Day79_Flink(五) FlinkSQL和CEP
| 课程大纲 |
课程内容 |
学习效果 |
掌握目标 |
| FlinkSQL |
FlinkTable |
掌握 |
|
| FlinkSQL |
掌握 |
||
| FlinkCEP |
FlinkCEP |
掌握 |
|
| 任务性能优化 |
operator chain |
掌握 |
|
| slot sharing |
掌握 |
||
| Flink异步IO |
掌握 |
||
| Checkpoint 优化 |
掌握 |
一、Table&SQL
(一)概述
Table API是流处理和批处理通用的关系型 API,Table API 可以基于流输入或者批输入来运行而不需要进行任何修改。Table API 是 SQL 语言的超集并专门为 Apache Flink 设计的,Table API 是 Scala 和 Java 语言集成式的 API。与常规 SQL 语言中将查询指定为字符串不同,Table API 查询是以 Java 或 Scala 中的语言嵌入样式来定义的,具有 IDE 支持如:自动完成和语法检测;允许以非常直观的方式组合关系运算符的查询,例如 select,filter 和 join。Flink SQL 的支持是基于实现了SQL标准的 Apache Calcite。无论输入是批输入(DataSet)还是流输入(DataStream),任一接口中指定的查询都具有相同的语义并指定相同的结果。

(二)、Table API
1、依赖
org.apache.flink
flink-table
1.9.1
pom
org.apache.flink
flink-table-planner_2.11
1.9.1
org.apache.flink
flink-table-api-java-bridge_2.11
1.9.1
org.apache.flink
flink-table-api-scala-bridge_2.11
1.9.1
org.apache.flink
flink-table-api-scala-bridge_2.11
1.9.1
org.apache.flink
flink-table-common
1.9.1
2、Table API
(1)、TableEnvironment
TableEnvironment 是 Table API 和SQL集成的核心概念,它负责:
- 在内部目录中注册表
- 注册外部目录
- 执行SQL查询
- 注册用户定义的函数
- DataStream 或 DataSet 转换为 Table
- 持有 ExecutionEnvironment 或 StreamExecutionEnvironment 的引用
Table总是与特定的TableEnvironment 绑定。不能在同一查询中组合不同 TableEnvironments 的表(例如,union 或 join)。创建 TableEnvironment:
// 基于流的tableEnv
val sEnv = StreamExecutionEnvironment.getExecutionEnvironment
// create a TableEnvironment for streaming queries
val sTableEnv = StreamTableEnvironment.create(sEnv)
// 基于批的bTableEnv
val bEnv: ExecutionEnvironment = ExecutionEnvironment.getExecutionEnvironment
val bTableEnv: BatchTableEnvironment = BatchTableEnvironment.create(bEnv)
(2)、数据加载
数据加载通常有两种:一者基于流/批,一者基于TableSource,但是后者在Flink1.11中已经被废弃,所以不建议使用。
基于批
case class Student(id:Int,name:String,age:Int,gender:String,course:String,score:Int)
object FlinkBatchTableOps {
def main(args: Array[String]): Unit = {
//构建batch的executionEnvironment
val env = ExecutionEnvironment.getExecutionEnvironment
val bTEnv = BatchTableEnvironment.create(env)
val dataSets: DataSet[Student] = env.readCsvFile[Student]("E:\\data\\student.csv",
//是否忽略文件的第一行数据(主要考虑表头数据)
ignoreFirstLine = true,
//字段之间的分隔符
fieldDelimiter = "|")
//table 就相当于sparksql中的dataset
val table: Table = bTEnv.fromDataSet(dataSets)
//条件查询
val result: Table = table.select("name,age").where("age=25")
//打印输出
bTEnv.toDataSet[Row](result).print()
}
}
数据:
基于流
case class Goods(id: Int,brand:String,category:String)
object FlinkStreamTableOps {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
val sTEnv = StreamTableEnvironment.create(env)
val dataStream: DataStream[Goods] = env.fromElements(
"001|mi|mobile",
"002|mi|mobile",
"003|mi|mobile",
"004|mi|mobile",
"005|huawei|mobile",
"006|huawei|mobile",
"007|huawei|mobile",
"008|Oppo|mobile",
"009|Oppo|mobile",
"010|uniqlo|clothing",
"011|uniqlo|clothing",
"012|uniqlo|clothing",
"013|uniqlo|clothing",
"014|uniqlo|clothing",
"015|selected|clothing",
"016|selected|clothing",
"017|selected|clothing",
"018|Armani|clothing",
"019|lining|sports",
"020|nike|sports",
"021|adidas|sports",
"022|nike|sports",
"023|anta|sports",
"024|lining|sports"
).map(line => {
val fields = line.split("\\|")
Goods(fields(0), fields(1), fields(2))
})
//load data from external system
var table = sTEnv.fromDataStream(dataStream)
// stream table api
table.printSchema()
// 高阶api的操作
table = table.select("category").distinct()
/*
将一个table转化为一个DataStream的时候,有两种选择
toAppendStream :在没有聚合操作的时候使用
toRetractStream(缩放的含义) :在进行聚合操作之后使用
*/
sTEnv.toRetractStream[Row](table).print()
env.execute("FlinkStreamTableOps")
}
}
(3)、sqlQuery
sql仍然是最主要的分析工具,使用dsl当然也能完成业务分析,但是灵活性,简易性上都不及sql。FlinkTable通过sqlQuery来完成sql的查询操作。
case class Goods(id: Int,brand:String,category:String)
object FlinkSQLOps {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val sTEnv = BatchTableEnvironment.create(env)
val dataStream: DataSet[Goods] = env.fromElements(
"001|mi|mobile",
"002|mi|mobile",
"003|mi|mobile",
"004|mi|mobile",
"005|huawei|mobile",
"006|huawei|mobile",
"007|huawei|mobile",
"008|Oppo|mobile",
"009|Oppo|mobile",
"010|uniqlo|clothing",
"011|uniqlo|clothing",
"012|uniqlo|clothing",
"013|uniqlo|clothing",
"014|uniqlo|clothing",
"015|selected|clothing",
"016|selected|clothing",
"017|selected|clothing",
"018|Armani|clothing",
"019|lining|sports",
"020|nike|sports",
"021|adidas|sports",
"022|nike|sports",
"023|anta|sports",
"024|lining|sports"
).map(line => {
val fields = line.split("\\|")
Goods(fields(0), fields(1), fields(2))
})
//load data from external system
sTEnv.registerTable("goods", dataStream)
//sql操作
var sql =
"""
|select
| id,
| brand,
| category
|from goods
|""".stripMargin
sql =
"""
|select
| category,
| count(1) counts
|from goods
|group by category
|order by counts desc
|""".stripMargin
table = sTEnv.sqlQuery(sql)
sTEnv.toDataSet[Row](table).print()
}
}
(4)、基于滚动窗口的Table操作
基于EventTIme滚动窗口操作
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.table.api.scala.StreamTableEnvironment
import org.apache.flink.api.scala._
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.table.api.Table
import org.apache.flink.types.Row
//基于滚动窗口Table操作
object FlinkTrumblingWindowTableOps {
def main(args: Array[String]): Unit = {
//1、获取流式执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
// 2、获取table执行环境
val tblEnv = StreamTableEnvironment.create(env)
//3、获取数据源
//输入数据:
val ds = env.socketTextStream("node01", 9999)
.map(line => {
val fields = line.split("\t")
UserLogin(fields(0), fields(1), fields(2), fields(3).toInt,
fields(4))
})
.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor[UserLogin](Time.seconds(2)) {
override def extractTimestamp(userLogin: UserLogin): Long = {
userLogin.dataUnix * 1000
}
}
)
//4、将DataStream转换成table
//引入隐式
//某天每隔2秒的输入记录条数:
import org.apache.flink.table.api.scala._
val table: Table = tblEnv.fromDataStream[UserLogin](ds , 'platform, 'server, 'status, 'ts.rowtime)
// tblEnv.toAppendStream[Row](table).print()
tblEnv.sqlQuery(
s"""
|select
|platform,
|count(1) counts
|from ${table}
|where status = 'LOGIN'
|group by platform, tumble(ts,interval '2' second)
|""".stripMargin)
.toAppendStream[Row]
.print("每隔2秒不同平台登录用户->")
env.execute()
}
}
/** 用户登录
*
* @param platform 所在平台 id(e.g. H5/IOS/ADR/IOS_YY)
* @param server 所在游戏服 id
* @param uid 用户唯一 id
* @param dataUnix 事件时间/s 时间戳
* @param status 登录动作(LOGIN/LOGOUT)
*/
case class UserLogin(platform: String, server: String, uid: String, dataUnix: Int, status: String)
数据:
![]()
基于窗口的processTime
object FlinkTrumblingWindowTableOps2 {
def main(args: Array[String]): Unit = {
//1、获取流式执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setParallelism(1)
// 2、获取table执行环境
val tblEnv = StreamTableEnvironment.create(env)
//3、获取数据源
//输入数据:
val ds = env.socketTextStream("node01", 9999)
.map(line => {
val fields = line.split("\t")
UserLogin(fields(0), fields(1), fields(2), fields(3).toInt, fields(4))
})
//4、将DataStream转换成table
//引入隐式
//某天每隔2秒的输入记录条数:
import org.apache.flink.table.api.scala._
val table: Table = tblEnv.fromDataStream[UserLogin](ds , 'platform, 'server, 'status, 'ts.proctime)
// tblEnv.toAppendStream[Row](table).print()
tblEnv.sqlQuery(
s"""
|select
| platform,
| count(1) counts
|from ${table}
|where status = 'LOGIN'
|group by platform, tumble(ts,interval '2' second)
|""".stripMargin)
.toAppendStream[Row]
.print("prcotime-每隔2秒不同平台登录用户->")
env.execute()
}
}
(三)、Flink Table UDF
1、UDF
(1)、说明
自定义标量函数(User Defined Scalar Function)。一行输入一行输出。
(2)、数据
// 某个用户在某个时刻浏览了某个商品,以及商品的价值
{"userID": 2, "eventTime": "2020-10-01 10:02:00", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:02", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:10", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:12", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99
{"userID": 2, "eventTime": "2020-10-01 10:02:06", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:15", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}
{"userID": 1, "eventTime": "2020-10-01 10:02:16", "eventType": "browse", "productID": "product_5", "productPrice": 20.99}(3)、需求
UDF时间转换
UDF需要继承`ScalarFunction`抽象类,主要实现eval方法。
自定义UDF,实现将eventTime转化为时间戳
(4)、实现
object FlinkTableUDFOps {
def main(args: Array[String]): Unit = {
val env = ExecutionEnvironment.getExecutionEnvironment
val bTEnv = BatchTableEnvironment.create(env)
val ds = env.fromElements(
).map(line => {
val jsonObj = JSON.parseObject(line)
val userID = jsonObj.getInteger("userID")
val eventTime = jsonObj.getString("eventTime")
val eventType = jsonObj.getString("eventType")
val productID = jsonObj.getString("productID")
val productPrice = jsonObj.getDouble("productPrice")
UserBrowseLog(userID, eventTime, eventType, productID, productPrice)
})
//自定义udf
bTEnv.registerFunction("to_time", new TimeScalarFunction())
bTEnv.registerFunction("myLen", new LenScalarFunction())
val table = bTEnv.fromDataSet(ds)
val sql =
s"""
|select
| userID,
| eventTime,
| myLen(eventTime) my_len_et,
| to_time(eventTime) timestamps
|from ${table}
|""".stripMargin
val ret = bTEnv.sqlQuery(sql)
bTEnv.toDataSet[Row](ret).print
}
}
case class UserBrowseLog(
userID: Int,
eventTime: String,
eventType: String,
productID: String,
productPrice: Double
)
/*
自定义类去扩展ScalarFunction 复写其中的方法:eval
at least one method named 'eval' which is public, not
*/
class TimeScalarFunction extends ScalarFunction {
//2020-10-01 10:02:16
private val df = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
def eval(eventTime: String): Long = {
df.parse(eventTime).getTime
}
}
class LenScalarFunction extends ScalarFunction {
//2020-10-01 10:02:16
def eval(str: String): Int = {
str.length
}
}
二、CEP
(一)、什么是复杂事件处理CEP
一个或多个由简单事件构成的事件流通过一定的规则匹配,然后输出用户想得到的数据,满足规则的复杂事件。
特征:
目标:从有序的简单事件流中发现一些高阶特征
输入:一个或多个由简单事件构成的事件流
处理:识别简单事件之间的内在联系,多个符合一定规则的简单事件构成复杂事件
输出:满足规则的复杂事件
CEP 用于分析低延迟、频繁产生的不同来源的事件流。CEP 可以帮助在复杂的、不相关的事件流中找出有意义的模式和复杂的关系,以接近实时或准实时的获得通知并阻止一些行为。
CEP 支持在流上进行模式匹配,根据模式的条件不同,分为连续的条件或不连续的条件;模式的条件允许有时间的限制,当在条件范围内没有达到满足的条件时,会导致模式匹配超时。
看起来很简单,但是它有很多不同的功能:
输入的流数据,尽快产生结果
在 2 个 event 流上,基于时间进行聚合类的计算
提供实时/准实时的警告和通知
在多样的数据源中产生关联并分析模式
高吞吐、低延迟的处理
市场上有多种 CEP 的解决方案,例如 Spark、Samza、Beam 等,但他们都没有提供专门的 library 支持。但是 Flink 提供了专门的 CEP library。
(二)、Flink CEP
1、组件说明
Flink 为 CEP 提供了专门的 Flink CEP library,它包含如下组件:
- Event Stream
- pattern 定义
- pattern 检测
- 生成 Alert
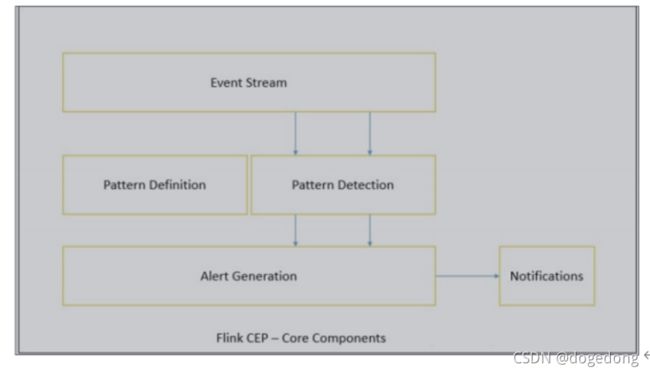
首先,开发人员要在 DataStream 流上定义出模式条件,之后 Flink CEP 引擎进行模式检测,必要时生成告警。
为了使用 Flink CEP,我们需要导入依赖:
org.apache.flink
flink-cep-scala_2.11
1.9.1
2、CEP编码流程
Event Streams
以登陆事件流为例:
case class LoginEvent(userId: String, ip: String, eventType: String, eventTime: String)
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
val loginEventStream = env.fromCollection(List(
LoginEvent("1", "192.168.0.1", "fail", "1558430842"),
LoginEvent("1", "192.168.0.2", "fail", "1558430843"),
LoginEvent("1", "192.168.0.3", "fail", "1558430844"),
LoginEvent("2", "192.168.10.10", "success", "1558430845")))
.assignAscendingTimestamps(_.eventTime.toLong)
Pattern API
每个 Pattern 都应该包含几个步骤,或者叫做 state。从一个 state 到另一个 state,通常我们需要定义一些条件,例如下列的代码:
val loginFailPattern = Pattern.begin[LoginEvent]("begin")
.where(_.eventType.equals("fail"))
.next("next")
.where(_.eventType.equals("fail"))
.within(Time.seconds(10))
每个 state 都应该有一个标示:例如.begin[LoginEvent]("begin")中的"begin"。
每个 state 都需要有一个唯一的名字,而且需要一个 filter 来过滤条件,这个过滤条件定义事件需要符合的条件,例如:
.where(_.eventType.equals("fail"))
我们也可以通过 subtype 来限制 event 的子类型:
start.subtype(SubEvent.class).where(...);
事实上,你可以多次调用 subtype 和 where 方法;而且如果 where 条件是不相关的,你可以通过 or 来指定一个单独的 filter 函数:
pattern.where(...).or(...);
之后,我们可以在此条件基础上,通过 next 或者 followedBy 方法切换到下一个state,next 的意思是说上一步符合条件的元素之后紧挨着的元素;而 followedBy 并不要求一定是挨着的元素。这两者分别称为严格近邻和非严格近邻。
val strictNext = start.next("middle")
val nonStrictNext = start.followedBy("middle")
最后,我们可以将所有的 Pattern 的条件限定在一定的时间范围内:
next.within(Time.seconds(10))
这个时间可以是 Processing Time,也可以是 Event Time。
- Pattern 检测
通过一个 input DataStream 以及刚刚我们定义的 Pattern,我们可以创建一个PatternStream:
val input = ...
val pattern = ...
val patternStream = CEP.pattern(input, pattern)
val patternStream = CEP.pattern(loginEventStream.keyBy(_.userId), loginFailPattern)
一旦获得 PatternStream,我们就可以通过 select 或 flatSelect,从一个 Map 序列找到我们需要的警告信息。
- Select
select 方法需要实现一个 PatternSelectFunction,通过 select 方法来输出需要的警告。它接受一个 Map 对,包含 string/event,其中 key 为 state 的名字,event 则为真实的Event。
val loginFailDataStream = patternStream.select(new MySelectFuction())
其返回值仅为 1 条记录。
- flatSelect
通过实现 PatternFlatSelectFunction,实现与 select 相似的功能。唯一的区别就是 flatSelect 方法可以返回多条记录,它通过一个 Collector[OUT]类型的参数来将要输出的数据传递到下游。
- 超时事件的处理
通过 within 方法,我们的 parttern 规则将匹配的事件限定在一定的窗口范围内。当有超过窗口时间之后到达的 event,我们可以通过在 select 或 flatSelect 实现PatternTimeoutFunction 和 PatternFlatTimeoutFunction 来处理这种情况
val patternStream: PatternStream[Event] = CEP.pattern(input, pattern)
val outputTag = OutputTag[String]("side-output")
val result: SingleOutputStreamOperator[ComplexEvent] = patternStream.select
(outputTag){
(pattern: Map[String, Iterable[Event]], timestamp: Long) => TimeoutEvent()} {
pattern: Map[String, Iterable[Event]] => ComplexEvent()
}
val timeoutResult: DataStream = result.getSideOutput(outputTag)
3、CEP实战
import java.util
import org.apache.flink.cep.PatternSelectFunction
import org.apache.flink.cep.scala.CEP
import org.apache.flink.cep.scala.pattern.Pattern
import org.apache.flink.streaming.api.TimeCharacteristic
import org.apache.flink.streaming.api.scala.StreamExecutionEnvironment
import org.apache.flink.streaming.api.windowing.time.Time
import org.apache.flink.streaming.api.scala._
object FlinkCep2LoginFailEventOps {
def main(args: Array[String]): Unit = {
val env = StreamExecutionEnvironment.getExecutionEnvironment
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime)
env.setParallelism(1)
//事件流
val loginStream = env.fromCollection(List(
LoginEvent("1", "192.168.0.1", "fail", "1558430842"),
LoginEvent("1", "192.168.0.2", "fail", "1558430843"),
LoginEvent("1", "192.168.0.3", "fail", "1558430844"),
LoginEvent("2", "192.168.10.10", "success", "1558430845"))
).assignAscendingTimestamps(_.eventTime.toLong)
//定义规则 10s内,连续两次登录失败
val pattern = Pattern.begin[LoginEvent]("begin")
.where(loginEvent => loginEvent.eventType == "fail")
.next("next")
.where(loginEvent => loginEvent.eventType == "fail")
.within(Time.seconds(10))
//使用规则去检验数据
val patternStream: PatternStream[LoginEvent] = CEP.pattern(loginStream, pattern)
//获取匹配上的数据,并生成相关的警告,此时就需要使用select来对流进行选择
patternStream.select(new MySelectPatternFunction).print()
env.execute(s"${FlinkCep2LoginFailEventOps.getClass.getSimpleName}")
}
class MySelectPatternFunction extends PatternSelectFunction[LoginEvent, Warning] {
override def select(pp: util.Map[String, util.List[LoginEvent]]): Warning = {
val firstEvent = pp.getOrDefault("begin", null).get(0)
val secondEvent = pp.getOrDefault("next", null).get(0)
val userId = firstEvent.userId
val firstEventTime = firstEvent.eventTime
val secondEventTime = secondEvent.eventTime
Warning(userId, firstEventTime, secondEventTime, msg = "连续两次登录失败,怀疑你有邪恶的行为,关进小黑屋~")
}
}
}
case class LoginEvent(userId: String, ip: String, eventType: String, eventTime: String)
//最后生成的警告信息
case class Warning(userId: String, firstEventTime: String, secondEventTime: String, msg: String)
(三)、Flink任务性能优化
1、Operator Chain
为了更高效地分布式执行,Flink 会尽可能地将 operator 的 subtask 链接(chain)在一起形成 task,每个 task 在一个线程中执行。将 operators 链接成 task 是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
Flink 会在生成 JobGraph 阶段,将代码中可以优化的算子优化成一个算子链(Operator Chains)以放到一个 task(一个线程)中执行,以减少线程之间的切换和缓冲的开销,提高整体的吞吐量和延迟。下面以官网中的例子进行说明。

上图中,source、map、[keyBy|window|apply]、sink 算子的并行度分别是 2、2、2、1,经过 Flink 优化后,source 和 map 算子组成一个算子链,作为一个 task 运行在一个线程上,其简图如图中 condensed view 所示,并行图如 parallelized view 所示。算子之间是否可以组成一个Operator Chains,看是否满足以下条件:
- 上下游算子的并行度一致;
- 上下游节点都在同一个slot group 中;
- 下游节点的chain策略为ALWAYS;
- 上游节点的chain策略为ALWAYS或HEAD;
- 两个节点间数据分区方式是forward;
- 用户没有禁用chain。
2、Slot Sharing
Slot Sharing 是指,来自同一个 Job 且拥有相同 slotSharingGroup(默认:default)名称的不同 Task 的 SubTask 之间可以共享一个 Slot,这使得一个 Slot 有机会持有 Job 的一整条 Pipeline,这也是上文提到的在默认 slotSharing 的条件下 Job 启动所需的 Slot 数和 Job 中 Operator 的最大 parallelism 相等的原因。通过 Slot Sharing 机制可以更进一步提高 Job 运行性能,在 Slot 数不变的情况下增加了 Operator 可设置的最大的并行度,让类似 window 这种消耗资源的 Task 以最大的并行度分布在不同 TM 上,同时像 map、filter 这种较简单的操作也不会独占 Slot 资源,降低资源浪费的可能性。

图中包含 source-map[6 parallelism]、keyBy/window/apply[6 parallelism]、sink[1 parallelism] 三种 Task,总计占用了 6 个 Slot;由左向右开始第一个 slot 内部运行着 3 个 SubTask[3 Thread],持有 Job 的一条完整 pipeline;剩下 5 个 Slot 内分别运行着 2 个 SubTask[2 Thread],数据最终通过网络传递给 Sink 完成数据处理。
3、Flink 异步 IO
流式计算中,常常需要与外部系统进行交互,而往往一次连接中你那个获取连接等待通信的耗时会占比较高。下图是两种方式对比示例: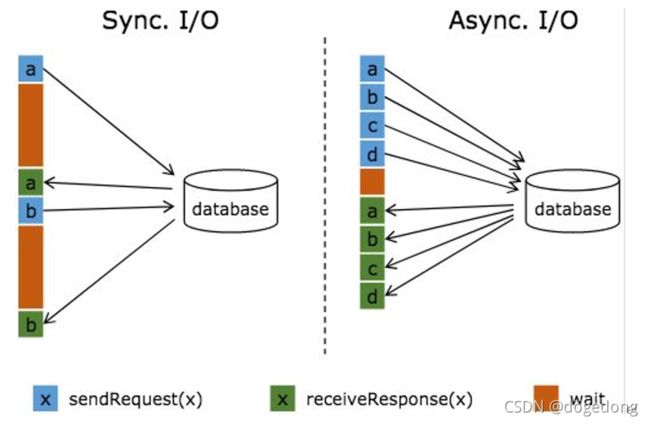
图中棕色的长条表示等待时间,可以发现网络等待时间极大地阻碍了吞吐和延迟。为了解决同步访问的问题,异步模式可以并发地处理多个请求和回复。也就是说,你可以连续地向数据库发送用户 a、b、c 等的请求,与此同时,哪个请求的回复先返回了就处理哪个回复,从而连续的请求之间不需要阻塞等待,如上图右边所示。这也正是 Async I/O 的实现原理。
4、Checkpoint 优化
Flink 实现了一套强大的 checkpoint 机制,使它在获取高吞吐量性能的同时,也能保证 Exactly Once 级别的快速恢复。
首先提升各节点 checkpoint 的性能考虑的就是存储引擎的执行效率。Flink官方支持的三种 checkpoint state 存储方案中,Memory 仅用于调试级别,无法做故障后的数据恢复。其次还有 fileSystem与 Rocksdb,当所做 Checkpoint 的数据大小较大时,可以考虑采用 Rocksdb 来作为 checkpoint 的存储以提升效率。
其次的思路是资源设置,我们都知道 checkpoint 机制是在每个 task 上都会进行,那么当总的状态数据大小不变的情况下,如何分配减少单个 task 所分的 checkpoint 数据变成了提升 checkpoint 执行效率的关键。
最后,增量快照。非增量快照下,每次 checkpoint 都包含了作业所有状态数据。而大部分场景下,前后 checkpoint 里,数据发生变更的部分相对很少,所以设置增量 checkpoint,仅会对上次 checkpoint 和本次 checkpoint 之间状态的差异进行存储计算,减少了 checkpoint 的耗时。
使用 checkpoint 的使用建议
虽然理论上 Flink 支持很短的 checkpoint 间隔,但是在实际生产中,过短的间隔对于底层分布式文件系统而言,会带来很大的压力。另一方面,由于检查点的语义,所以实际上 Flink 作业处理 record 与执行 checkpoint 存在互斥锁,过于频繁的 checkpoint,可能会影响整体的性能。当然,这个建议的出发点是底层分布式文件系统的压力考虑。
合理设置超时时间
默认的超时时间是 10min,如果 state 规模大,则需要合理配置。最坏情况是分布式地创建速度大于单点(job master 端)的删除速度,导致整体存储集群可用空间压力较大。建议当检查点频繁因为超时而失败时,增大超时时间。
//设置超时时间,超时时间是说,这个检查点设置了,但是过去500ms还没有完成就认为这个检查点超时了,然后把这个检查点终止,也就是不再使用这个检查点了
env.getCheckpointConfig().setCheckpointTimeout(500);
5、资源配置
- 并行度(parallelism):保证足够的并行度,并行度也不是越大越好,太多会加重数据在多个solt/task manager之间数据传输压力,包括序列化和反序列化带来的压力。
- CPU:CPU资源是task manager上的solt共享的,注意监控CPU的使用。
- 内存:内存是分solt隔离使用的,注意存储大state的时候,内存要足够。
- 网络:大数据处理,flink节点之间数据传输会很多,服务器网卡尽量使用万兆网卡。
6、 总结
Operator Chain 是将多个 Operator 链接在一起放置在一个 Task 中,只针对 Operator。Slot Sharing 是在一个 Slot 中执行多个 Task,针对的是 Operator Chain 之后的 Task。这两种优化都充分利用了计算资源,减少了不必要的开销,提升了 Job 的运行性能。异步IO能解决需要高效访问其他系统的问题,提升任务执行的性能。Checkpoint优化是集群配置上的优化,提升集群本身的处理能力。