Flink
1 Flink简介
1.1 前言
大数据的飞速发展,也促使了各种计算引擎的诞生。2006年2月诞生的Hadoop中的MapReduce,2014年9月份诞生的Storm以及2014年2月诞生的Spark都有着各自专注的应用场景。特别是Spark开启了内存计算的先河,其计算速度比Hadoop的MapReduce快100倍,以此赢得了内存计算的飞速发展。或许因为早期人们对大数据的分析认知不够深刻,亦或许当时业务场景大都局限在批处理领域,从而使得Spark的火热或多或少的掩盖了其他分布式计算引擎的身影。但就在这个时候,有些分布式计算引擎也在默默发展着,直到2016年,人们才开始慢慢意识到流计算的重要性。
整个的分布式计算引擎中,通常被划分为三代
- 第一代 Hadoop的MapReduce做静态计算、Storm流计算。两套独立的计算引擎,使用难度比较大
- 第二代 Spark RDD做静态批处理、DStream|StructuredStreaming流计算;统一技术引擎,使用难度小
- 第三代 Flink DataSteam做流计算、DataSet批处理;统一技术引擎,使用难度一般
https://flink.apache.org/flink-architecture.html
Apache Flink是2014年12月份诞生的一个流计算引擎,是一个用于在无界和有界数据流上进行有状态计算的框架和分布式处理引擎。Flink被设计成在所有常见的集群环境中运行,以内存速度和任何规模执行计算。
Flink具有以下特点:
-
可以处理无界以及有界数据流

-
随处部署应用程序
命令执行
远程部署
图形界面(比较常用的)
-
以任何规模运行应用程序
-
充分利用内存性能

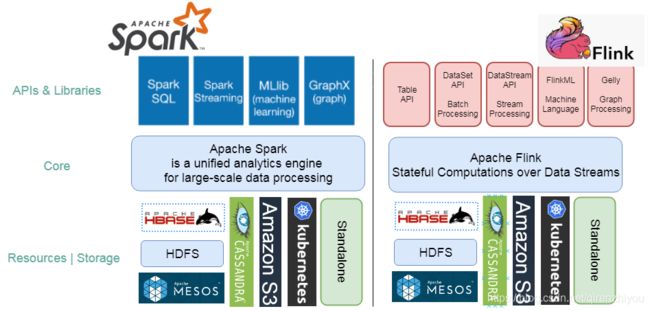
1.2 Spark VS Flink
Flink与Spark设计理念恰好相反
- Spark底层计算是批处理模型,在批处理基础上模拟流,从而导致了流计算实时性较低
- Flink底层计算是连续的流计算模型,在流计算上模拟批处理,既可以保证流的实时性又可以实现批处理
1.3 Flink应用场景
系统监控、舆情监控、交通预测、国家电网、疾病预测、金融行业风控、电商实时搜索优化等
2 环境安装
-
修改flink-conf.yaml
jobmanager.rpc.address: flink taskmanager.numberOfTaskSlots: 4 parallelism.default: 3 -
修改slaves
hadoop10 -
启动Flink
[root@hadoop10 bin]# ./start-cluster.sh -
验证
-
通过JPS查看Flink相关进程
[root@hadoop10 bin]# jps 2656 Jps 2246 StandaloneSessionClusterEntrypoint 2583 TaskManagerRunner -
通过Flink的Web界面查看
http://ip:8081/
-
3 Flink程序
-
导入依赖
<dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-streaming-scala_2.11artifactId> <version>1.10.0version> dependency> -
引入插件
<build> <plugins> <plugin> <groupId>net.alchim31.mavengroupId> <artifactId>scala-maven-pluginartifactId> <version>4.0.1version> <executions> <execution> <id>scala-compile-firstid> <phase>process-resourcesphase> <goals> <goal>add-sourcegoal> <goal>compilegoal> goals> execution> executions> plugin> <plugin> <groupId>org.apache.maven.pluginsgroupId> <artifactId>maven-shade-pluginartifactId> <version>2.4.3version> <executions> <execution> <phase>packagephase> <goals> <goal>shadegoal> goals> <configuration> <filters> <filter> <artifact>*:*artifact> <excludes> <exclude>META-INF/*.SFexclude> <exclude>META-INF/*.DSAexclude> <exclude>META-INF/*.RSAexclude> excludes> filter> filters> configuration> execution> executions> plugin> <plugin> <groupId>org.apache.maven.pluginsgroupId> <artifactId>maven-compiler-pluginartifactId> <version>3.2version> <configuration> <source>1.8source> <target>1.8target> <encoding>UTF-8encoding> configuration> <executions> <execution> <phase>compilephase> <goals> <goal>compilegoal> goals> execution> executions> plugin> plugins> build> -
客户端程序
package com.abc.flink import org.apache.flink.streaming.api.scala._ object FlinkQuickStart { def main(args: Array[String]): Unit = { //1.创建执行环境 val environment = StreamExecutionEnvironment.getExecutionEnvironment //本地运行环境 //val environment = StreamExecutionEnvironment.createLocalEnvironment(3) //2.创建DataStream val text = environment.socketTextStream("flink.abc.com", 9999) //3.对text数据进行常规转换 val result = text.flatMap(line=>line.split("\\s+")) .map(word=>(word,1)) //keyBy就是对上面的数据做分组处理,根据0号元素分组。也就是根据输入的单词分组 .keyBy(0) //类似于spark中的reducebykey;groupbykey .sum(1); //4.控制台打印结果 result.print(); //5.执行流计算任务 environment.execute("myDataStreamJobTask") } }
4 程序部署
-
本地执行
-
通过nc命令监听端口号9999
nc -lk 9999 -
客户端程序修改为本地运行环境
也可以直接使用
StreamExecutionEnvironment.getExecutionEnvironmentval environment = StreamExecutionEnvironment.createLocalEnvironment(3) -
运行程序:执行main方法
-
-
远程脚本部署
-
客户端程序修改为自动识别运行环境
val environment = StreamExecutionEnvironment.getExecutionEnvironment -
通过mvn package生成jar包
-
把生成的jar传输到Linux系统的/tmp/flink目录下
-
通过执行flink_home/bin目录下的flink文件的run action,提交job
[root@hadoop10 bin]# ./flink run -c com.abc.flink.FlinkQuickStart -p 3 -d -m flink.abc.com:8081 /tmp/flink/FlinkQuickStart.jar -c,--class <classname> Class with the program entry point ("main()" method). Only needed if the JAR file does not specify the class in its manifest. #指定启动类 -d,--detached If present, runs the job in detached mode #后台提交 -p,--parallelism <parallelism> The parallelism with which to run the program. Optional flag to override the default value specified in the configuration. #指定并行度 -m,--jobmanager <arg> Address of the JobManager (master) to which to connect. Use this flag to connect to a different JobManager than the one specified in the configuration. #提交目标主机 -
查看运行中的job
[root@flink bin]# ./flink list --running --jobmanager flink.abc.com:8081 -
查看所有job
[root@flink bin]# ./flink list --all --jobmanager flink.abc.com:8081
-
-
Web UI部署
通过访问flink的web界面,提交job完成部署
-
跨平台部署
-
修改程序的运行环境代码,并指定并行度
//创建跨平台执行环境 val jar = "F:\\flink\\FlinkQuickStart\\target\\FlinkQuickStart-1.0-SNAPSHOT.jar"; val environment = StreamExecutionEnvironment.createRemoteEnvironment("flink.abc.com",8081,jar); //设置并行度 environment.setParallelism(3); -
通过mvn package将程序打包
-
运行main方法完成部署
-
5 Flink运行架构
参考:https://ci.apache.org/projects/flink/flink-docs-release-1.10/concepts/runtime.html
5.1 Tasks/Operator Chains
Flink是一个分布式流计算引擎,该引擎将一个计算job拆分成若干个Task(等价于Spark中的Stage)。每个Task都有自己的并行度,每个并行度都由一个线程表示,因此一个Task底层对应一系列的线程,Flink称为这些线程为该Task的subtask。
与Spark不同的地方在于Spark是通过RDD的依赖关系实现Stage的划分,Flink是通过 Operator Chain的概念实现Task的拆分。该方式将多个算子归并到一个task中,从而优化计算,减少Thread-to-Thread的通信成本。
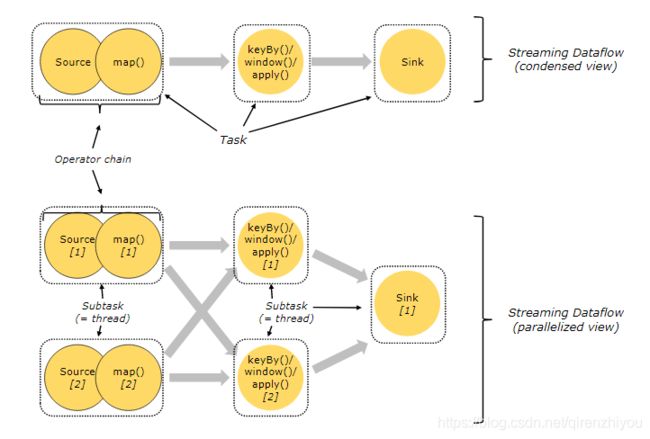
- Task - 等价Spark中的Stage,每个Task都有若个Subtask
- Subtask - 等价于一个线程,是Task中的一个子任务
- Operator Chain - 将多个算子归并到一个Task的机制,归并原则类似于SparkRDD的宽窄依赖
5.2 Job/Task Managers Clients
Flink在运行的过程中,有两种类型的进程组成
Job Manager - (也称为master)负责协调分布式执行。负责任务调度、协调检查点、协调故障恢复等。等价于Spark中的Master+Driver的功能。通常一个集群中至少有1个Active的JobManager,如果在HA模式下其他节点处于StandBy状态。
Task Manager - (也称为Worker) 真正负责Task执行计算节点,同时需要向JobManager汇报自身状态信息和工作负荷。通常一个集群中有若干个TaskManager,但必须至少一个。
Client - Flink中的Client并不是集群计算的一部分,Client仅仅准备和提交dataflow给JobManager。提交完成之后,可以直接退出,也可以保持连接以接收执行进度,因此Client并不负责任务执行过程中调度。Client可以作为触发执行的Java/Scala程序的一部分运行,也可以在命令行窗口中运行。
类似Spark中的Driver,但又特别不同,因为Spark Driver负责任务调度和恢复

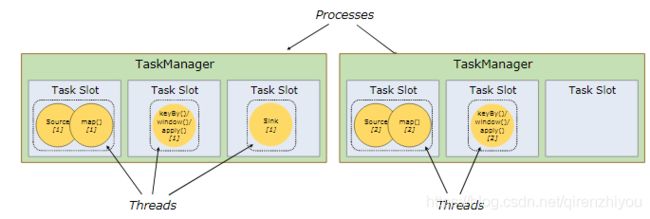
5.3 Task Slots and Resources
每一个Worker(TaskManager)是一个JVM进程,可以执行一个或者多个子任务(Thread/SubTask)。为了控制Worker节点能够接收多少个Task任务,提出了所谓Task slot用于表达一个计算节点的计算能力(每个计算节点至少有一个Task slot)。
每个Task slot表示的是TaskManager计算资源的固定子集。例如,一个TaskManager拥有3个Task slot,则每个Task slot占用TaskManager所管理内存资源的1/3。每个Job启动的时候都拥有固定的Task Slot,这些被分配的Task Slot资源只能被当前job的所有Task使用,不同Job的Task之间不存在资源共享和抢占问题。
但是每个Job会被拆分成若干个Task,每个Task由若干个SubTask构成(取决于Task并行度)。默认Task slot所对应的内存资源只能在同一个Job下的不同Task的subtask间进行共享,也就意味着同一个Task的不同subtask不能运行在同一个Taskslot中。
如果同一个Job下的不同Task的subtask间不能共享slot,就会造成非密集型subtask的阻塞,从而浪费内存。
- 非密集型任务:source()/map()。操作占用内存量小
- 密集型任务:keyBy()/window()/apply()。操作过程中涉及shuffle,会占用大量内存
Flink的底层设计为同一Job下的不同Task的subtask间共享slot。可以将并行度调整从而充分利用资源。将上述示例的并行度从2调整为6,Flink底层会确保heavy subtasks 均衡分布于TaskManager之间的slots
Flink默认行为:同一Job下的不同Task的subtask间共享slot,就意味着一个job运行需要的的Task slot个数应该等于该Job中Task的并行度最大值。当然用户可以设置Task slot的共享策略
在Flink的应用中,用户只需要指定job的并行度即可,无需指定运行需要的资源数


5.4 State Backends
Flink是一个基于状态计算的流计算引擎。存储的key/value状态索引的确切数据结构取决于所选的State Backends。除了定义保存状态的数据结构外,State Backend还实现了获取key/value状态时间点快照并且将该快照储存为checkpoint一部分的逻辑。
Flink定义三种State Backend
-
The MemoryStateBackend:内存
Flink默认实现,通常用于测试,系统会将计算状态存储在JobManager的内存中,但是在实际的生产环境中,由于计算的状态比较多,使用Memory 很容易导致OOM(out of memory)。
-
The FsStateBackend:文件系统,比如hdfs
系统会将计算状态存储在TaskManager的内存中,因此一般用作生产环境,系统会根据CheckPoin机制,将TaskManager状态数据在文件系统上进行备份。如果是超大规模集群,TaskManager内存也可能发生溢出。
-
The RocksDBStateBackend:DB
系统会将计算状态存储在TaskManager的内存中,如果TaskManager内存不够,系统可以使用RocksDB配置本地磁盘完成状态的管理,同时支持将本地的状态数据备份到远程文件系统,因此,RocksDB Backend 是推荐的选择。

5.5 Checkpoint/Savepoints
Checkpoint是由flink定期的,自动的进行数据的持久化(把状态中的数据写入到磁盘(HDFS))。新的checkpoint执行完成之后,会把老的checkpoint丢弃掉
用Data Stream API编写的程序可以从savepoint恢复执行。Savepoint允许在不丢失任何状态的情况下更新程序和Flink集群。
Savepoint是手动触发的checkpoint,它获取程序的快照并将其写入state backend。Checkpoint依赖于常规的检查点机制:在执行过程中个,程序会定期在TaskManager上快照并且生成checkpoint。为了恢复,只需要最后生成的checkpoint。旧的checkpoint可以在新的checkpoint完成后安全地丢弃。
Savepoint与上述的定期checkpoint类似,只是他们由用户触发,并且在新的checkpoint完成时不会自动过期。Savepoint可以通过命令行创建,也可以通过REST API在取消Job时创建。
6 DataStreamAPI
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html
6.1 DataSource
数据源是程序读取数据的来源。用户可以通过StreamExecutionEnvironment.addSource(sourceFunction)将数据源添加到程序中。Flink提供了很多的sourceFunction,用户也可以自定义sourceFunction。可以通过实现SourceFunction接口实现非并行化,也可以通过实现ParallelSourceFunction或者继承RichParallelSourceFunction实现并行化。
6.1.1 File
-
readTextFile(path)
①读取本地文件

②读取分布式文件系统HDFS<dependency> <groupId>org.apache.hadoopgroupId> <artifactId>hadoop-clientartifactId> <version>2.10.0version> dependency> <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-streaming-scala_2.11artifactId> <version>1.10.0version> dependency>//1.创建执行环境 val environment = StreamExecutionEnvironment.getExecutionEnvironment //2.获取数据源 val text = environment.readTextFile("hdfs://flink.abc.com:8020/flink/flink-words") //3.对获取到的数据进行转换 val result = text.flatMap(line => line.split("\\s+")) .map(word => (word, 1)) .keyBy(0) .sum(1) //4.打印结果 result.print() //5.执行job environment.execute("myFlinkJob")
6.1.2 Socket
val text = environment.socketTextStream("flink.abc.com",9999)
6.1.3 Kafka
-
Kafka
#1.启动kafka [root@flink kafka_2.11-2.2.0]# bin/kafka-server-start.sh config/server.properties #2.创建主题 [root@flink kafka_2.11-2.2.0]# bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test #3.查看主题 [root@flink kafka_2.11-2.2.0]# bin/kafka-topics.sh --list --bootstrap-server localhost:9092 #4.发送消息 [root@flink kafka_2.11-2.2.0]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topica #5.消费消息 [root@flink kafka_2.11-2.2.0]# bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic topic01 --from-beginning -
Flink集成Kafka
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html
-
依赖
<dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-connector-kafka_2.11artifactId> <version>1.10.0version> dependency> -
DataSource应用
-
SimpleStringSchema
SimpleStringSchema只会反序列化value
object QuickStart { def main(args: Array[String]): Unit = { val environment = StreamExecutionEnvironment.getExecutionEnvironment val properties = new Properties() properties.setProperty("bootstrap.servers", "flink.abc.com:9092") var text = environment.addSource(new FlinkKafkaConsumer[String]("topic01", new SimpleStringSchema(), properties)); val result = text.flatMap(line => line.split("\\s+")) .map(word => (word, 1)) .keyBy(0) .sum(1) result.print() environment.execute("myFlinkJob") } } -
KafkaDeserializationSchema
通过实现这个接口,可以反序列化key、value、partition、offset等
/** 泛型分别是key/value/partition/offset的类型 */ class MyKafkaDeserializationSchema extends KafkaDeserializationSchema[(String,String,Int,Long)]{ //是否读取到了最后 override def isEndOfStream(nextElement: (String, String, Int, Long)): Boolean = false override def deserialize(record: ConsumerRecord[Array[Byte], Array[Byte]]): (String, String, Int, Long) = { val keyArray: Array[Byte] = record.key() val valueArray: Array[Byte] = record.value() val partition: Int = record.partition() val offset: Long = record.offset() if(keyArray!=null){ (new String(keyArray),new String(valueArray),partition,offset) }else{ ("",new String(valueArray),partition,offset) } } override def getProducedType: TypeInformation[(String, String, Int, Long)] = createTypeInformation[(String, String, Int, Long)] }object QuickStart { def main(args: Array[String]): Unit = { val environment = StreamExecutionEnvironment.getExecutionEnvironment val properties = new Properties() properties.setProperty("bootstrap.servers", "flink.abc.com:9092") var text = environment .addSource(new FlinkKafkaConsumer[(String,String,Int,Long)]("topic01", new MyKafkaDeserializationSchema(), properties)); val result = text.flatMap(line =>line._2.split("\\s+")) .map(word => (word, 1)) .keyBy(0) .sum(1) result.print() environment.execute("myFlinkJob") } } -
JSONKeyValueDeserializationSchema
flink-kafka提供的类,可以直接使用,在使用的时候要求kafka中topic的key、value都必须是json。也可以在使用的过程中,指定是否读取元数据(topic、partition、offset等)
import java.util.Properties import org.apache.flink.api.common.serialization.{DeserializationSchema, SimpleStringSchema} import org.apache.flink.api.common.typeinfo.TypeInformation import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.JsonNode import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.node.ObjectNode import org.apache.flink.streaming.api.scala._ import org.apache.flink.streaming.connectors.kafka.{FlinkKafkaConsumer, KafkaDeserializationSchema} import org.apache.flink.streaming.util.serialization.JSONKeyValueDeserializationSchema import org.apache.kafka.clients.consumer.ConsumerRecord object KafkaDataSourceJob { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment var properties:Properties=new Properties() properties.setProperty("bootstrap.servers","hadoop10:9092") //1.数据必须是json格式 //2.反序列化把json解析成ObjectNode对象 //3.使用反序列化机制,需要指定一个参数:是否需要反序列化元数据 var jsonSchema:JSONKeyValueDeserializationSchema = new JSONKeyValueDeserializationSchema(true) var flinkKafkaConsumer:FlinkKafkaConsumer[ObjectNode] = new FlinkKafkaConsumer("topica",jsonSchema,properties) val dataStream: DataStream[ObjectNode] = environment.addSource(flinkKafkaConsumer) //把objectNode对象转换成JsonNode;jsonNode是根据属性名获取的所有信息;value属性名是反序列化时自动生成的 val value: DataStream[JsonNode] = dataStream.map(objectNode => objectNode.findValue("value")) //把jsonNode对象转换成字符串;字符a是传达过来的json中的key val value1: DataStream[String] = value.map(jsonNode => jsonNode.findValue("a").textValue()) value1.print() environment.execute("KafkaDataSourceJob") } }[root@flink kafka_2.11-2.2.0]# bin/kafka-console-producer.sh --broker-list localhost:9092 --topic topic05 >{"id":101,"name":"xiaohei"}
-
6.2 算子
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/
| 算子 | 描述 |
|---|---|
| map | 映射 |
| flatmap | 映射(压平) |
| filter | 过滤操作 |
| keyby | 分组操作;执行完成之后得到的是keyedStream;keyby算子可以把dataStream转换成keyedStream |
- keyedStream:在flink中,数据是有状态的;数据的状态很多时候和keyedStream结合使用;keyedState(同一个key对应的是同一块状态区域)
6.3 DataSink
支持多种输出方式:打印、文件(HDFS)、redis、kafka…
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/datastream_api.html#data-sinks
生产环境,通常使用flink-connector-filesystem把结果写入到外部文件系统
- 添加
flink-connector-filesystem依赖
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-connector-filesystem_2.11artifactId>
<version>1.10.0version>
dependency>
- 代码实现
object FileDataSinkFlinkConnectorFileSystem {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val text = environment.socketTextStream("flink.abc.com",9999)
var basePath: Path=new Path("hdfs://hadoop10:9000/flink-result")//基础路径
var encoder:Encoder[String]=new SimpleStringEncoder()//字符编码,默认使用的UTF-8
var sinkFunction:SinkFunction[String]=StreamingFileSink
.forRowFormat(basePath,encoder)//①创建一个StreamingFileSink.RowFormatBuilder
.withBucketAssigner(new DateTimeBucketAssigner[String]("yyyy-MM"))//③不是必须,默认子目录是yyyy-MM-dd--HH
.build()//②通过builder对象的build方法构建一个StreamingFileSink
dataStream.addSink(sinkFunction)
environment.execute("myFlinkJob")
}
}
7 状态管理
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/state/state.html
Flink是基于状态的流计算引擎,在Flink中有两种基本类型state:KeyedState和OperatorState
-
KeyedState只能应用在KeyedStream上的操作,每一个keyed operator都会绑定一个或多个状态值。
-
OperatorState又称为non-keyed state,每一个算子都会有对应的operator state。
KeyedState和OperatorState都会以两种方式存储:ManagedState和RawState
-
ManagedState指的是由Flink控制state的数据结构,比如使用内部hash表、RocksDB等,基于此Flink可以更好地在ManagedState基础上进行内存优化和故障恢复。
-
RawState指的是Flink只知道state是一些字节数组,其余一无所知。需要用户自己完成state的序列化以及反序列化,因此Flink不能基于raw state进行内存优化以及故障恢复。
7.1 Managed Keyed State
- 基于dataStream的keyBy算子获取到keyedStream
- keyedStream.map,map自定义map函数
- 自定义MapFunction,继承RichMapFunction
- 实现两个方法(open:初始化/map:计算)
Flink内置以下几种Managed keyed State
| 类型 | 使用场景 | 方法 |
|---|---|---|
| ValueState | 存储单一状态值(只存储一个数据) | update()、value() |
| ListState | 存储集合状态值 | add()、addAll()、get()、update() |
| MapState |
存储Map集合状态值 | put(UK, UV) 、 putAll(Map |
| ReducingState | 存储单一状态值。可自动运算(ReduceFunction) | add(T)、get()、clear() |
| AggregatingState |
存储单一状态值。可自动运算(AggregateFunction); 不要求输入类型和输出类型一致 |
add(IN)、get()、clear() |
-
ValueStategetState(ValueStateDescriptor ) -
ReducingStategetReducingState(ReducingStateDescriptor ) -
ListStategetListState(ListStateDescriptor ) -
AggregatingState -
FoldingState -
MapState
7.1.1 ValueState
import org.apache.flink.api.common.functions.{RichMapFunction, RuntimeContext}
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object ValueStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyMapFunction)
result.print()
environment.execute("ValueStateJob")
}
}
//两个类型参数,分别表示的是输入类型和输出类型
//输入类型:使用这个函数的keyedStream中的数据类型
//输出类型:根据业务需要自己设置类型
class MyMapFunction extends RichMapFunction[(String, Int),String]{
//valueState存储单词的个数
var valueState:ValueState[Int] = _
//open方法,初始化方法:只执行一次
override def open(parameters: Configuration): Unit = {
//valueStateDescriptor:valueState的描述者,在里面声明ValueState中存储数据的类型
//两个参数分别表示:唯一标记以及状态中需要存储数据的类型信息
var valueStateDescriptor:ValueStateDescriptor[Int] = new ValueStateDescriptor[Int]("valueState",createTypeInformation[Int])
valueState = getRuntimeContext.getState(valueStateDescriptor)
}
override def map(value: (String, Int)): String = {
val oldCount: Int = valueState.value()
val newCount: Int = oldCount + value._2//也可以写:oldCount+1
valueState.update(newCount)
value._1+"==的数量是==>"+newCount
}
}
7.1.2 ListState
- 实现用户浏览商品类别统计
import java.lang
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{ListState, ListStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
/**
* 业务系统日志信息格式:用户编号 用户名 访问类别名
* 通过状态完成统计处理
* 根据用户做统计(keyBy(用户));一个用户有可能会访问很多类别:应该使用ListState存储用户访问过的类别
*/
object ListStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//输入数据:用户编号 用户名 访问的类别
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, String, String), Tuple] = dataStream
.map(_.split("\\s+"))
.map(array => (array(0), array(1), array(2)))
.keyBy(0)
val result: DataStream[(String, String)] = keyedStream.map(new MyListStateMapFunction)
result.print()
environment.execute("ListStateJob")
}
}
class MyListStateMapFunction extends RichMapFunction[(String, String, String),(String,String)]{
var listState:ListState[String]=_
override def open(parameters: Configuration): Unit = {
listState=getRuntimeContext.getListState(new ListStateDescriptor[String]("lsd",createTypeInformation[String]))
}
override def map(value: (String, String, String)): (String, String) = {
//从状态中获取到数据,把新进来的数据添加上,然后去重;然后再存入状态中
val oldIterable: lang.Iterable[String] = listState.get()
val scalaList: List[String] = oldIterable.asScala.toList
val list: List[String] = scalaList :+ value._3
val distinctList: List[String] = list.distinct
listState.update(distinctList.asJava)//upate方法需要util.list;通过asJava转换
(value._1+":"+value._2,distinctList.mkString(" | "))
}
}
7.1.3 MapState
- 统计用户浏览商品类别以及该类别的次数
import org.apache.flink.api.common.functions.RichMapFunction
import org.apache.flink.api.common.state.{MapState, MapStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
import scala.collection.JavaConverters._
object MapStateJob {
def main(args: Array[String]): Unit = {
//统计用户浏览商品类别以及该类别的次数
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, String), Tuple] = dataStream
.map(_.split("\\s+"))
.map(array => (array(0), array(1)))
.keyBy(0)
keyedStream.map(new MyMapStateMapFunction).print()
environment.execute("MapStateJob")
}
}
class MyMapStateMapFunction extends RichMapFunction[(String, String),String]{
var mapState:MapState[String,Int] = _
override def open(parameters: Configuration): Unit = {
mapState = getRuntimeContext.getMapState(new MapStateDescriptor[String,Int]("msd",classOf[String],classOf[Int]))
}
override def map(value: (String, String)): String = {
var count:Int = 1
//如果类别已经存在,访问次数加1
//如果类别不存在,访问次数为1
if(mapState.contains(value._2)){
count = mapState.get(value._2)+1
}
mapState.put(value._2,count)
value._1+"=>"+mapState.entries().asScala.map(s=>s.getKey+":"+s.getValue).toList.mkString("|")
}
}
7.1.4 ReducingState
- 存储单一值,要求输入类型和输出类型一致
- 自定运算:基于提供的运算函数完成自动运算
import org.apache.flink.api.common.functions.{ReduceFunction, RichMapFunction}
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object ReducingStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[(String, Int), Tuple] = dataStream
.flatMap(_.split("\\s+"))
.map((_, 1))
.keyBy(0)
val result: DataStream[String] = keyedStream.map(new MyReducingStateMapFunction)
result.print()
environment.execute("ReducingStateJob")
}
}
class MyReducingStateMapFunction extends RichMapFunction[(String, Int),String]{
var reducingState:ReducingState[Int] = _
override def open(parameters: Configuration): Unit = {
var reduceFunction:ReduceFunction[Int]=new ReduceFunction[Int] {
override def reduce(value1: Int, value2: Int): Int = value1+value2
}
var reducingStateDescriptor:ReducingStateDescriptor[Int]=new ReducingStateDescriptor[Int]("rsd",reduceFunction,classOf[Int])
reducingState=getRuntimeContext.getReducingState(reducingStateDescriptor)
}
override def map(value: (String, Int)): String = {
reducingState.add(value._2)//把单词的个数放入到reducingState中,会通过定义的运算函数reduceFunction完成计算处理;
//状态中存储的就是计算完成之后的结果
val count: Int = reducingState.get()
value._1+"的个数是:"+count
}
}
7.1.5 AggregatingState
- 实时计算用户的订单平均金额;
- 输入数据(业务系统日志信息)就是订单信息(订单编号 用户编号 订单金额)
import org.apache.flink.api.common.functions.{AggregateFunction, RichMapFunction}
import org.apache.flink.api.common.state.{AggregatingState, AggregatingStateDescriptor}
import org.apache.flink.api.java.tuple.Tuple
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala._
object AggregatingStateJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//数据:订单编号 用户编号 订单金额
val dataStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
val keyedStream: KeyedStream[OrderItem, Tuple] = dataStream
.map(_.split("\\s+"))
.map(array=>new OrderItem(array(0).toInt,array(1).toInt,array(2).toDouble))
.keyBy("userId")
val result: DataStream[String] = keyedStream.map(new MyAggregatingStateMapFunction)
result.print()
environment.execute("AggregatingStateJob")
}
}
class MyAggregatingStateMapFunction extends RichMapFunction[OrderItem,String]{
//两个类型参数分别是:订单详情对象(IN:输入类型),订单平均金额(OUT:输出类型)
var aggregatingState:AggregatingState[OrderItem,Double] = _
override def open(parameters: Configuration): Unit = {
var aggregateFunction:AggregateFunction[OrderItem,(Double,Int),Double]=new AggregateFunction[OrderItem,(Double,Int),Double] {
//初始化,创建一个ACC;给一个初始化
override def createAccumulator(): (Double, Int) = (0.0,0)
//运算处理,每执行一次aggregatingState.add(value),就会执行一次这个方法
//方法有两个参数,value:传递过来的值;accumulator:上一次计算完成的结果
//方法的返回值,作为下一次计算的accumulator
override def add(value: OrderItem, accumulator: (Double, Int)): (Double, Int) = {
(accumulator._1+value.money,accumulator._2+1)
}
//获取到中间计算结果然后运算处理生成OUT
//方法参数就是:中间计算结果;方法返回值就是aggregatingState中存储的数据,通过aggregatingState.get获取到
override def getResult(accumulator: (Double, Int)): Double = accumulator._1/accumulator._2
//合并
override def merge(a: (Double, Int), b: (Double, Int)): (Double, Int) = (a._1+b._1,a._2+b._2)
}
//三个类型参数,中间的那个表示计算中间的数据类型,(订单总金额,订单个数)
var aggregatingSD = new AggregatingStateDescriptor[OrderItem,(Double,Int),Double]("asd",aggregateFunction,classOf[(Double,Int)])
aggregatingState = getRuntimeContext.getAggregatingState(aggregatingSD)
}
override def map(value: OrderItem): String = {
//把数据放入aggregatingState,通过aggregateFunction进行自动运算
aggregatingState.add(value)
//从aggregatingState中获取结果;获取到计算完成之后的订单平均金额
val avg: Double = aggregatingState.get()
value.userId+"订单平均金额是:"+avg
}
}
case class OrderItem(orderId:Int,userId:Int,money:Double)
7.2 TimeToLive(TTL)
7.2.1 基本使用
TTL需要设置内容:
- 时间
- 时间更新机制(对比session失效时间)
- 过期数据的可见性机制(过期数据是否可以重新获取)
在Flink中,支持对所有的keyed state设置存活时间。该特性默认是关闭的,一旦开启并且状态值已经过期,Flink将会尽最大努力清除所存储的状态值。
TTL支持单一值失效特性,意味着ListState中的每一个元素和MapState中的每一个entry都会有单独的失效时间。
要使用stateTTL,首先需要构建一个StateTtlConfig 配置对象。然后通过调用StateDescriptor对象中的enableTimeToLive方法并且将配置对象传递过去来开启TTL机制
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))//①
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)//②
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)//③
.build()
val valueStateDescriptor = new ValueStateDescriptor[String]("valueState", classOf[String])
-
①Time-To-Live的值,必须设置,可以根据需要设置对应时间值
-
②TTL的时间更新机制,对比session的失效时间,默认是OnCreateAndWrite
StateTtlConfig.UpdateType.OnCreateAndWrite - 创建和写入更新时间 StateTtlConfig.UpdateType.OnReadAndWrite - 读取和写入更新时间 -
③state的可见性配置,即过期数据处理机制,过期的但是还没有被清理掉的数据是否可以获取到,默认值NeverReturnExpired
StateTtlConfig.StateVisibility.NeverReturnExpired - 过期数据永不返回 StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp - 过期数据如果还没有被清理就返回
- 一旦开启TTL机制,系统为每个存储的状态数据额外开辟8个字节的空间,用来存储state的时间戳
- TTL目前仅支持processing time
- 如果程序一开始没有启用TTL,重启服务开启了TTL,则服务在故障恢复时StateMigrationException
7.2.2 垃圾回收机制
Cleanup of Expired State:过期状态的清理机制–垃圾回收
- 恢复数据或者启动Flink时,把所有过期的状态清理掉
- 设置Key的个数,当数据到达指定个数的时候,对过期数据进行清理
- statebackend使用RocksDB时,通过压实机制完成清理
1.9以及之前版本:
在默认情况下,如果过期数据没有被读取,就不会被删除。很有可能导致过期数据越来越大而占用太多内存。
可以调用StateTtlConfig.Builder的.cleanupInBackground方法开启后台清理
1.10版本:
如果配置了state backend,则在后台定期进行垃圾回收。可以通过以下API禁用后台清理
import org.apache.flink.api.common.state.StateTtlConfig val ttlConfig = StateTtlConfig .newBuilder(Time.seconds(1)) .disableCleanupInBackground() .build()
全本快照
Cleanup in full snapshot:全本快照机制,在系统恢复或者启动的时候, 加载状态数据,此时会将过期的数据删除
import org.apache.flink.api.common.state.StateTtlConfig
import org.apache.flink.api.common.time.Time
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupFullSnapshot()
.build()
只有Flink服务重启的时候才会清理过期数据
增量清除
Incremental cleanup:增量处理,增量清理策略,在用户每一次读取或者写入状态数据的时候,该清理策略就会运行一次。系统的state backend会保存所有状态的一个全局迭代器。每一次访问状态或者/和记录处理时,该迭代器就会增量迭代一个批次的数据,检查是否存在过期的数据,如果存在就删除
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupIncrementally(10, true)
.build()
该策略需要两个参数
cleanupSize:一次检查的key的数量
runCleanupForEveryRecord:是否每一次record processing都会触发incremental cleanup。如果为false,就表示只有访问状态时才触发incremental cleanup;true则表示访问状态以及记录处理都会触发incremental cleanup
- 如果没有状态访问或者记录处理,过期的数据就不会删除,会被持久化
- incremental cleanup需要花费时间,从而增加了record processing的延迟
- 目前incremental cleanup仅支持 Heap state backend。如果是RocksDB,该机制不起作用
压实机制
Cleanup during RocksDB compaction:压实机制,如果使用的是RocksDB作为state backend,Flink将会通过Compaction filter实现后台清理。Compaction(压实机制) filter会检查状态的时间戳以获取剩余存活时间并把过期数据清除掉
import org.apache.flink.api.common.state.StateTtlConfig
val ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.cleanupInRocksdbCompactFilter(1000)
.build()
参数queryTimeAfterNumEntries表示处理多少个key之后去获取时间。以对比存储的时间戳,将过期的数据删除掉
频繁的更新时间戳会提高清理速度。但是由于采用JNI调用本地代码,会降低压实性能。默认情况,每处理1000个key,RocksDB backend会查询一次当前时间戳从而清理过期数据
RocksDB是一个基于内存+磁盘的嵌入式的轻量级的NoSQL产品,底层维护一张HashTable。所有的记录都是顺序追加到磁盘,最新状态的数据存储在内存中。磁盘中储存历次操作的所有数据信息,RocksDB不支持更新磁盘。但是RocksDB底层有一套Compaction机制(压实机制),用于合并磁盘文件,以防止文件过大
在Flink1.10之前,RocksDB的CompactionFilter特性是默认关闭的,需要使用时,在flin-conf.yaml配置文件中开启
state.backend.rocksdb.ttl.compaction.filter.enabled: true
7.3 Checkpoint&Savepoint
Flink是一个有状态的流计算引擎,状态的管理和容错是非常重要的。为了程序的健壮性,Flink提出了Checkpoint机制,该机制用于持久化计算节点的状态数据,从而实现Flink故障恢复。
Checkpoint机制指Flink会定期将状态数据持久化到远程文件系统,比如HDFS(这取决于state backend)。
JobManager负责checkpoint的发起以及协调。JobManager节点会定期向TaskManager节点发送Barrier(实际上是JobManager创建的CheckpointCoordinator),TaskManager接收到Barrier信号,会把Barrier信号作为数据流的一部分传递给所有算子。每一个算子接收到Barrier信号后会预先提交自己的状态信息并且给JobManger应答,同时会将Barrier信号传递给下游算子。JobManager接收到所有算子的应答后才认定此次Checkpoint是成功的,并且会自动删除上一次Checkpoint数据。否则如果在规定的时间内没有收到所有算子的应答,则认为本次Checkpoint快照制作失败 。
Flink分布式快照的核心之一是数据栅栏,这些barrier被插入数据流,作为数据流数据的一部分,barrier不会干扰正常的数据流,一个barrier会把数据分割成两个部分,一部分进入当前快照,另一部分进入下一个快照。每个barrier都带有快照的id,并且 barrier 之前的数据都进入了此快照。多个barrier会出现数据流中,也就是会产生多个快照。
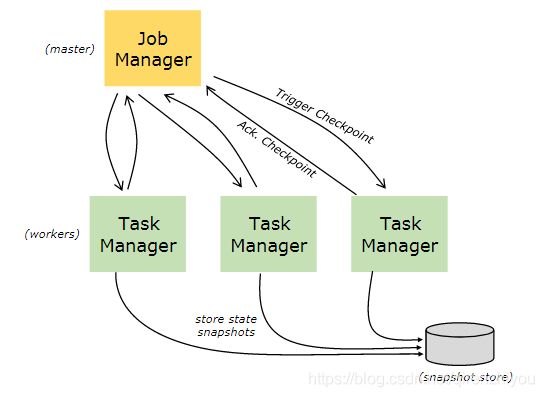

Savepoint是手动触发的Checkpoint,它获取程序的快照并将其写入state backend。
Checkpoint依赖于常规的检查点机制:在执行过程中,程序会定期在TaskManager上快照并且生成checkpoint。为了恢复,只需要最后生成的checkpoint。旧的checkpoint可以在新的checkpoint完成后安全地丢弃。
Savepoint与上述的定期checkpoint类似,由用户触发,并且在新的checkpoint完成时不会自动过期(即不会把上一次的savepoint替换掉)。Savepoint可以通过命令行创建,也可以通过REST API在取消Job时创建。
默认情况下,Flink的Checkpoint机制是禁用的,如果需要开启,可以通过以下API完成
//n表示每间隔多少毫秒执行一次checkpoint
StreamExecutionEnvironment.enableCheckpointing(n)
可以通过以下参数更精准地控制Checkpoint
//5000:每间隔5000毫秒执行一次checkpoint。
//CheckpointingMode.EXACTLY_ONCE:checkpointing模式是精准一次
//checkpointing模式还有一个值是CheckpointingMode.AT_LEAST_ONCE
environment.enableCheckpointing(5000,CheckpointingMode.EXACTLY_ONCE)
environment.getCheckpointConfig.setCheckpointTimeout(4000)
//两次检查点间隔不得小于2秒,优先级高于checkpoint interval
environment.getCheckpointConfig.setMinPauseBetweenCheckpoints(2000)
//允许checkpoint失败的参数,默认值是0。取代了setFailOnCheckpointingErrors(boolean)
environment.getCheckpointConfig.setTolerableCheckpointFailureNumber(2)
//RETAIN_ON_CANCELLATION:任务取消时,没有加savepoint,检查点数据保留
//DELETE_ON_CANCELLATION:任务取消时,检查点数据删除(不建议使用)
environment.getCheckpointConfig.enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION)
7.4 State backend
State backend指定了状态数据(检查点数据)存储的位置以及如何存储。state backend有两种配置方式
-
每一个job单独配置state backend
val env = StreamExecutionEnvironment.getExecutionEnvironment() env.setStateBackend(...)//只针对这一个job -
在
flink-conf.yaml中配置所有job使用的state backend#============================================================================== # Fault tolerance and checkpointing #============================================================================== # The backend that will be used to store operator state checkpoints if # checkpointing is enabled. # # Supported backends are 'jobmanager', 'filesystem', 'rocksdb', or the #. # state.backend: filesystem # Directory for checkpoints filesystem, when using any of the default bundled # state backends. # # state.checkpoints.dir: hdfs://namenode-host:port/flink-checkpoints state.checkpoints.dir: hdfs:///flink-checkpoints # Default target directory for savepoints, optional. # # state.savepoints.dir: hdfs://namenode-host:port/flink-checkpoints state.savepoints.dir: hdfs:///flink-checkpoints # Flag to enable/disable incremental checkpoints for backends that # support incremental checkpoints (like the RocksDB state backend). # state.backend.incremental: false配置文件配置完成之后,重新启动Flink,检查全局state backend配置是否成功
-
停止flink
[root@flink flink-1.10.0]# bin/stop-cluster.sh -
启动flink
[root@flink flink-1.10.0]# bin/start-cluster.sh -
web-UI界面查看相关日志信息
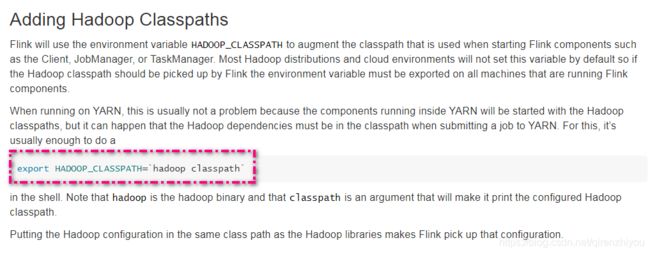
因为state backend需要将数据同步到HDFS,所以Flink需要和Hadoop集成。需要在环境变量中配置HADOOP_CLASSPATH
vi /etc/profile
export HADOOP_CLASSPATH=`hadoop classpath`source /etc/profile
-
检查点以及状态完成数据故障恢复整体思路
-
在flink配置文件中配置state backend
-
在flink代码中开启checkpoint
-
把flink代码打包,通过flink UI界面传输到flink环境中执行
-
确认checkpoint的配置是否生效
-
程序执行计算结果,在taskManager中查看
-
取消掉job
-
到hdfs中复制生成的checkpoint路径
-
重新启动flink程序,在checkpoint的位置,输入恢复数据需要的hdfs路径
7.5 Broadcast
信用卡反欺诈系统:https://ci.apache.org/projects/flink/flink-docs-release-1.10/zh/getting-started/walkthroughs/datastream_api.html

广播状态是Flink提供的第三种状态共享的场景,通常需要将一个吞吐量比较低的流中的状态数据进行广播 ,给下游的任务,另外一个流可以以只读的形式读取广播状态
- 模型思路
- 一个高吞吐量流(评论、订单)
- 一个低吞吐量流(排除关键字、优惠信息)
- 通过低吞吐量流,形成一个广播流(dataStream.broadcast)
- 通过高吞吐量流连接广播流,形成广播连接流
- 通过广播连接流的process算子,完成业务处理
- process算子processFunction
- 定义processFunction;
- 高吞吐量流是非keyedStream,继承BroadcastProcessFunction
- 高吞吐量流是keyedStream,继承KeyedBroadcastProcessFunction
- 重写两个方法;两个方法是处理两个流的方法(高吞吐量流、广播流);在处理高吞吐量流的方法里面,可以以只读的方式获取到广播流中的数据
7.5.1 NonKeyedStreamBroadcast
继承BroadcastProcessFunction
processElement
可以获取到低吞吐量流广播过来的状态,处理高吞吐量流相关的业务逻辑
processBroadcastElement
用来处理广播流,即对低吞吐量流进行处理
业务需求:把评论中的某些内容过滤掉
/**
* 需求:把评论中的某些关键词用**代替
* 分析:通过广播流完成对应数据处理
* 1. 评论是高吞吐流
* 2. 要排除的关键词是低吞吐量流
* 评论内容不需要做keyBy
*
* 要保证从状态中获取的广播流的数据信息,就是存进去的广播流的数据
* 应该在往状态中放的时候,和从状态中获取的时候,使用的是同一个数据区域
* 在两个方法中,使用相同的MapStateDescriptor
*/
object NonKeyedStreamBroadcastJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//高吞吐量流;评论内容数据流
val pingLunStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
//低吞吐量流;要排除关键词数据流
val keywordStream: DataStream[String] = environment.socketTextStream("hadoop10", 8888)
//低吞吐量流通过broadcast方法形成广播流,需要MapStateDescriptor
var msd:MapStateDescriptor[String,String] = new MapStateDescriptor[String,String]("msd",classOf[String],classOf[String])
val broadcastStream: BroadcastStream[String] = keywordStream.broadcast(msd)
//高吞吐量流连接广播流;形成广播连接流
val broadcastConnectedStream: BroadcastConnectedStream[String, String] = pingLunStream.connect(broadcastStream)
//通过广播连接流process算子完成数据处理
//数据处理通过broadcastProcessFunction完成
var myBroadcastProcessFunction:MyBroadcastProcessFunction = new MyBroadcastProcessFunction(msd);
val result: DataStream[String] = broadcastConnectedStream.process(myBroadcastProcessFunction)
result.print()
environment.execute("NonKeyedStreamBroadcastJob")
}
}
/**
* 高吞吐量流是非keyedStream;需要继承BroadcastProcessFunction
* 参数:高吞吐量流数据类型、低吞吐量流数据类型、输出类型
*/
class MyBroadcastProcessFunction(msd:MapStateDescriptor[String,String]) extends BroadcastProcessFunction[String,String,String]{
//处理高吞吐量流
override def processElement(value: String, ctx: BroadcastProcessFunction[String, String, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val readOnlyBroadcastState: ReadOnlyBroadcastState[String, String] = ctx.getBroadcastState(msd)
//可以通过readOnlyBroadcastState获取到下面方法中放进去的数据
if(readOnlyBroadcastState.contains("keyword")){
//如果状态中有需要排除的关键词,然后获取
val keyword: String = readOnlyBroadcastState.get("keyword")
val newValue: String = value.replace(keyword, "**")
out.collect(newValue)
}else{
out.collect(value)
}
}
//处理广播流低,吞吐量流
override def processBroadcastElement(value: String, ctx: BroadcastProcessFunction[String, String, String]#Context, out: Collector[String]): Unit = {
val broadcastState: BroadcastState[String, String] = ctx.getBroadcastState(msd)
broadcastState.put("keyword",value)
}
}
7.5.2 KeyedStreamBroadcast
继承KeyedBroadcastProcessFunction
需求: 电商平台,用户在某一类别下消费总金额达到一定数量,会有奖励
分析:
-
不同类别会有对应的奖励机制,需要把这个奖励机制广播给用户消费对应的流
-
用户消费是一个高吞吐量流
-
通过用户消费流连接奖励机制流,然后通过process处理
-
用户消费流根据用户标记以及类别分组,流是KeyedStream,ProcessFunction选KeyedBroadcastProcessFunction
-
在KeyedBroadcastProcessFunction中完成奖励机制以及用户消费统计、分析、处理
object KeyedStreamBroadcastJob {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
//高吞吐量流,订单流,格式:订单编号 用户编号 商品类别 订单总金额
val orderStream: DataStream[String] = environment.socketTextStream("hadoop10", 9999)
//按照用户编号与商品类别分组
val order: KeyedStream[OrderItem, Tuple] = orderStream
.map(_.split("\\s+"))
.map(array => new OrderItem(array(0), array(1), array(2), array(3).toDouble))
.keyBy("userId", "category")
//低吞吐量流,优惠信息,格式:商品类别 金额 优惠金额
val discountDataStream: DataStream[String] = environment.socketTextStream("hadoop10", 8888)
//映射
val disCountStream: DataStream[DisCount] = discountDataStream
.map(_.split("\\s+"))
.map(array => new DisCount(array(0), array(1).toDouble, array(2).toDouble))
//低吞吐量流形成广播流
val mapStateDescriptor: MapStateDescriptor[String,List[DisCount]] = new MapStateDescriptor[String,List[DisCount]]("msd",classOf[String],classOf[List[DisCount]])
val broadcastStream: BroadcastStream[DisCount] = disCountStream.broadcast(mapStateDescriptor)
//订单流连接广播流,形成广播连接流
val broadcastConn: BroadcastConnectedStream[OrderItem, DisCount] = order.connect(broadcastStream)
//广播连接流调用process方法
val myKeyedBroadcastProcessFunction: MyKeyedBroadcastProcessFunction = new MyKeyedBroadcastProcessFunction(mapStateDescriptor)
val result: DataStream[String] = broadcastConn.process(myKeyedBroadcastProcessFunction)
result.print()
environment.execute("KeyedStreamBroadcastJob")
}
}
class MyKeyedBroadcastProcessFunction(mapStateDescriptor: MapStateDescriptor[String,List[DisCount]]) extends KeyedBroadcastProcessFunction[String,OrderItem,DisCount,String]{
//需要使用状态存储每个Key下订单总金额
var reduceState:ReducingState[Double] = _
override def open(parameters: Configuration): Unit = {
var reduceFunction: ReduceFunction[Double] = new ReduceFunction[Double] {
override def reduce(value1: Double, value2: Double): Double = value1+value2
}
var rsd: ReducingStateDescriptor[Double] = new ReducingStateDescriptor[Double]("rsd",reduceFunction,classOf[Double])
reduceState = getRuntimeContext.getReducingState(rsd)
}
override def processElement(value: OrderItem, ctx: KeyedBroadcastProcessFunction[String, OrderItem, DisCount, String]#ReadOnlyContext, out: Collector[String]): Unit = {
val readOnlyBroadcastState: ReadOnlyBroadcastState[String, List[DisCount]] = ctx.getBroadcastState(mapStateDescriptor)
reduceState.add(value.money)
val totalMoney: Double = reduceState.get()
if(readOnlyBroadcastState.contains(value.category)){
//这个商品类别已经有优惠
val list: List[DisCount] = readOnlyBroadcastState.get(value.category)
Breaks.breakable{
list.foreach(s=>{
if(totalMoney>=s.money){
out.collect(s"${value.userId}的总金额达到${s.money},可以享受优惠${s.discount}")
Breaks.break()
}
})
}
}else{
out.collect(s"${value.category}类别还没有优惠信息")
}
}
override def processBroadcastElement(value: DisCount, ctx: KeyedBroadcastProcessFunction[String, OrderItem, DisCount, String]#Context, out: Collector[String]): Unit = {
val broadcastState: BroadcastState[String, List[DisCount]] = ctx.getBroadcastState(mapStateDescriptor)
//处理低吞吐量优惠流
if(broadcastState.contains(value.category)){
//说明状态中已经存储这个商品类别的优惠信息
val list: List[DisCount] = broadcastState.get(value.category)
//将优惠信息添加到状态中
val list1: List[DisCount] = list :+ value
val list2: List[DisCount] = list1.distinct
val list3: List[DisCount] = list2.sortBy(_.money).reverse
broadcastState.put(value.category,list3)
}else{
//说明状态中还没有存储这个商品类别的优惠信息
broadcastState.put(value.category,List(value))
}
}
}
//订单
case class OrderItem(orderId:String,userId:String,category:String,money:Double)
//优惠信息
case class DisCount(category:String,money:Double,discount:Double)
7.6 Queryable State

7.6.1 Architecture

在Flink的状态可查询的架构中,存在三个基本概念
QueryableStateClient:第三方程序,不是flink架构中内容
QueryableStateClientProxy:flink架构中的一部分,用来处理客户端请求
QueryableStateServer:flink架构中一部分,查询状态服务端(可查询的状态都在这里面)
flink状态可查询的执行
客户端发送状态可查询请求给taskManager中的QueryableStateClientProxy
通过key查询对应的状态数据
queryableStateClientProxy根据key到jobManager中获取到这个key对应的状态存储在哪个taskmanager上面
根据key到指定的taskmanager上面的queryableStateServer中获取到这个key对应的状态
7.6.2 ActivatingQueryableState
-
把Flink的opt目录下的flink-queryable-state-runtime_2.11-1.10.0.jar文件复制到Flink的lib目录下
[root@flink flink-1.10.0]# pwd /opt/install/flink-1.10.0 [root@flink flink-1.10.0]# cp opt/flink-queryable-state-runtime_2.11-1.10.0.jar lib -
conf/flink-conf.yaml中添加配置
queryable-state.enable: true -
重新启动Flink
在taskManager日志文件中看到以下信息,就说明已激活Queryable State

7.6.3 MakingStateQueryable
两种方式让state在外部系统中可见
- 创建QueryableStateStream,该Stream只充当一个sink,将数据存储到queryablestate中
- 通过stateDescriptor.setQueryable(String queryableStateName)方法,将state可查
(1)Queryable State Stream
通过KeyedStream对象asQueryableState(stateName, stateDescriptor)方法,得到QueryableStateStream对象,这个对象提供的状态值是可查询的
// ValueState
QueryableStateStream asQueryableState(String queryableStateName,ValueStateDescriptor stateDescriptor)
// Shortcut for explicit ValueStateDescriptor variant
QueryableStateStream asQueryableState(String queryableStateName)
// FoldingState
QueryableStateStream asQueryableState(String queryableStateName,FoldingStateDescriptor stateDescriptor)
// ReducingState
QueryableStateStream asQueryableState(String queryableStateName,ReducingStateDescriptor stateDescriptor)
返回的QueryableStateStream可视为sink,无法进一步转换。在内部将QueryableStateStream转换为一个operator,这个operator将所有传入记录用来更新queryable state实例。更新逻辑在调用asQueryableState方法时传递的StateDescriptor参数对象中完成。在如下程序中,Keyed Stream的所有记录在底层都是通过value state.update(value)更新状态实例:
stream.keyBy(0).asQueryableState("query-name")
object WordCountQueryableState {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
var reducingStateDescriptor = new ReducingStateDescriptor[(String,Int)]("reducingStateDescriptor",new ReduceFunction[(String,Int)] {
override def reduce(value1: (String, Int), value2: (String, Int)): (String, Int) = {
(value1._1,(value1._2+value2._2))
}
},createTypeInformation[(String,Int)])
dataStream.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.asQueryableState("wordCountqueryableStateName",reducingStateDescriptor)
environment.execute("wordCountQueryableStateJob")
}
}
(2)Managed Keyed State
通过StateDescriptor.setQueryable(String queryableStateName)方法实现managed keyed State状态可查
class MyMapFunction extends RichMapFunction[(String,Int),(String,Int)]{
var valueState:ValueState[Int]=_
override def open(parameters: Configuration): Unit = {
val runtimeContext = getRuntimeContext
var valueStateDescriptor=new ValueStateDescriptor[Int]("valueStateDescriptor",createTypeInformation[Int])
valueStateDescriptor.setQueryable("WordCountQueryableStateManagedKeyedStateName")
valueState=runtimeContext.getState(valueStateDescriptor)
}
override def map(value: (String, Int)): (String, Int) = {
val oldValue = valueState.value()
var newValue = valueState.update(oldValue+value._2)
(value._1,valueState.value())
}
}
object WordCountQueryableStateManagedKeyedState {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
dataStream.flatMap(line=>line.split("\\s+"))
.map(word=>(word,1))
.keyBy(0)
.map(new MyMapFunction)
.print()
environment.execute("WordCountQueryableStateManagedKeyedState")
}
}
(3)Querying State
-
引入依赖
<dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-coreartifactId> <version>1.10.0version> dependency> <dependency> <groupId>org.apache.flinkgroupId> <artifactId>flink-queryable-state-client-javaartifactId> <version>1.10.0version> dependency> -
代码实现
val client = new QueryableStateClient("flink.abc.com", 9069) var reduceFunction:ReduceFunction[(String,Int)] = new ReduceFunction[(String,Int)] { override def reduce(value1: (String, Int), value2: (String, Int)): (String, Int) = { (value1._1,(value1._2+value2._2)) } } var rsd = new ReducingStateDescriptor[(String,Int)]("rsd",reduceFunction,classOf[(String,Int)]) var jobId = JobID.fromHexString("1f8ade8cf2d956bf553f0348a79c3f6e") val kvState: CompletableFuture[ReducingState[(String, Int)]] = client.getKvState(jobId,"queryName","this",classOf[String],rsd) //同步获取数据 //val reducingState: ReducingState[(String, Int)] = completableFuture.get() //print(reducingState.get()) //client.shutdownAndWait(); //异步获取数据 completableFuture.thenAccept(new Consumer[ReducingState[(String,Int)]] { override def accept(t: ReducingState[(String, Int)]): Unit = { print(t.get()) } }) Thread.sleep(1000) client.shutdownAndWait()
如果创建单独的module,还需要引入以下依赖才可以正常运行客户端程序
<dependency>
<groupId>org.apache.flinkgroupId>
<artifactId>flink-streaming-scala_2.11artifactId>
<version>1.10.0version>
dependency>
7.6.4 状态可查询接口
供第三方程序直接调用
- 把flink服务器中的相关信息,写在配置文件中,方便维护
- 把用户提供的key作为接口的参数
@RestController
@RequestMapping("/state")
public class StateController {
@Value("${state.queryable.hostname}")
private String hostname;
@Value("${state.queryable.port}")
private int port;
@Value("${state.queryable.jobID}")
private String id;
@Value("${state.queryable.name}")
private String queryableStateName;
@RequestMapping(value = "/queryState/{key}",method = RequestMethod.GET)
public String queryState(@PathVariable("key") String key) throws Exception {
//查询状态中的数据
QueryableStateClient client = new QueryableStateClient(hostname,port);
//jobId:运行的job的id;
JobID jobId=JobID.fromHexString(id);
String queryName="wordCountQueryable";//设置状态可查询时的名字
TypeInformation<String> keyTypeInfo=TypeInformation.of(String.class);//key的类型信息
ValueStateDescriptor<Integer> stateDescriptor=new ValueStateDescriptor<Integer>("VSD",Integer.class);
CompletableFuture<ValueState<Integer>> kvstate = client.getKvState(jobId, queryName, key, keyTypeInfo, stateDescriptor);
ValueState<Integer> valueState = kvstate.get();
Integer value = valueState.value();
return value+"";
}
}
server:
port: 6099
#状态可查询参数
#四个参数分别是:服务器主机名/ip、端口号(queryableStateProxyServer)、jobID、queryableStateName
state:
queryable:
hostname: hadoop10
port: 9069
jobID: 4db2374d58e970276125e6dc6b5d943b
name: wordCountQueryable
QueryableStateClient client = new QueryableStateClient("hadoop10", 9069);
JobID jobID = JobID.fromHexString("fed814324be8a38ee7155d8f279fac54");
String queryName = "query";
TypeInformation<String> keyType = TypeInformation.of(String.class);
ValueStateDescriptor<Integer> stateDescriptor = new ValueStateDescriptor<>("vsd", Integer.class);
CompletableFuture<ValueState<Integer>> kvState = client.getKvState(jobID, queryName, "a", keyType, stateDescriptor);
ValueState<Integer> valueState = kvState.get();
System.out.println(valueState.value());
8 Windows(流计算核心)
8.1 Window basic
https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/stream/operators/windows.html
窗口是处理无限流的核心,Windows将流分成有限大小的“bucket”,可以在上面进行计算。

Flink将窗口划分成了两大类:keyed窗口和non-keyed窗口
Keyed windows
stream
.keyBy(...) <- keyed versus non-keyed windows
.window(...) <- required: "assigner"//分配器,用来指定如何生成窗口
[.trigger(...)] <- optional: "trigger" (else default trigger)//触发器,何时开始计算
[.evictor(...)] <- optional: "evictor" (else no evictor)//剔除器,数据是否需要剔除
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"//window function,计算
[.getSideOutput(...)] <- optional: "output tag"
Non-Keyed Windows
stream
.windowAll(...) <- required: "assigner"
[.trigger(...)] <- optional: "trigger" (else default trigger)
[.evictor(...)] <- optional: "evictor" (else no evictor)
[.allowedLateness(...)] <- optional: "lateness" (else zero)
[.sideOutputLateData(...)] <- optional: "output tag" (else no side output for late data)
.reduce/aggregate/fold/apply() <- required: "function"
[.getSideOutput(...)] <- optional: "output tag"
keyed windows与non-keyed windows的唯一区别就是,keyedStream上通过keyBy().window()完成,non-keyedStream通过windowAll()
8.2 Window Lifecycle
当应该属于某一个窗口的第一个元素到达时,该窗口被创建。当时间超过了窗口的结束时间加上允许的延迟时间时,窗口被彻底删除。Flink只删除基于时间的窗口,而不删除像全局窗口这样的其他类型的窗口。
每个window都会绑定一个function和一个trigger,function作用是对窗口中的内容进行计算,trigger作用是决定什么时候开始应用function进行计算—>触发器决定了窗口什么时候处于就绪状态
除了function和trigger之外,还可以指定evictor。evictor的作用是在trigger触发之后到function运行之前和/或者运行之后这段时间间,把window中的元素删除
8.3 Keyed vs Non-Keyed
Keyed Windows:keyed Stream根据key将原始流切分成多个逻辑keyed Stream,每个逻辑keyed Stream都可以独立于其他任务进行处理,所以Keyed Stream允许多个并行任务执行窗体计算。同一个key的所有元素被分发到同一个并行任务中。简而言之,在某一个时刻,会触发多个window任务,取决于Key的种类。
Non-Keyed Windows:没有key的概念,不会将原始流拆分成多个逻辑流,所有窗口逻辑将有单个任务执行,并行度是1。简而言之,任意时刻只有一个window任务执行
8.4 Window Assigners
WindowAssigner定义如何将元素划分给窗口,通过调用window()方法或者windowAll()方法传递一个WindowAssigner对象参数完成。WindowAssigner负责将传递过来的元素分配给1个或多个窗口。
Flink中提供了一些WindowAssigner:tumbling windows, sliding windows, session windows and global windows,也可以自定义WindowAssigner,通过继承WindowAssigner类完成自定义。
除了global windows之外的其他窗口,都是基于时间的窗口,这类窗口会有一个开始时间戳(包含)和一个结束时间戳(不包含)用来描述窗口的大小
8.4.1 Tumbling Windows
滚动窗口分配器将每个元素分配给指定大小的窗口。滚动窗口具有固定的大小,并且不重叠。例如,如果指定一个大小为5分钟的滚动窗口,则将计算当前窗口,并每隔5分钟启动一个新窗口

import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
object TumblingWindows {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
result.print()
environment.execute("Tumbling Windows")
}
}
8.4.2 Sliding Windows
滑动窗口分配器将元素分配给固定长度的窗口。与滚动窗口分配程序类似,窗口大小由窗口大小参数配置。另一个,窗口滑动参数控制滑动窗口的创建频率。因此,如果滑动参数小于窗口大小,则滑动窗口可能重叠。在这种情况下,元素被分配给多个窗口。

import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.{SlidingProcessingTimeWindows, TumblingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object SlidingWindows {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(0)
.window(SlidingProcessingTimeWindows.of(Time.seconds(10),Time.seconds(5)))
.reduce((v1, v2) => (v1._1, v1._2 + v2._2))
//也可以使用aggregate,结合自定义aggregateFunction完成求和统计
result.print()
environment.execute("Sliding Windows")
}
}
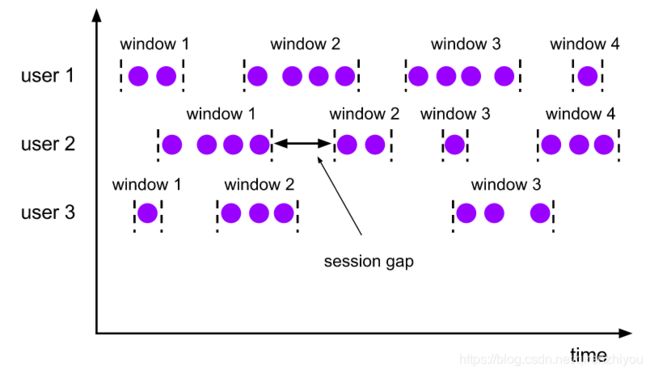
8.4.3 Session Windows
会话窗口分配器按活动的会话对元素进行分组。与滚动窗口和滑动窗口相比,会话窗口不重叠,也没有固定的开始和结束时间。相反,当会话窗口在一段时间内没有接收到元素(当出现不活动的**间隙**)时,会话窗口将关闭。会话窗口分配器可以配置为静态会话间隙,也可以自定义会话间隙。当此时间段过期时,当前会话将关闭,后续元素将分配给新会话窗口。
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
class MyWindowFunctionForSessionWindows extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//统计
val sum = input.map(_._2).sum
var start = window.getStart
var end = window.getEnd
println(start+"~"+end+"==>total milleseconds:"+(end-start)+"。==》"+key+":"+sum)
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.{ProcessingTimeSessionWindows, SlidingProcessingTimeWindows}
import org.apache.flink.streaming.api.windowing.time.Time
object SessionWindows {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
//特别注意这里,不能keyBy(0)
.keyBy(t=>t._1)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(5)))
.apply(new MyWindowFunctionForSessionWindows)
result.print()
environment.execute("Session Windows")
}
}
8.4.4 Global Windows
全局窗口分配器将具有相同键的所有元素分配给同一个全局窗口。只有指定触发器时,此窗口才可用。否则将不会执行任何计算,因为全局窗口没有可以处理聚合元素的自然结束。

import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
class MyWindowFunctionForGlobalWindows extends WindowFunction[(String,Int),(String,Int),String,GlobalWindow]{
override def apply(key: String, window: GlobalWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
val sum = input.map(_._2).sum
out.collect((key,sum))
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
object MyGlobalWindows {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
//特别注意这里,不能keyBy(0)
.keyBy(t=>t._1)
.window(GlobalWindows.create())
.trigger(CountTrigger.of(4))
.apply(new MyWindowFunctionForGlobalWindows)
result.print()
environment.execute("Global Windows")
}
}
8.5 Window Functions
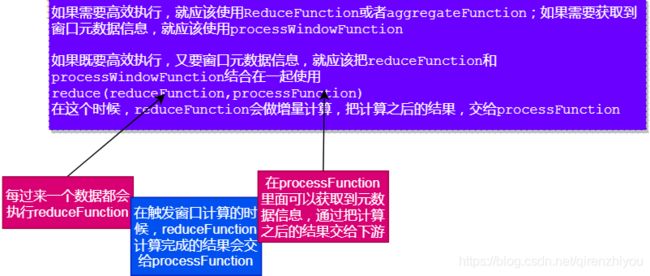
定义窗口分配器之后,我们需要指定要在每个窗口上执行的计算,这是Window Function的职责。窗口函数可以是ReduceFunction, AggregateFunction,FoldFunction、ProcessWindowFunction、WindowFunction(古董)之一。
ReduceFunction/AggregateFunction:在运行效率上比ProcessWindowFunction高,执行增量计算,只要有数据抵达窗口,系统就会进行增量计算
ProcessWindowFunction:在窗口触发之前会一直缓存接收数据,只有当窗口就绪的时候才会对窗口中的元素做批量统一计算,该方法可以获取窗口的元数据信息
可以通过将ProcessWindowFunction与 ReduceFunction,AggregateFunction结合使用,即可以获得窗口元素的增量聚合,又可以接收到窗口元数据。
8.5.1 ReduceFunction
import org.apache.flink.api.common.functions.ReduceFunction
class MyReduceFunction extends ReduceFunction[(String,Int)]{
override def reduce(value1: (String, Int), value2: (String, Int)): (String, Int) = {
//验证增量的概念
println("value1:"+value1+",value2:"+value2)
(value1._1,value1._2+value2._2)
}
}
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
object TumblingWindowsUsingReduceFunction {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new MyReduceFunction)
result.print()
environment.execute("Tumbling Windows")
}
}
8.5.2 AggregateFunction
import org.apache.flink.api.common.functions.AggregateFunction
class MyAggregateFunction extends AggregateFunction[(String,Int),(String,Int),(String,Int)]{
override def createAccumulator(): (String, Int) = ("",0)
override def add(value: (String, Int), accumulator: (String, Int)): (String, Int) = {
(value._1,value._2+accumulator._2)
}
override def getResult(accumulator: (String, Int)): (String, Int) = {
accumulator
}
override def merge(a: (String, Int), b: (String, Int)): (String, Int) = {
(a._1,a._2+b._2)
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners._
import org.apache.flink.streaming.api.windowing.time.Time
object TumblingWindowsUsingAggregateFunction {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(0)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.aggregate(new MyAggregateFunction)
result.print()
environment.execute("Tumbling Windows")
}
}
8.5.3 ProcessWindowFunction
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
/**
* 注意:import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
*/
class MyProcessWindowFunction extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
private val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//获取到window对象
val window: TimeWindow = context.window
val start: Long = window.getStart
val end: Long = window.getEnd
val startStr: String = format.format(start)
val endStr: String = format.format(end)
val total: Int = elements.map(_._2).sum
out.collect(startStr+"~"+endStr+"==>key:"+key,total)
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object TumblingWindowsUsingProcessWindowFunction {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new MyProcessWindowFunction)
result.print()
environment.execute("Tumbling Windows")
}
}
8.5.4 ProcessWindowFunction
通过ProcessWindowFunction实现既获取窗口元数据,又要做增量计算
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object TumblingWindowsUsingProcessWindowFunctionAndReduceFunction {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.reduce(new MyReduceFunction,new MyProcessWindowFunction)
result.print()
environment.execute("Tumbling Windows")
}
}

8.5.5 ProcessWindowStateFunction
通过ProcessWindowFunction可以获取到每一个窗口的状态数据 windowState,也可以获取到所有窗口汇总数据globalState
globalState()windowState()
import java.text.SimpleDateFormat
import org.apache.flink.api.common.state.{ValueState, ValueStateDescriptor}
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.function.ProcessWindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
import org.apache.flink.streaming.api.scala._
class MyProcessWindowFunctionWithState extends ProcessWindowFunction[(String,Int),(String,Int),String,TimeWindow]{
private val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
var windowStateDescriptor:ValueStateDescriptor[Int]=_
var globalStateDescriptor:ValueStateDescriptor[Int]=_
override def open(parameters: Configuration): Unit = {
windowStateDescriptor = new ValueStateDescriptor[Int]("windowStateDescriptor",createTypeInformation[Int])
globalStateDescriptor = new ValueStateDescriptor[Int]("globalStateDescriptor",createTypeInformation[Int])
}
override def process(key: String, context: Context, elements: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
//获取到window对象
val window: TimeWindow = context.window
val start: Long = window.getStart
val end: Long = window.getEnd
val startStr: String = format.format(start)
val endStr: String = format.format(end)
val total: Int = elements.map(_._2).sum
val windowState: ValueState[Int] = context.windowState.getState(windowStateDescriptor)
val globalState: ValueState[Int] = context.globalState.getState(globalStateDescriptor)
windowState.update(windowState.value()+total)
globalState.update(globalState.value()+total)
println(windowState.value()+"***"+globalState.value())
out.collect(startStr+"~"+endStr+"==>key:"+key,total)
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object TumblingWindowsUsingProcessWindowFunctionState {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(_._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.process(new MyProcessWindowFunctionWithState)
result.print()
environment.execute("Tumbling Windows")
}
}
8.5.6 WindowFunction (Legacy)
在某些可以使用ProcessWindowFunction的地方,也可以使用WindowFunction。这是较旧版本的ProcessWindowFunction。WindowFunction提供的不是上下文对象而是window对象,所以在使用ProcessWindowFunction中通过上下文对象获取的信息,在使用WindowFunction时就没有办法继续使用。比如说globalState
import java.text.SimpleDateFormat
import org.apache.flink.streaming.api.scala.function.WindowFunction
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
class MyWindowFunction extends WindowFunction[(String,Int),(String,Int),String,TimeWindow]{
private val format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
override def apply(key: String, window: TimeWindow, input: Iterable[(String, Int)], out: Collector[(String, Int)]): Unit = {
val start: Long = window.getStart
val end: Long = window.getEnd
val startStr: String = format.format(start)
val endStr: String = format.format(end)
val total: Int = input.map(_._2).sum
out.collect(startStr+"~"+endStr+"==>key:"+key,total)
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
object TumblingWindowsUsingWindowFunction {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.keyBy(t=>t._1)
.window(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.apply(new MyWindowFunction)
result.print()
environment.execute("Tumbling Windows")
}
}
8.6 Triggers(触发器)
Trigger决定窗口何时可以通过windowFunction进行计算。Trigger确定窗口何时就绪。每一个windowAssinger都有一个默认的trigger,当默认的trigger不能满足需要时,可以自定义trigger
8.6.1 默认触发器
| 窗口类型 | 触发器 | 触发时机 |
|---|---|---|
| ProcessingTimeWindows (TumblingProcessingTimeWindows SlidingProcessingTimeWindows ProcessingTimeSessionWindows) |
ProcessingTimeTrigger | 系统时间超过了窗口的最后时间就会触发 |
| EventTimeWindows (TumblingEventTimeWindows SlidingEventTimeWindows EventTimeSessionWindows) |
EventTimeTrigger | |
| GlobalWindows | NeverTrigger | 永不触发 |

8.6.2 触发器机制
触发器接口中五个方法。这些方法运行触发器对不同事件作出反应:
- onElement() -每添加一个元素到指定窗口,就会调用一次这个方法
- onEventTime()-当注册的event-time计时器触发时,会调用该方法
- onProcessingTime()-当注册的processing-time计时器触发时,会调用该方法
- onMerge()-当多个窗口合并到一个窗口时触发,例如session window
- clear() -在删除相应窗口时执行所需的任何操作,比如清除定时器、删除存储的状态等
以上五个方法,需要注意两件事情
- 前三个方法通过返回TriggerResult来决定,如何处理它们的调用事件
CONTINUE:继续,当前窗口不做任何处理,FIRE:触发计算,PURGE:清理窗口中的元素FIRE_AND_PURGE:触发计算,然后清除窗口中的元素
- 这些方法中的任何一个都可以用于process-time和event-time计时器以完成后续的操作
8.6.3 自定义
import org.apache.flink.streaming.api.scala.function.AllWindowFunction
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow
import org.apache.flink.util.Collector
class MyAllWindowFunctionForGlobalWindows extends AllWindowFunction[String,String,GlobalWindow]{
override def apply(window: GlobalWindow, input: Iterable[String], out: Collector[String]): Unit = {
val list: List[String] = input.toList
println(list.mkString(" | "))
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger
object MyGlobalWindowsUsingTrigger {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.windowAll(GlobalWindows.create())
.trigger(CountTrigger.of(4))
.apply(new MyAllWindowFunctionForGlobalWindows)
environment.execute("Global Windows")
}
}
结合CountTrigger源代码理解上述代码
高阶应用–自定义触发器
import org.apache.flink.api.common.functions.ReduceFunction
import org.apache.flink.api.common.state.{ReducingState, ReducingStateDescriptor}
import org.apache.flink.streaming.api.windowing.triggers.{Trigger, TriggerResult}
import org.apache.flink.streaming.api.windowing.windows.Window
import org.apache.flink.streaming.api.scala._
class MyCountTrigger(maxCount:Long) extends Trigger[String,Window]{
var reduceFunction:ReduceFunction[Long]=new ReduceFunction[Long] {
override def reduce(value1: Long, value2: Long): Long = {
value1+value2
}
}
var reducingStateDescriptor:ReducingStateDescriptor[Long]=new ReducingStateDescriptor[Long]("reducingStateDescriptor",reduceFunction,createTypeInformation[Long])
override def onElement(element: String, timestamp: Long, window: Window, ctx: Trigger.TriggerContext): TriggerResult = {
val reducingState: ReducingState[Long] = ctx.getPartitionedState(reducingStateDescriptor)
reducingState.add(1L)
if(reducingState.get()>=maxCount){
reducingState.clear()
return TriggerResult.FIRE_AND_PURGE
}
TriggerResult.CONTINUE
}
override def onProcessingTime(time: Long, window: Window, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def onEventTime(time: Long, window: Window, ctx: Trigger.TriggerContext): TriggerResult = {
TriggerResult.CONTINUE
}
override def clear(window: Window, ctx: Trigger.TriggerContext): Unit = {
ctx.getPartitionedState(reducingStateDescriptor).clear()
}
}
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
object MyGlobalWindowsUsingTrigger {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.windowAll(GlobalWindows.create())
//.trigger(CountTrigger.of(4))
.trigger(new MyCountTrigger(4))
.apply(new MyAllWindowFunctionForGlobalWindows)
environment.execute("Global Windows")
}
}
切换成TumblingProecessingTimeWindow
扩展DeltaTrigger的使用(扩展)
import org.apache.flink.streaming.api.functions.windowing.delta.DeltaFunction import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows import org.apache.flink.streaming.api.windowing.triggers.DeltaTrigger import org.apache.flink.streaming.api.windowing.windows.GlobalWindow object MyGlobalWindowsUsingTrigger { def main(args: Array[String]): Unit = { val environment = StreamExecutionEnvironment.getExecutionEnvironment val dataStream = environment.socketTextStream("flink.abc.com",9999) val result: DataStream[Double] = dataStream.flatMap((line => line.split("\\s+"))) .windowAll[GlobalWindow](GlobalWindows.create()) .trigger(DeltaTrigger.of[String, GlobalWindow](2, new DeltaFunction[String] { override def getDelta(oldDataPoint: String, newDataPoint: String): Double = { println(newDataPoint+"***"+oldDataPoint) newDataPoint.toDouble - oldDataPoint.toDouble } }, createTypeInformation[String].createSerializer(environment.getConfig))) .apply(new MyAllWindowFunctionForGlobalWindowsDoubleType) environment.execute("Global Windows") } }import org.apache.flink.streaming.api.scala.function.AllWindowFunction import org.apache.flink.streaming.api.windowing.windows.GlobalWindow import org.apache.flink.util.Collector class MyAllWindowFunctionForGlobalWindowsDoubleType extends AllWindowFunction[String,Double,GlobalWindow]{ override def apply(window: GlobalWindow, input: Iterable[String], out: Collector[Double]): Unit = { val list: List[String] = input.toList println(list.mkString(" | ")) } }
8.7 Evictors(剔除器)
Flink的窗口,除了允许指定WindowAssigner以及Trigger,还可以指定Evictor,可以使用evictor(…)方法完成。evictor可以从窗口中移除元素。evictor会在trigger触发之后,window function执行之前或之后执行。
Evictor接口提供两个方法
public interface Evictor<T, W extends Window> extends Serializable {
/**
* 在window function执行之前做剔除会调用这个方法
* Optionally evicts elements. Called before windowing function.
*
* @param elements The elements currently in the pane.当前窗口中的所有元素
* @param size The current number of elements in the pane.当前窗口中元素的个数
* @param window The {@link Window} 当前窗口对象
* @param evictorContext The context for the Evictor 上下午
*/
void evictBefore(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
/**
* 在window function执行之后调用这个方法
* Optionally evicts elements. Called after windowing function.
*
* @param elements The elements currently in the pane.
* @param size The current number of elements in the pane.
* @param window The {@link Window}
* @param evictorContext The context for the Evictor
*/
void evictAfter(Iterable<TimestampedValue<T>> elements, int size, W window, EvictorContext evictorContext);
}
8.7.1 Flink Evictor
Flink提供三个Evictor实现类
- CountEvictor-在窗口中保留用户指定数量的元素,并从窗口缓冲区的开头丢弃其余的元素
- DeltaEvictor-需要一个DeltaFunction和阈值,计算窗口缓冲区中最后一个元素与其余每个元素之间的增量,并删除增量大于或等于阈值的元素
- TimeEvictor-需要一个毫秒为单位的参数interval,对于给定的窗口,在其元素中查找最大时间戳max_ts,并删除时间戳小于max_ts-interval的所有元素
import org.apache.flink.streaming.api.scala.{StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows
import org.apache.flink.streaming.api.windowing.evictors.CountEvictor
import window.trigger.{MyAllWindowFunctionForGlobalWindows, MyCountTrigger}
object MyGlobalWindowsUsingCountEvictor {
def main(args: Array[String]): Unit = {
val environment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream = environment.socketTextStream("flink.abc.com",9999)
val result = dataStream.flatMap(line => line.split("\\s+"))
.windowAll(GlobalWindows.create())
.trigger(new MyCountTrigger(4))
.evictor(CountEvictor.of(3))
.apply(new MyAllWindowFunctionForGlobalWindows)
environment.execute("Global Windows")
}
}

8.7.2 自定义Evictor
参考CountEvictor完成自定义Evictor
import org.apache.flink.streaming.api.scala.function.ProcessAllWindowFunction
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _}
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.windowing.windows.TimeWindow
import org.apache.flink.util.Collector
object MyTumblingWindowsUsingMyEvictor {
def main(args: Array[String]): Unit = {
val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment
val dataStream: DataStream[String] = environment.socketTextStream("flink.abc.com",9999)
dataStream.windowAll(TumblingProcessingTimeWindows.of(Time.seconds(5)))
.evictor(new MyEvictor(false,"error"))
.process(new MyProcessAllWindowFunction).print()
environment.execute("MyTumblingWindowsUsingMyEvictorJob")
}
}
class MyProcessAllWindowFunction extends ProcessAllWindowFunction[String,String,TimeWindow]{
override def process(context: Context, elements: Iterable[String], out: Collector[String]): Unit = {
out.collect(elements.mkString(" | "))
}
}
/**
* 把一句话中包含指定单词的内容剔除掉
*/
class MyEvictor(doEvictAfter:Boolean,execludWords:String) extends Evictor[String,TimeWindow]{
override def evictBefore(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
if(!doEvictAfter){
evict(elements,size,evictorContext)
}
}
override def evictAfter(elements: lang.Iterable[TimestampedValue[String]], size: Int, window: TimeWindow, evictorContext: Evictor.EvictorContext): Unit = {
if(doEvictAfter){
evict(elements,size,evictorContext)
}
}
private def evict(elements: lang.Iterable[TimestampedValue[String]], size: Int, context: Evictor.EvictorContext):Unit={
val iterator: util.Iterator[TimestampedValue[String]] = elements.iterator()
while(iterator.hasNext){
val element: TimestampedValue[String] = iterator.next()
if(element.getValue.contains(execludWords)){
iterator.remove()
}
}
}
}
9 EventTimeWindow
9.1 Event Time
Flink在流计算的过程中,支持多种时间概念
- Processing Time:处理时间,指执行相应操作的机器的系统时间。
- Event Time:事件时间,每个事件在其生产设备上发生的时间。处理乱序数据(数据的处理和数据的生成顺序会乱)
- Ingestion Time:摄取时间,事件进入Flink的时间

在Flink的窗口计算中,如果Flink在使用的时候不做显示声明,默认使用的是ProcessingTime。IngestionTime和ProcessingTime类似都是由系统自动产生,不同的是IngestionTime是由DataSource产生,ProcessingTime由算子产生。因此以上两种时间策略都不能很好的表达在流计算中事件产生时间(因为存在网络延时迟)。
Flink支持事件时间策略。事件时间是每个事件在其生产设备上发生的时间。此时间通常在记录进入Flink之前嵌入到记录中,并且可以从每个记录中提取事件时间戳。在事件时间中,时间的进度取决于数据,而不是任何时钟。事件时间程序必须指定如何生成事件时间Watermarks,这是事件时间进程的信号机制
9.2 Watermark
9.2.1 概念
流处理从事件产生,到source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。

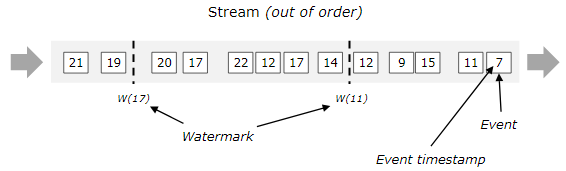
因为有可能乱序,如果只根据eventTime决定窗口的运行,就不能明确数据是否全部到位,但又不能无限期的等待,此时必须要有一种机制来保证一个特定的时间后,必须触发window function进行计算,这个机制就是Watermark。
Watermark是Flink中测量事件时间进度的机制。Watermark作为数据流的一部分流动,并带有时间戳t。数据流中的Watermark用于表示时间戳小于Watermark的数据,都已经到达了。因此流中不应该再有时间戳t’<=watermark的元素。因此只有水位线越过对应窗口的结束时间,窗口才会关闭和进行计算

Flink接收到每一条数据时,都会产生一条Watermark,watermark = maxEventTime - maxAllowedLateness
- watermark是一个衡量事件时间进度的机制:水位线就是时间戳
- watermark是解决乱序问题的重要依据
- 在窗口计算中,watermark没过了窗口的结束时间就触发窗口计算(属于该窗口的元素都已经到达);被认为早于这个时间的数据都已经到达
- watermark的计算应该是:
最大事件时间-最大允许迟到时间
9.2.2 Watermark计算
Flink中常用watermark计算方式有两种

- With Periodic Watermarks–定期提取水位线:比如每间隔1秒提取计算一次水位线(常用)
- With Punctuated Watermarks–每一个event计算一个水位线(不常用)
主程序中,指定使用事件时间
environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
若使用固定周期提取水位线,设置固定周期
environment.getConfig.setAutoWatermarkInterval(1000)
数据流处理过程,指定水位线提取策略
.assignTimestampsAndWatermarks(new MyWatermark)
窗口计算使用事件时间窗口,SlidingProcessingTimeWindows/TumblingEventTimeWindows
-
With Periodic Watermarks
import java.text.SimpleDateFormat import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks import org.apache.flink.streaming.api.watermark.Watermark /*** * 这种方式计算水位线是常用的方式 */ class MyAssignerWithPeriodicWatermarks extends AssignerWithPeriodicWatermarks[(String,Long)]{ //最大事件时间 var maxEventTime:Long = _ //最大允许迟到时间 var maxAllowedLateness:Long = 2000 //用来计算水位线;由系统自动调用(每间隔一定时间调用一次)--以固定的频率调用 override def getCurrentWatermark: Watermark = { new Watermark(maxEventTime - maxAllowedLateness) } /** * 有一个元素就会执行一次 * @param element 流过来的元素 */ override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = { val format = new SimpleDateFormat("HH:mm:ss") //计算最大的事件时间 maxEventTime = Math.max(maxEventTime,element._2) println("当前元素:"+(element._1,format.format(element._2))+",水位线:"+format.format(maxEventTime - maxAllowedLateness)) //方法返回值是当前元素的时间戳 element._2 } }import java.text.SimpleDateFormat import org.apache.flink.streaming.api.scala.function.AllWindowFunction import org.apache.flink.streaming.api.windowing.windows.TimeWindow import org.apache.flink.util.Collector class MyAllWindowFunctionForEventTime extends AllWindowFunction[(String,Long),String,TimeWindow]{ override def apply(window: TimeWindow, input: Iterable[(String, Long)], out: Collector[String]): Unit = { val start: Long = window.getStart val end: Long = window.getEnd //窗口的边界规则:前开后闭(前包含,后不包含) val format = new SimpleDateFormat("HH:mm:ss") println("窗口时间范围:["+format.format(start)+","+format.format(end)+")") //把处理之后的元素发送到下游 val elements: String = input.map(word=>word._1+":"+format.format(word._2)).mkString(" | ") out.collect(elements) } }import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.assigners.{TumblingEventTimeWindows, TumblingProcessingTimeWindows} import org.apache.flink.streaming.api.windowing.time.Time object AssignerWithPeriodicWatermarksDemo { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //并行度设置为1 environment.setParallelism(1) //flink在做流计算时默认使用processingTime。如果要使用eventTime,就需要显示声明 environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //每1秒钟调用一个水位线生成函数 environment.getConfig.setAutoWatermarkInterval(1000) //数据:a 1590647654000 val dataStream: DataStream[String] = environment.socketTextStream("flink.abc.com",9999) val result: DataStream[String] = dataStream.map(line => line.split("\\s+")) .map(word => (word(0), word(1).toLong)) //指定水位线生成策略 .assignTimestampsAndWatermarks(new MyAssignerWithPeriodicWatermarks) .windowAll(TumblingEventTimeWindows.of(Time.seconds(2))) .apply(new MyAllWindowFunctionForEventTime) result.print() environment.execute("AssignerWithPeriodicWatermarksDemoJob") } } -
With Punctuated Watermarks
每一个事件都会生成一个水位线。在生产环境中,过多的生成水位线会影响程序的性能
import java.text.SimpleDateFormat import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks import org.apache.flink.streaming.api.watermark.Watermark class MyAssignerWithPunctuatedWatermarks extends AssignerWithPunctuatedWatermarks[(String,Long)]{ //最大事件时间 var maxEventTime:Long=Long.MinValue //最大允许迟到时间 var maxAllowedLateness:Long=2000 /** * 每过来一个元素。执行完extractTimestamp方法再执行这个方法 * 计算水位线的方法 * @param lastElement 当前元素 * @param extractedTimestamp * @return */ override def checkAndGetNextWatermark(lastElement: (String, Long), extractedTimestamp: Long): Watermark = { maxEventTime = Math.max(maxEventTime,lastElement._2) val format = new SimpleDateFormat("HH:mm:ss") println("水位线:"+format.format(maxEventTime-maxAllowedLateness)) new Watermark(maxEventTime-maxAllowedLateness) } /** * 每过来一个元素。都会先执行这个方法 * 返回当前元素的时间戳 * @param element 当前元素 */ override def extractTimestamp(element: (String, Long), previousElementTimestamp: Long): Long = { element._2 } }import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time object AssignerWithPunctuatedWatermarksDemo { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //并行度设置为1 environment.setParallelism(1) //flink在做流计算时默认使用processingTime。如果要使用eventTime,就需要显示声明 environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //数据:a 1590647654000 val dataStream: DataStream[String] = environment.socketTextStream("flink.abc.com",9999) val result: DataStream[String] = dataStream.map(line => line.split("\\s+")) .map(word => (word(0), word(1).toLong)) //指定水位线生成策略 .assignTimestampsAndWatermarks(new MyAssignerWithPunctuatedWatermarks) .windowAll(TumblingEventTimeWindows.of(Time.seconds(2))) .apply(new MyAllWindowFunctionForEventTime) result.print() environment.execute("AssignerWithPunctuatedWatermarksDemo") } }
在并行情况下
算子的eventTime以最小的输入流eventTime为准
比如:window[2]算子在继续往下游走的时候,使用的eventTime是14而不是29
当流中存在多个watermark时,以最小值为watermark


9.3 迟到数据
在flink中对于迟到数据进行三种处理
- 默认处理方式:直接丢弃(spark就是采用这个方式)
- 在允许迟到的范围内,会重新开启窗口进行重新计算
- 超出了范围的数据tooLate,可以采用侧边输出的方式呈现处理方便后续的处理
在Flink中,水位线一旦没过窗口的EndTime,如果还有数据落入到此窗口,这些数据被定义为迟到数据。
默认情况下,迟到数据将被删除。但是,Flink允许为窗口操作符指定允许的最大延迟,在允许的延迟范围内到达的元素仍然会添加到窗口中。
根据使用的触发器,延迟但未丢弃的元素可能会导致窗口再次触发。
-
如果**
Watermarker < 窗口EndTime + 允许迟到时间**,则该数据还可以参与窗口计算import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time object AssignerWithPunctuatedWatermarksForLatenessDemo { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //并行度设置为1 environment.setParallelism(1) //flink在做流计算时默认使用processingTime。如果要使用eventTime,就需要显示声明 environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //数据:a 1590647654000 val dataStream: DataStream[String] = environment.socketTextStream("flink.abc.com",9999) val result: DataStream[String] = dataStream.map(line => line.split("\\s+")) .map(word => (word(0), word(1).toLong)) //指定水位线生成策略 .assignTimestampsAndWatermarks(new MyAssignerWithPunctuatedWatermarks) .windowAll(TumblingEventTimeWindows.of(Time.seconds(2))) ///================对迟到数据的处理================== .allowedLateness(Time.seconds(2)) .apply(new MyAllWindowFunctionForEventTime) result.print() environment.execute("AssignerWithPeriodicWatermarksDemoJob") } } -
如果
Watermarker >= 窗口EndTime + 允许迟到时间,则该数据会被丢弃。为了能够更直观的呈现这些too late数据,可以通过side out输出import org.apache.flink.streaming.api.TimeCharacteristic import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment, _} import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows import org.apache.flink.streaming.api.windowing.time.Time object AssignerWithPunctuatedWatermarksForTooLateDemo { def main(args: Array[String]): Unit = { val environment: StreamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment //并行度设置为1 environment.setParallelism(1) //flink在做流计算时默认使用processingTime。如果要使用eventTime,就需要显示声明 environment.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) //数据:a 1590647654000 val dataStream: DataStream[String] = environment.socketTextStream("flink.abc.com",9999) //要把too late数据通过边输出显示,就需要outputTag var outputTag:OutputTag[(String,Long)]=new OutputTag[(String,Long)]("too late") val result: DataStream[String] = dataStream.map(line => line.split("\\s+")) .map(word => (word(0), word(1).toLong)) .assignTimestampsAndWatermarks(new MyAssignerWithPunctuatedWatermarks) .windowAll(TumblingEventTimeWindows.of(Time.seconds(2))) .allowedLateness(Time.seconds(2)) //迟到时间 >=允许允许迟到时间的数据,通过边输出的方式 .sideOutputLateData(outputTag) .apply(new MyAllWindowFunctionForEventTime) result.print("正常") result.getSideOutput(outputTag).printToErr("太迟的数据") environment.execute("AssignerWithPunctuatedWatermarksForTooLateDemo") } }
10 Flink精准一次
10.1 精准一次定义
精准一次,是数据对结果只影响一次。exactly-once(精准一次)
Flink提供了对应的语义(semantics):flink能够以什么机制保障数据的处理对结果的影响
exactly-once:精准一次
at-least-once:至少一次
10.2 精准一次分类
10.2.1 Source
从外部存储消费数据时,保证精准一次通过checkpoint完成的
flink的checkpoint:由jobManager发起checkpoint。jobManager要做checkpoint,就会在数据流中引入barrier。barrier会随着数据流进入到所有的算子执行处理。每一算子获取到barrier会做预处理(pre-commit),当所有的算子都预处理成功,这一次checkpoint才算完成(commit)。会把之前的checkpoint替换掉。如果有一个算子在做pre-commit的时候失败,这一次checkpoint就算失败,flink需要使用的还是上一次成功的checkpoint
Flink从Kafka消费数据是如何保证精准一次:
checkpoint完成的精准一次。不依赖于kafka
FlinkKafkaConsumer在做checkpoint时,会存储kafka的partition以及offset

10.2.2 Sink
往外部写数据的时候,保证精准一次,是端到端精准一次(end to end)
flink提供一种机制:两段提交机制(TwoPhaseCommitSinkFunction)
Flink使用kafka作为sink要保证精准一次,需要flink的精准一次,也需要kafka支持精准一次
需要开启flink的checkpoint,同时还需要有kafka的支持
- kafka0.8以及之前的版本,不支持至少一次以及精准一次语义
- kafka0.9以及kafka0.10,只支持至少一次的语义
- kafka0.11以及之后的版本,支持精准一次语义

参考链接:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html#kafka-consumers-and-fault-tolerance
必须保证kafka使用的是0.11以及之后的版本
flink中提供的有两段提交机制(TwoPhaseCommitSinkFunction):flink做checkpoint时,先有算子进行预提交(pre-commit),当所有算子预提交成功之后,再做统一的提交处理交给jobManager管理checkpoint。这一次checkpoint才算成功
在Flink连接kafka的代码,提供了FlinkKafkaProducer,这个sink就是TwoPhaseCommitSinkFunction的子类型。需要借助于kafka的事务保证两段提交。也就是说kafka必须支持两段提交机制协议,才可以保证精准一次
要使用其他的sink,保证精准一次,就需要继承TwoPhaseCommitSinkFunction,重写里面的四个方法。这四个方法保证了两段提交协议的正常执行
