题或者创造新的机会。业务部门可能并不关心是采用大数据技术,还是传统的数据库技术,是否采用大数据技术的主要依据是数据量。如果出现任务运行很久的情况,或者因为计算量太大现有技术不能满足,又或者有大量半结构化、非结构化数据需要处理的时候,可能就有大数据的诉求了。
二、大数据平台架构设计
大数据平台架构的设计包括整体框架设计和整体技术架构设计。
1、大数据平台整体架构
大数据平台整体架构可分为七大部分:目录管理、数据集成、数据资产管理、数据治理、数据开发、数据分析、数据共享及数据安全。

目录管理
通过盘点和梳理业务数据,编制、发布数据目录,规划和指导数据的接入、管理、治理、开发、共享等。
数据集成
为大数据平台提供基础支撑性服务,提供多种数据接入工具,实现结构化和非结构化的数据的汇聚接入,并支持数据的预处理,为大数据平台提供原始数据支撑。
数据资产管理
通过管理数据标准、元数据、数据资源等,提高数据资产的价值。
数据治理
规范数据的生成以及使用,发现并持续改善数据质量。
数据开发
提供大数据开发、分析、挖掘等功能。非专业的业务人员也可以利用图形化的IDE进行数据分析。
数据分析
提供从基本数据查询统计、数据交叉汇总、自由钻取分析、多维数据分析等多层次的数据分析功能。
数据共享
实现不同部门、不同格式数据的共享交换,以及异构系统之间、新老系统之间的信息的透明交换。
数据安全
提升一系列安全工具,包括数据加密、数据脱敏、数据备份、日志审计等。
2、大数据平台技术架构
大数据平台技术架构从下往上依次为数据源层、数据获取层、数据存储层、数据处理层、数据应用层。
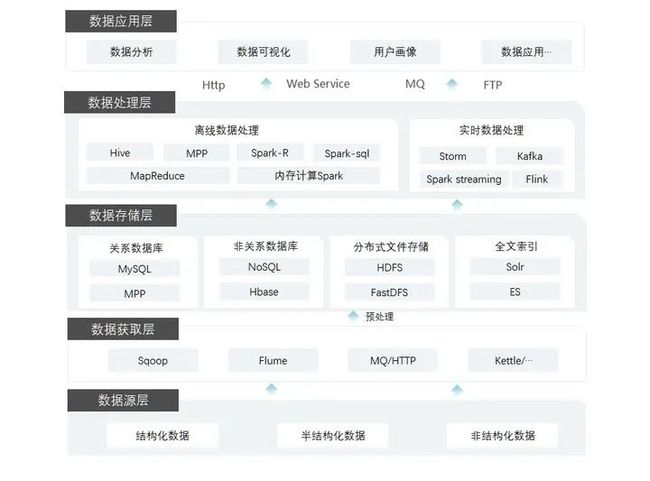
数据源层
非结构化数据:包括图片、声音、视频等,这类数据通常无法直接知道它的内容,数据库通常将它保存在一个BLOB字段中。一般的做法是,建立一个包含三个字段的表(编号 number、内容描述 varchar(1024)、内容 blob)。引用通过编号,检索通过内容描述。
半结构化数据:半结构化数据具有一定的结构性,但是结构变化很大。因为我们要了解数据的细节所以不能将数据简单的组织成一个文件按照非结构化数据处理,由于结构变化很大也不能够简单的建立一个表和他对应。其存储方式有两种:一种是化解为结构化数据,另一种是用XML格式来组织并保存到CLOB字段中。
数据获取层
数据获取层的主要作用是实现多源异构数据的采集、聚合、传输及预处理,集成多种数据采集工具。
Sqoop(发音:skup)是一款开源工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据传递。它可以将一个关系型数据库(MySQL ,Oracle ,Postgres等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
Flume(发音:fluːm)是一个分布式的海量日志采集、聚合和传输系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
消息队列(MQ)是一种应用程序对应用程序的通信方法。应用程序通过写和检索出入列队的针对应用程序的数据(消息)来通信,而无需专用连接来链接它们。消息传递指的是程序之间通过在消息中发送数据进行通信,而不是通过直接调用彼此来通信。
Kettle(发音:ketl)是一款开源ETL工具,可以跨平台上运行,绿色无需安装,数据抽取高效稳定。中文名称叫水壶,该项目的主程序员MATT 希望把各种数据放到一个壶里,然后以一种指定的格式流出。
kettle四大家族:
Chef(中文:厨师):工作(job),设计工具 (GUI方式);
Kitchen(中文:厨房):工作(job)执行器 (命令行方式);
Spoon(中文:勺子):转换(transform),设计工具 (GUI方式)
Pan(中文:平底锅):转换(transform)执行器 (命令行方式)
数据存储层
关系数据库:Mpp(大规模并行处理)技术是基于关系数据库的成熟技术,伴随着分布式与并行数据库技术的发展而来。
非关系数据库:NoSQL(NoSQL = Not Only SQL ),意即“不仅仅是SQL”。用以解决大规模数据集合多重数据种类问题。分为四大类:键值(Key-Value)存储数据库(如Redis),列存储数据库(如HBase),文档型数据库(SequoiaDB),图形(Graph)数据库(如Neo4J)。
分布式文件存储:HDFS是基于流数据模式访问和处理超大文件的需求而开发的,可以运行于廉价的商用服务器上。它具有高容错、高可靠性、高可扩展性、高获得性、高吞吐率等特征,为海量数据提供了不怕故障的存储,为超大数据集(Large Data Set)的应用处理带来了很多便利。FastDFS是一个开源的轻量级分布式文件系统。功能包括:文件存储、文件同步、文件访问(文件上传、文件下载)等,解决了大容量存储和负载均衡的问题。
全文索引:Solr是以Lucene搜索库为核心,提供全文索引和搜索的开源工具,提供REST的HTTP/XML和JSON的API。ES(ElasticSearch)是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
数据处理层
离线数据处理:大数据离线处理一般使用 Hdfs或MPP 存储数据,使用MapReduce、Spark做批量计算,计算完成的数据如需数据仓库的存储,直接存入 Hive , 然后从Hive 进行展现。
实时数据处理:是指计算机对现场数据在其发生的实际时间内进行收集和处理的过程。
三、大数据平台系统设计
1、目录管理系统
目录管理系统用于盘点和梳理业务数据,编制发布业务目录,规划和指导数据的采集、处理、管理和共享等。一般包括目录分类管理、目录编制、审核和发布功能。
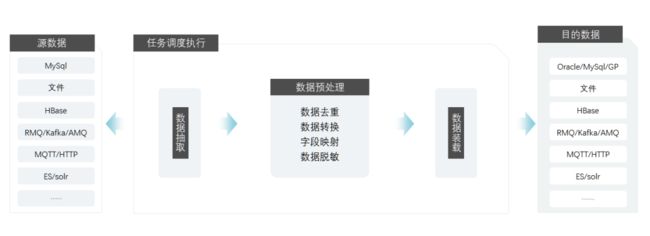
2、数据采集系统
数据采集系统为大数据平台提供基础支撑性服务,构建高效、易用、可扩展的数据传输通道。
3、数据资产管理系统
数据资产管理系统主要作用为标准数据管理、元数据管理、数据资源管理和数据资产盘点。
标准数据管理:管理对象为字典、数据元(用于业务方标准化管理业务字段),形成数据标准体系。
元数据管理:元数据是所有系统、文档和流程中包含的所有数据的语境,是生数据的知识。
·元模型管理:获取并展示不同数据库类型的元模型元素及属性信息;
·数据源管理:新增、编辑、维护数据库信息;
·元数据注册:包括表、视图、索引、字段、列族、消息等各类元模型下的元数据;
·元数据查看:按数据源查看已注册的所有元数据,并可查看元数据的关联关系、血缘关系。
数据资源管理:对数据资源进行目录化管理,形成有层级、有结构的数据资源集市。
·数据目录分类:实现数据目录的分类设置;
·数据目录编制:实现数据目录的新增、修改、删除、停/启等;
·业务目录映射:配置业务目录与数据目录的映射关系;
数据资产盘点:数据资产仪表盘、数据资产查看。
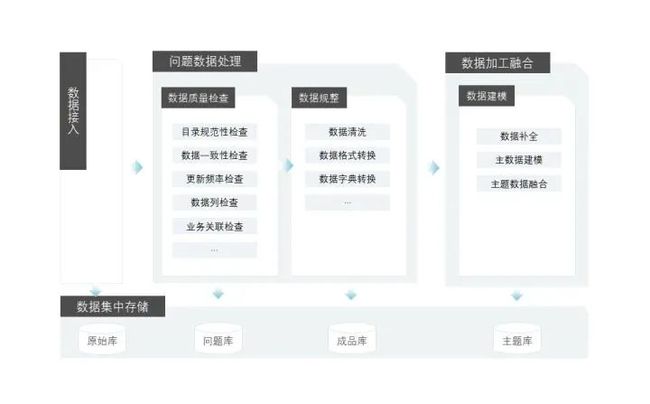
4、数据治理系统
数据治理系统用于规范数据的生成以及使用,改进数据质量,对数据进行加工处理,提升数据价值。提供识别和度量数据质量能力、数据清洗转换能力、数据加工三个核心能力。
数据质量管理:包括规则管理(准确性、完整性、唯一性、一致性、及时性、业务关联性等)、任务配置、检查报告。
数据规整管理:包括格式转换、字典转换、内容转换、任务管理、日志等。
数据加工:模型定义、模型调度。
5、数据共享系统
数据共享系统依托数据资源目录,按照数据交换标准,实现数据资源跨部门、跨层级、跨区域共享交换。提供资源展示、检索、申请、使用、下载能力,用户管理和资源授权能力,以及数据库表、服务接口、文件等类型共享交换能力。

6、数据开发系统
数据开发系统使用大数据或人工智能算法组件对数据进行分析、挖掘,形成数据服务产品。数据开发管理:包括应用工程管理、计算任务管理、任务调度管理、资源管理等。应用开发工具:提供在线开发IDE、数据源控件库、预处理控件库、模型控件库、可视化控件库、输出控件库、挖掘算法库等。
7、数据分析系统
对接各种业务数据库、数据仓库以及大数据平台,为用户提供从基本数据查询统计、数据交叉汇总、自由钻取分析、多维数据分析等多层次的数据分析功能。用户只需用鼠标拖拽指标和维度,即可产生数据分析结果。同时提供丰富的统计图表用于分析结果的可视化展示。
出处:https://zhuanlan.zhihu.com/p/81999971