规则引擎和 Flink CEP
转载于:实时计算系列(3) - 规则引擎和 Flink CEP | 廖嘉逸's Blog (liaojiayi.com)
什么是 CEP ?
CEP 是 Complex Event Processing 的缩写,将这一类事件处理单独区分出来的核心原因就是计算范式相比普通的实时计算要更加“复杂”,这个复杂不是业务逻辑上的,而是在技术上需要结合不同的计算范式,举例如下:
- 结合了时序的上下文:如风控场景识别了作弊的行为序列后,给「先做 xx,后做 xx,再做 xx」的用户进行封禁;
- 结合了否定的语义:如电商营销场景给「浏览商品后 10 分钟未下单的用户」发送优惠券;
- 结合了自定义统计的语义:如实时监控场景为每个微服务设定监控规则,「第一次报警发生后,30s 内发生第二次报警」的情况进行报警升级;
CEP 本身并没有脱离实时计算的范畴,所以绝大部分用户还是选择基于 Flink,或者已有的计算服务上去搭建相关的框架,CEP 对应的功能更多是以 library 的形式存在。并且,从上面的例子可以看到,这些场景在业务上都是很常用的,如果定制化地解决某一个或几个需求,大部分工程师也一定觉得没有问题。
通用系统架构
然而,实际情况往往不是写几个 SQL,或者几行代码这么简单,对于大多数 CEP 的应用场景而言,“复杂规则”的制定者通常是运营、商家、市场等非技术同学,对于大多数 CEP 的业务效果而言,通常是短时间内直接触达用户,比如发优惠券、发推送等等。
这类实时计算脱离了以往的 BI 场景,而跟真正的业务效果挂钩,这也是导致系统非常复杂的一个重要因素,所以很多企业中将这种系统,抽象成为一个规则引擎服务来完成。
规则引擎服务的架构通常如下图所示:

实现难点
由于和 BI 场景不同,以及规则引擎的输出结果直接和用户终端的表现挂钩,所以在实现上相比一般的实时数仓场景更加严谨,具体体现在:
组件复杂程度高:
以上面的架构图为例,进入 CEP 的数据流是多种多样的,可能存在窗口计算、多流 Join 等复杂处理,CEP 规则引擎输出的数据,需要经过各种校验、兜底等处理逻辑。对于平台而言,一个完整且真正可用的平台,需要包括从规则配置到最后 ROI 计算的完成投放闭环。
离在线不一致:
CEP 规则引擎属于在线计算,好处是延时高,但坏处是数据的输出结果和事件顺序强相关,即使开发者使用 eventtime 也会面临事件时间超出 watermark 而导致被丢弃的问题。如果事后出现相关反馈,在离线计算中引入时序相关的计算逻辑,会是一个非常复杂的问题,而且即使计算正确,也未必能和当时的在线任务情况完全吻合,比如作业的消息积压、客户端延迟发送都会导致数据准确性的问题。
准确性校验:
以发放优惠券或者广告投放为例,这类的行为最终会用于 ROI 计算,所以每一次的规则触发都需要保证准确性,并且有一定的“兜底”措施。常见的兜底措施有频控、给指定规则设置最大触发值等。
CEP in Flink
CEP 在 Flink 中以 library 形式存在,并不和其底层引擎代码相绑定,只是继承很多 low-level 的 API,阅读 cep 的代码过程中也可以学习到不少 Flink 上新颖的使用方式。我们可以将 Flink 内部的 CEP 实现简要分成以下几个步骤:
- 规则解析
- 规则匹配
- 匹配事件提取
规则解析
Flink 中的 CEP 借鉴了Efficient Pattern Matching over Event Streams中 NFA 的模型,在这篇论文中,还提到了一些内存上的优化,我们这里先跳过。
在这篇论文中,提到了 NFA,也就是 Non-determined Finite Automaton,叫做不确定的有限状态机,指的是状态有限,但是每个状态可能被转换成多个状态(不确定)。
我们以一个简单的 CEP 规则为例,看看在 NFA 中,这些事件之间是什么样的关系,
Pattern pattern = Pattern.begin("begin").where(new SimpleCondition() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("a");
}
}).followedBy("middle").where(new SimpleCondition() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("b");
}
}).followedBy("end").where(new SimpleCondition() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("c");
}
});
规则如上,很明显我们是在寻找 a->b->c 这样的事件组合,那对应到 NFA 内部,会根据这个事件关系生成一个状态转移图,大致逻辑如下:
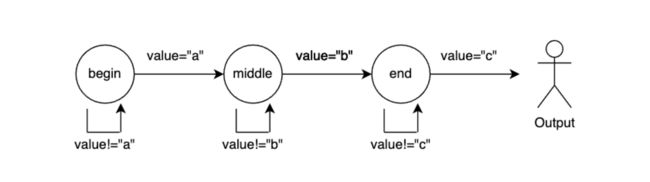
每一个节点对应着该规则匹配过程中的一种状态,比如 “begin” 节点就是初始化状态,在没有接收到 value="a" 的数据之前,此次匹配一直会处于 “begin” 状态;每一条边,对应着状态之间的转换条件,比如 value="a" 的数据满足 “begin” 到 “middle” 的转换条件。节点的概念比较好理解,这里针对边的类型做一下抽象:
- TAKE:进入下一个状态;
- IGNORE:忽略当前事件,保持当前状态不变;
- PROCEED:尝试从下一个状态开始匹配(比如 optional 类型的匹配);
规则匹配
规则解析后生成 NFA,接下来就是接收具体的数据,然后进行匹配流程,匹配过程中非常重要的一点中间状态的存储,即如何把当前的匹配进度存储下来。NFA 中使用了 ShareBuffer 的概念,我们可以在 Flink 中自定义一个 State 来存储明细,依旧以上面的 a->b->c 为例,假设事件的输入为 a1、b1、c1,那么匹配的结果会出现 a1->b1->c1 一种结果,示意图如下所示:

上面的例子非常简单,这里我们期望将情况更加复杂化一些,我们输入 a1,a2,b1,b2,c1,那么此时算子会输出 4 种结果:
- a1->b1->c1
- a1->b2->c1
- a2->b1->c1
- a2->b2->c2
可以看到,输出的 4 个序列都是符合 CEP 规则,我们在 NFA 的一个图上同时进行了多次匹配,这个具体是怎么实现的呢?参考下面的伪代码逻辑,对于每一条记录:
for state in partialStates: // 遍历正在匹配中的状态
for edge in state.edges: // 遍历状态的边,逐一检查是否满足条件
if match: // 如果满足,状态发生转移
partialStates.remove(state)
newState = state.transTo(edge.targetState)
partialStates.add(newState)
// 如果初始化状态发生了转化,新增一个初始化状态,准备新的一次匹配
if not partialStates.contains(beginState):
partialStates.add(beginState)
除此之外,我们并没有独立地存储各个序列,而且在每个状态节点之下,创建了一个 List,并用向前的指针来描述各个事件的关系,以此来复用各个事件在内存的存储,关于 ShareBuffer 的更多内容我们在「匹配事件提取」过程中来说明。
接下来我们可以说说略微复杂的匹配情况,在业务场景里,通常规则制定都会带有时间窗口(否则 Flink 就要永远地匹配下去),比如一天内先发生了 A 事件,后发生了 B 事件:
Pattern pattern = Pattern.begin("begin").where(new SimpleCondition() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("a");
}
}).followedByAny("middle").where(new SimpleCondition() {
@Override
public boolean filter(Event value) throws Exception {
return value.getName().equals("b");
}
}).within(Time.days(1));
这里使用 within(Time) 来标识整个序列的匹配时间窗口,注意这里和 Flink Window 用的自然时间还不太一样,这里的窗口是由序列的第一个匹配事件触发,比如 18:02 时匹配到第一个事件,那么窗口的结束时间就在第二天的 18:02。Flink 在 CEP 算子中通过 Timer 注册来实现此机制,当第一个匹配事件完成后,注册对应结束时间的 Timer,并保存 startTimestamp(第一个匹配事件的时间戳),第二天 Timer 触发,遍历所有正在匹配的状态,如果存在 currentTime > startTimestamp + 1day 的匹配,则进行对应的超时处理逻辑(用户可自定义)。
Flink 在 CEP 算子中定义了丰富的匹配语义,这里无法一一列举,实现的语义明细可以参考:https://nightlies.apache.org/flink/flink-docs-master/docs/libs/cep/,由于 Flink 对于实时计算中功能的实现非常丰富,所以 CEP 的实现并没有超出 Flink 作为一个实时计算引擎本身的能力。
匹配事件提取
完成匹配过程后,接下来就是如何提取匹配的事件列表,还是以上面提到的规则 a->b->c 为例,当事件匹配到 Output 阶段时,Flink 需要做的是将匹配的事件列表输出,其对应的 UserAPI 接口如下所示:
class MyPatternProcessFunction extends PatternProcessFunction {
@Override
public void processMatch(Map> match, Context ctx, Collector out) throws Exception;
IN startEvent = match.get("start").get(0);
IN endEvent = match.get("end").get(0);
out.collect(OUT(startEvent, endEvent));
}
}
这里的 Map 表示一次成功的匹配,Map 的 Key 表示状态节点的名字,List 表示每个状态节点对应下的事件列表。这里就涉及到一个问题,当同时存在多次匹配的时候,Flink 是怎么判断出要输出的事件列表是哪些呢?
上面提到,Flink 在 NFA 的每个状态节点之下,创建了一个 List,并用向前的指针来描述各个事件的关系,以此来复用各个事件。这样的关系图看起来有些乱,我们需要一个 version 来标识各个边之间的走向,这里同样是基于 NFA 论文中 ShareBuffer 的思路,Flink 在每条边上赋予了一个 version 的概念,这样在输出时就能根据 version 来追溯匹配路径。目前 Flink 中是这样做的:
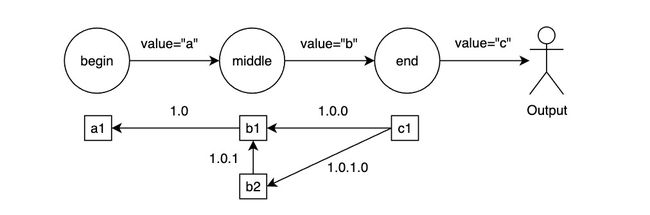
以上图的匹配情况(期望匹配 a->多个b->c)为例,对于每一个元素,都会有一条边指向相连接的元素,并通过版本号的前缀来判断是否兼容,比如 1.0.0 和 1.0 兼容,1.0.1.0 和 1.0.1 兼容,当匹配完成后,从最后一个元素开始向前遍历得到完整的列表。在生成版本号时,是根据状态转移的次数来决定,比如图中 middle 状态的 b1 元素,在收到 b2 事件时,会出现两个状态转移的情况,一是满足 middle 到 end 的转移条件,从 middle 转移到 end,二是保存到当前的 middle 下,匹配多个 b 事件;这两个状态转移分别产生了 1.0.0 和 1.0.1 这两条边的版本号。
Flink 内部实现这里和论文中 NFA 的 ShareBuffer 还有一些不太一样,论文中更多考虑了多规则的场景,示意图如下:

论文中是将版本号长度表示状态节点的路径长度,然后以路径中的分支个数来对版本号进行升级,比如在上图的 e5 节点,出现了分叉,所以 e6->e5 的边版本从 1.0 升级为 1.1,而兼容的规则是 1.1 在当前路径长度向下兼容,比如 1.1 兼容 1.0,详细原理可以参考论文,这里不赘述。
存在的问题
Flink 基于 NFA 的 CEP 算子实现,整体上实现的还算比较完整,但上面提到,CEP 的应用场景通常都比较复杂,所以稍大的场景,都很难直接基于开源的实现进行应用。这里举一些例子:
- 存储明细数据:基于 NFA 的匹配机制,会将每个状态节点的数据都存储下来,最后输出到用户的 UserAPI 里,而实际情况中 CEP 的很大一部分应用场景就是用于“圈人”,实际只需要输出最后的 user_id 即可。存储明细的做法在很多场景极大地限制了复杂的规则应用,和大数据量场景下 CEP 的使用。
- 不支持聚合:很多场景会有比如 30 分钟内报警超过 5 次的规则,对于这类规则,Flink CEP 使用了一个比较简单的做法,比如 times(5) 就创建 5 个状态节点,但这样对于金额求和类的规则就没有办法满足了。
- 难以定位问题:上面在「通用系统架构」部分提到,CEP 的应用场景,很多都是直接作用于用户终端,如果出现准确性上的问题会非常难解释和定位,所以大部分规则引擎的选型,都会将数据校验放到一个比较重要的位置,但目前流式计算本身,由于涉及到数据回放、快照恢复等因素的影响,天然地就难以进行离线验证,而 CEP 复杂的匹配逻辑又在流式计算之上,增加了更多的 debug 难度。
其他 CEP 引擎
我们可以顺带了解一些其他的 CEP 引擎,比如目前做的稍好的 siddhi,但 siddhi 的定位是一个 embedded 流计算框架,有自己的一套语法和使用方式,也有一定量的用户。但如果用户选择了 siddhi,就需要自己完成分布式的部署(也许利用 Kubernates 也非常方便),并且同时拥有两套流计算的技术栈(Flink 和 siddhi)。当然,Hao Chen 将 siddhi 和 Flink 做了结合,有一个 flink-siddhi 的项目,大家有兴趣也可以看看。
总结
本文对规则引擎的系统架构做了讲解,并详细阐述了 Flink CEP 的内在实现原理,关于 CEP 未来的应用前景,我认为随着当前实时数仓的普及,不少公司会将实时计算从传统的 BI 报表场景演进到更多更复杂的场景,而 CEP 也是将是广泛应用场景之一。
不过上面提到,规则引擎本身是有一套完整的系统,目前我所观察到的 CEP 引擎的选型,通常是使用 Flink + 自定义算子(CEP 或者根据业务场景定义),和基于线上服务 + 在线存储进行规则引擎的自定义实现,而无论哪种方式,架构的设计者都要花费大量的精力在设计端到端的完整链路,也侧面说明了这方面的已有基建和开源项目基础都是非常缺失的,期望后续会有更专业,更系统的项目出现。