大数据笔记--SparkSQL(第一篇)
目录
一、Spark Sql
1、概述
2、由来
3、Spark SQL特点
4、为什么SparkSQL的性能会的得到这么大的提升?
Ⅰ、内存列存储
二、SparkSql入门
1、概述
2、创建DataFrame对象
三、SparkSql基础语法上
1、通过方法来使用
四、SparkSql基础语法下
1、通过sql语句来调用
五、SparkSql API
一、Spark Sql
1、概述
Spark为了结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame(数据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
2、由来
SparkSQL的前身是Shark。在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,是当时唯一运行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率较低。
后来,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
1)MapR的Drill
2)Cloudera的Impala
3)Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它基于Hive实施了一些改进,比如引入缓存管理,改进和优化执行器等,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。

但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于hive的太多依赖(如采用hive的语法解析器、查询优化器等等),制约了Spark的One Stack rule them all的既定方针,制约了spark各个组件的相互集成,所以提出了sparkSQL项目。

SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码。
由于摆脱了对hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句话。
3、Spark SQL特点
1)引入了新的RDD类型SchemaRDD,可以像传统数据库定义表一样来定义SchemaRDD
2)在应用程序中可以混合使用不同来源的数据,如可以将来自HiveQL的数据和来自SQL的数据进行Join操作。
3)内嵌了查询优化框架,在把SQL解析成逻辑执行计划之后,最后变成RDD的计算
4、为什么SparkSQL的性能会的得到这么大的提升?
主要SparkSql在下面几点做了优化:
Ⅰ、内存列存储
列存储的优势:
①、海量数据查询时,不存在冗余列问题。如果是基于行存储,查询时会产生冗余列,消除冗余列一般在内存中进行的。或者基于行存储的查询,实现物化索引(建立B-tree B+tree),但是物化索引也是需要耗费cpu的
②、基于列存储,每一列数据类型都是同质的,好处一可以避免数据在内存中类型的频繁转换。好处二可以采用更高效的压缩算法,比如增量压缩算法,二进制压缩算法。性别:男 女 男 女 0101
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储,如下图所示。

该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
对于内存列存储来说,将所有原生数据类型的列采用原生数组来存储,将Hive支持的复杂数据类型(如array、map等)先序化后并接成一个字节数组来存储。
此外,基于列存储,每列数据都是同质的,所以可以降低数据类型转换的CPU消耗。此外,可以采用高效的压缩算法来压缩,是的数据更少。比如针对二元数据列,可以用字节编码压缩来实现(010101)
这样,每个列创建一个JVM对象,从而可以快速的GC和紧凑的数据存储;额外的,还可以使用低廉CPU开销的高效压缩方法(如字典编码、行长度编码等压缩方法)降低内存开销;更有趣的是,对于分析查询中频繁使用的聚合特定列,性能会得到很大的提高,原因就是这些列的数据放在一起,更容易读入内存进行计算。

二、SparkSql入门
1、概述
SparkSql将RDD封装成一个DataFrame对象,这个对象类似于关系型数据库中的表。
2、创建DataFrame对象
DataFrame就相当于数据库的一张表。它是个只读的表,不能在运算过程再往里加元素。
RDD.toDF(“列名”)
例一:
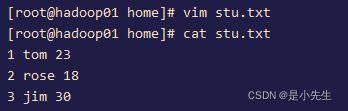
val r1=sc.makeRDD(List((1,"tom"),(2,"rose"),(3,"jim"),(4,"jary")),2)
例二:
val r2=sc.textFile("file:///home/stu.txt").map{_.split(" ")}.map{arr=>(arr(0).toInt,arr(1),arr(2).toInt)} val df2=r2.toDF("id","name","age") df2.show
例三:json
文件people.json:
{"id":1, "name":"leo", "age":18} {"id":2, "name":"jack", "age":19} {"id":3, "name":"marry", "age":17}代码:
import org.apache.spark.sql.SQLContext val sqc=new SQLContext(sc) val tb4=sqc.read.json("/home/software/people.json") tb4.show结果:
例四:parquet文件
1. 什么是Parquet数据格式?
Parquet是一种列式存储格式,可以被多种查询引擎支持(Hive、Impala、Drill等),并且它是语言和平台无关的。
2. Parquet文件下载后是否可以直接读取和修改呢?
Parquet文件是以二进制方式存储的,是不可以直接读取和修改的。Parquet文件是自解析的,文件中包括该文件的数据和元数据。
3. 列式存储和行式存储相比有哪些优势呢?
可以只读取需要的数据,降低IO数据量;
压缩编码可以降低磁盘存储空间。由于同一列的数据类型是一样的,可以使用更高效的压缩编码进一步节约存储空间。
代码:
val tb5=sqc.read.parquet("/home/software/users.parquet") tb5.show结果:
例五:jdbc读取
实现步骤:
1)将mysql 的驱动jar上传到spark的jars目录下
cd /home/software/apache-hive-1.2.0-bin/lib
cp mysql-connector-java-5.1.38-bin.jar /home/software/spark-2.0.1-bin-hadoop2.7/jars/
2)重启spark服务
cd /home/software/spark-2.0.1-bin-hadoop2.7/bin
sh spark-shell --master=local
3)进入spark客户端
4)执行代码,比如在Mysql数据库下,有一个test库,在test库下有一张表为tabx
执行代码:
import org.apache.spark.sql.SQLContext val sqc = new SQLContext(sc); val prop = new java.util.Properties prop.put("user","root") prop.put("password","root") val tabx=sqc.read.jdbc("jdbc:mysql://hadoop01:3306/test","tb1",prop) tabx.show注:如果报权限不足,则进入mysql,执行:
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
然后执行:
flush privileges;




三、SparkSql基础语法上
1、通过方法来使用
①、查询
df.select("id","name").show();
②、带条件的查询
df.select($"id",$"name").where($"name" === "bbb").show()

③、排序查询
orderBy/sort($"列名") 升序排列
orderBy/sort($"列名".desc) 降序排列
orderBy/sort($"列1" , $"列2".desc) 按两列排序

df.select($"id",$"name").orderBy($"name".desc).show
df.select($"id",$"name").sort($"name".desc).show
tabx.select($"id",$"name").sort($"id",$"name".desc).show

④、分组查询
groupBy("列名", ...).max(列名) 求最大值
groupBy("列名", ...).min(列名) 求最小值
groupBy("列名", ...).avg(列名) 求平均值
groupBy("列名", ...).sum(列名) 求和

groupBy("列名", ...).count() 求个数
groupBy("列名", ...).agg 可以将多个方法进行聚合

val rdd = sc.makeRDD(List((1,"a","bj",100),(2,"b","sh",80),(3,"c","gz",50),(4,"d","bj",45))); val df = rdd.toDF("id","name","addr","score"); df.groupBy("addr").count().show() df.groupBy("addr").agg(max($"score"), min($"score"), count($"*")).show
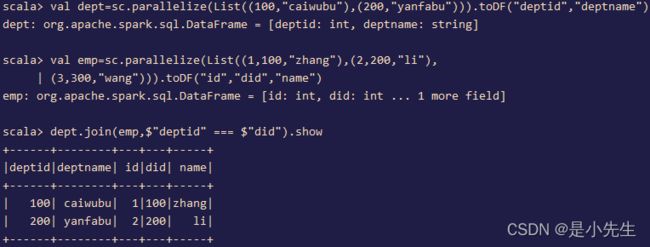
⑤、连接查询
val dept=sc.parallelize(List((100,"caiwubu"),(200,"yanfabu"))).toDF("deptid","deptname") val emp=sc.parallelize(List((1,100,"zhang"),(2,200,"li"),(3,300,"wang"))).toDF("id","did","name") dept.join(emp,$"deptid" === $"did").show dept.join(emp,$"deptid" === $"did","left").show
左向外联接的结果集包括 LEFT OUTER子句中指定的左表的所有行,而不仅仅是联接列所匹配的行。如果左表的某行在右表中没有匹配行,则在相关联的结果集行中右表的所有选择列表列均为空值。
dept.join(emp,$"deptid" === $"did","right").show
"left" ,"rigtht" ,"inner","full"
⑥、执行运算
val df = sc.makeRDD(List(1,2,3,4,5)).toDF("num");
df.select($"num" * 100).show
⑦、使用列表
val df = sc.makeRDD(List(("zhang",Array("bj","sh")),("li",Array("sz","gz")))).toDF("name","addrs")
df.selectExpr("name","addrs[0]").show
⑧、使用结构体
{"name":"陈晨","address":{"city":"西安","street":"南二环甲字1号"}}
{"name":"娜娜","address":{"city":"西安","street":"南二环甲字2号"}}
val df = sqlContext.read.json("file:///home/data/users.json")
dfs.select("name","address.street").show
⑨、其他
df.count//获取记录总数
val row = df.first()//获取第一条记录
val take=df.take(2) //获取前n条记录
val value = row.getString(1)//获取该行指定列的值
df.collect //获取当前df对象中的所有数据为一个Array 其实就是调用了df对象对应的底层的rdd的collect方法
四、SparkSql基础语法下
1、通过sql语句来调用
①、创建表
df.registerTempTable("tabName")
②、查询
val sqc = new org.apache.spark.sql.SQLContext(sc);
val df = sc.makeRDD(List((1,"a","bj"),(2,"b","sh"),(3,"c","gz"),(4,"d","bj"),(5,"e","gz"))).toDF("id","name","addr");
df.registerTempTable("stu");
sqc.sql("select * from stu").show()

③、带条件查询
val df = sc.makeRDD(List((1,"a","bj"),(2,"b","sh"),(3,"c","gz"),(4,"d","bj"),(5,"e","gz"))).toDF("id","name","addr");
df.registerTempTable("stu");
sqc.sql("select * from stu where addr = 'bj'").show()

④、排序查询
sqlContext.sql("select * from stu order by addr").show()
sqlContext.sql("select * from stu order by addr desc").show()
⑤、分组查询
sqlContext.sql("select addr,count(*) from stu group by addr").show()
⑥、连接查询
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val dept=sc.parallelize(List((100,"财务部"),(200,"研发部"))).toDF("deptid","deptname")
val emp=sc.parallelize(List((1,100,"张财务"),(2,100,"李会计"),(3,300,"王艳发"))).toDF("id","did","name")
dept.registerTempTable("deptTab");
emp.registerTempTable("empTab");
sqlContext.sql("select deptname,name from dept inner join emp on dept.deptid = emp.did").show()
⑦、执行运算
val sqlContext = new org.apache.spark.sql.SQLContext(sc);
val df = sc.makeRDD(List(1,2,3,4,5)).toDF("num");
df.registerTempTable("tabx")
sqlContext.sql("select num * 100 from tabx").show();
⑧、分页查询
sqlContext.sql("select * from tabx limit 3").show();
⑨、查看表
sqlContext.sql("show tables").show
⑩、类似hive的操作
hdata.txt:
1|2
2|3
3|4
val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
hiveContext.sql("create table if not exists zzz (key int, value string) row format delimited fields terminated by '|'")
hiveContext.sql("load data local inpath 'file:///home/data/hdata.txt' into table zzz")
hiveContext.sql("select key,value from zzz").show
package cn.yang.sql
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.sql.SQLContext
object Driver {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("sql")
val sc=new SparkContext(conf)
//创建sparkSql的上下文对象,用于创建DataFrame,并提供sql的方式来操作DataFrame
val sqc=new SQLContext(sc)
val r1=sc.makeRDD(List((1,"tom",23),(2,"rose",18),(3,"jim",25),(4,"jary",20)))
//将RDD转变为DataFrame
//val df1=sqc.createDataFrame(r1).toDF("id","name","age")
import sqc.implicits._
val df1=r1.toDF("id","name","age")
val result=df1.select("id","name")
df1.registerTempTable("tb1")
val result01=sqc.sql("select * from tb1 where age>20")
//DataFrame的show方法将表数据打印到控制台,最多显示20条数据
result.show
result01.show
//为了能够将查询的表数据进行存储,需要将DataFrame转回RDD
val resultRDD=result.toJavaRDD
//结果存储
//resultRDD.saveAsTextFile("hdfs://hadoop01:9000/sql-result")
}
}五、SparkSql API
步骤:
打开本地IDE,创建一个scala工程
导入spark相关依赖包
编写代码
package cn.yang.sqlapi import org.apache.spark.SparkConf import org.apache.spark.SparkContext import org.apache.spark.sql.SQLContext object Driver{ def main(args: Array[String]): Unit = { val conf=new SparkConf().setMaster("spark://hadoop01:7077").setAppName("sqlApi"); val sc=new SparkContext(conf) val sqlContext=new SQLContext(sc) val rdd=sc.makeRDD(List((1,"zhang"),(2,"li"),(3,"wang"))) import sqlContext.implicits._ val df=rdd.toDF("id","name") df.registerTempTable("tabx") val df2=sqlContext.sql("select * from tabx order by name"); val rdd2=df2.toJavaRDD; //将结果输出到linux的本地目录下,当然,也可以输出到HDFS上 rdd2.saveAsTextFile("file:///home/software/result"); } }打jar包,并上传到linux虚拟机上
在spark的bin目录下
执行:sh spark-submit --class cn.tedu.sparksql.Demo01 ./sqlDemo01.jar
最后检验