论文浅尝 | 利用常识知识图谱进行多跳推理的语言生成方法
笔记整理 | 朱珈徵,天津大学硕士。

链接:https://arxiv.org/pdf/2009.11692.pdf
动机
尽管生成式预训练语言模型在一系列文本生成任务上取得了成功,但在生成过程中需要对基础常识知识进行推理的情况下,它们仍然会受到影响。现有的方法将常识性知识整合到预训练生成式语言模型中,只是通过对个体知识三元组进行后训练来转移关系知识,而忽略了知识图谱中的丰富联系。作者认为利用知识图的结构信息和语义信息有助于常识感知文本的生成。在本文中提出了基于多跳推理流的生成(Generation with Multi-Hop Reasoning Flow, GRF),使预训练模型能够对从外部常识知识图中提取的多关系路径进行动态多跳推理。实验表明,本文模型在需要推理常识知识的三个文本生成任务上优于现有的基线。文中还演示了动态多跳推理模块的有效性,并通过该模型推断出推理路径,为生成提供了理论依据。
亮点
本文的亮点主要包括:
(1)提出了一种新的生成模型GRF,该模型在文本生成中利用外部结构常识知识进行显式常识推理;
(2)提出了一个动态多跳推理模块,该模块沿关系路径聚集证据,以生成一些关键概念;
(3) 在三种常识感知文本生成任务上进行了大量的实验,结果表明我们的模型优于各种基线。此外还将该模型所推断的推理路径可视化,以证明多跳推理模块的有效性。
概念及模型
GRF以输入文本中的概念作为常识知识基础扩展出来的子图为基础,首先用组合操作对多关系图进行编码,以获得概念和关系的图形感知表示。然后,多跳推理模块通过沿多个关系路径聚合三重证据进行动态推理,生成上下文下的显著概念。最后,生成分布结合了从知识图中复制概念的概率和通过门控制从标准词汇表中选择单词的概率。
GRF具体由四部分构成:
使用预训练transformer的上下文建模。
对具有非参数操作的多关系图进行编码,以组合关系和概念。
将来自源概念的证据沿着结构路径聚合到所有节点的多跳推理模块。
门控生成分布。
模型整体框架如下:

静态多关系图编码
使用非参数合成操作将节点嵌入和关系嵌入结合起来。具体来说,给定输入图G = (V,E)和有LG个层GCN,对于每个节点v,我们通过聚合由节点u和连接关系r组成的本地邻居N(v)的信息来更新嵌入在第l+1层的节点;关系嵌入也通过另一个线性变换进行更新:
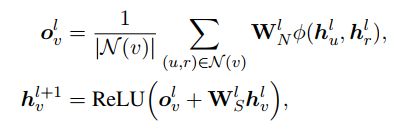
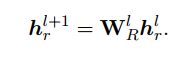
使用预训练模型的上下文建模
采用GPT-2模型,一个预训练的多层转换器解码器来建模文本序列的上下文依赖关系。模型的输入是源序列和目标序列的连接:

动态多跳推理流程
为了在生成过程中对图结构进行显式推理,设计了一个动态推理模块,该模块利用知识图的结构模式和上下文信息在每个解码步骤中沿关系路径传播证据。
具体来说,该模块通过多次更新外部节点与其访问邻居的得分来广播G上的信息,直到G上的所有节点都被访问为止。最初,与Cx中概念对应的节点被赋予1分,而其他未访问的节点被赋予0分。对于未访问节点v,其节点评分ns(v)是通过聚集证据来计算的Nin(v),表示访问过的节点u及其边r直接连接v的集合:

R(u,r,v)是三元组相关性,反映三元组(u,r,v) 在当前上下文下给出的证据的相关性。计算三元组相关性如下:
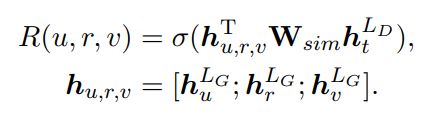
门控生成分布
最后的生成分布用一个软的门概率gt表示是否在生成中复制某个概念,以控制与复制机制类似的两个分布的权重。

最终的输出分布是两个分布分别以gt和1-gt加权后的线性组合。

理论分析
实验
作者在三个常识感知的文本生成任务上进行了实验,包括故事结尾生成(SEG)、诱导性自然语言生成(Abductive NLG)和解释生成(Explanation Generation)。评价指标采用BLEU-4, CIDEr,ROUGE-L和 METEOR来评估诱导性自然语言生成和解释生成任务,BLEU-1/2评估结尾生成任务。
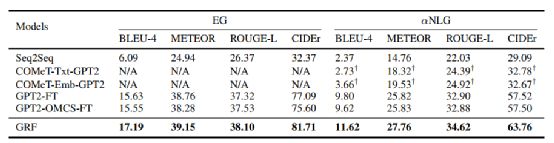
从结果可以看出:第一、模型在所有评价指标上都优于所有使用预训练语言模型或加入外部常识性知识的基线,说明在常识性知识图中加入丰富的结构信息可以提高总体生成质量;
第二、在单纯的常识知识来源上进行后训练会降低这两项任务的表现。这可能是由于经过后训练的三元组语料库不能为模型提供丰富的语义来概括强调推理和解释的任务。
对于故事结尾的生成,文中也给出了评价结果。模型优于BLEU中的所有基线和不同的度量。作者还发现,对外部常识数据进行后训练,提高了预训练语言模型的生成多样性,作者推测可能是由于在常识数据上进行后训练能够使模型生成与故事背景相关概念,提高了文本的多样性
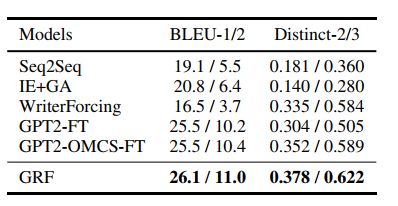
此外还进行了消融实验,以验证不同模型成分的效果。如表所示,所有的组成部分都有助于最终的性能。删除动态推理模块(w/o DMRF)导致性能下降最大,说明动态多跳推理在该任务中起主要作用。去掉图表示模块(w/o SMGE)也会降低性能,因为它用关系信息对图结构进行编码,有利于概念选择。我们还展示了使用均值聚合器的推理模块的结果,观察到比起最大值聚合器有一些性能的下降。

总结
作者提出了基于多跳推理流的生成方法,在文本生成过程中对结构化常识知识进行推理。该方法利用外部知识库的结构信息和语义信息,对关系路径进行动态多跳推理。文中进行了大量的实验,并通过实验证明,该方法在三个文本生成任务上优于现有的将常识知识集成到预先训练的语言模型中的方法。作者还用为生成的结果提供基本原理的推断推理路径来演示此方法的可解释性。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。